
0x00 前言
本题目来源于对openwrt项目源码魔改。基于实战中的场景,在题目中设置了三种相对固定且常见的漏洞模式,希望选手们在对固定漏洞模式理解的基础上,可以利用静态分析工具辅助进行分析,探索各种漏洞分析工具与人工分析相结合的漏洞挖掘模式,减少一定量的重复人工审计。
静态分析工具都有其自身的缺陷,分析的结果很难做到尽善尽美。因此站在一位漏洞挖掘工程师的角度,我设置本题的目标是探索如何合理的使用静态分析工具,并最大程度的利用这种自动化的方式帮助我们减少人工分析的工作。
这里的题解主要使用我们自研的二进制静态分析工具——破壳平台的交互式查询来辅助我们进行分析,大致来说有以下思路:
- 根据漏洞模式的某些参数特征进行匹配
- 定义source点和sink点进行污点追踪
- 根据漏洞模式上下文特征来匹配漏洞
我们将会介绍这三种思路来进行查询解题,具体漏洞的答案和查询规则在文末可见。
0x01 根据参数特征查询
根据参数特征查询适用于过滤一些常见的危险函数的危险操作。
1.1 针对strcat函数
例如如果strcat的二个参数是一个常量字符串的话是很难有溢出的,即使有溢出也难以造成很大的危害。故此这种情况我们一般不需重点关注。
在本次datacon赛题二中,我们对strcat进行查询并设置其第二个参数是一个变量的情况。这里我们的查询规则如下,查找类型为变量(identifier),callee的筛选是为了筛选出调用这个变量的函数要是strcat函数,最后index指定了这个变量是strcat的第二个参数(下标从0开始),as taintPropagationPath RETURN taintPropagationPath 是为了前端将结果显示的更好看一些。
MATCH (n:identifier) WHERE n.callee="strcat" AND n.index=1 WITH [n] AS taintPropagationPath
RETURN taintPropagationPath
查询结果如下,可以看到符合的结果只有两条。因为查询到的结果并不多,所以可以进行一下人工验证。验证后发现恰好是我们题目设置的答案odhcpd:0x000036A9 odhcpd:0x000035F9
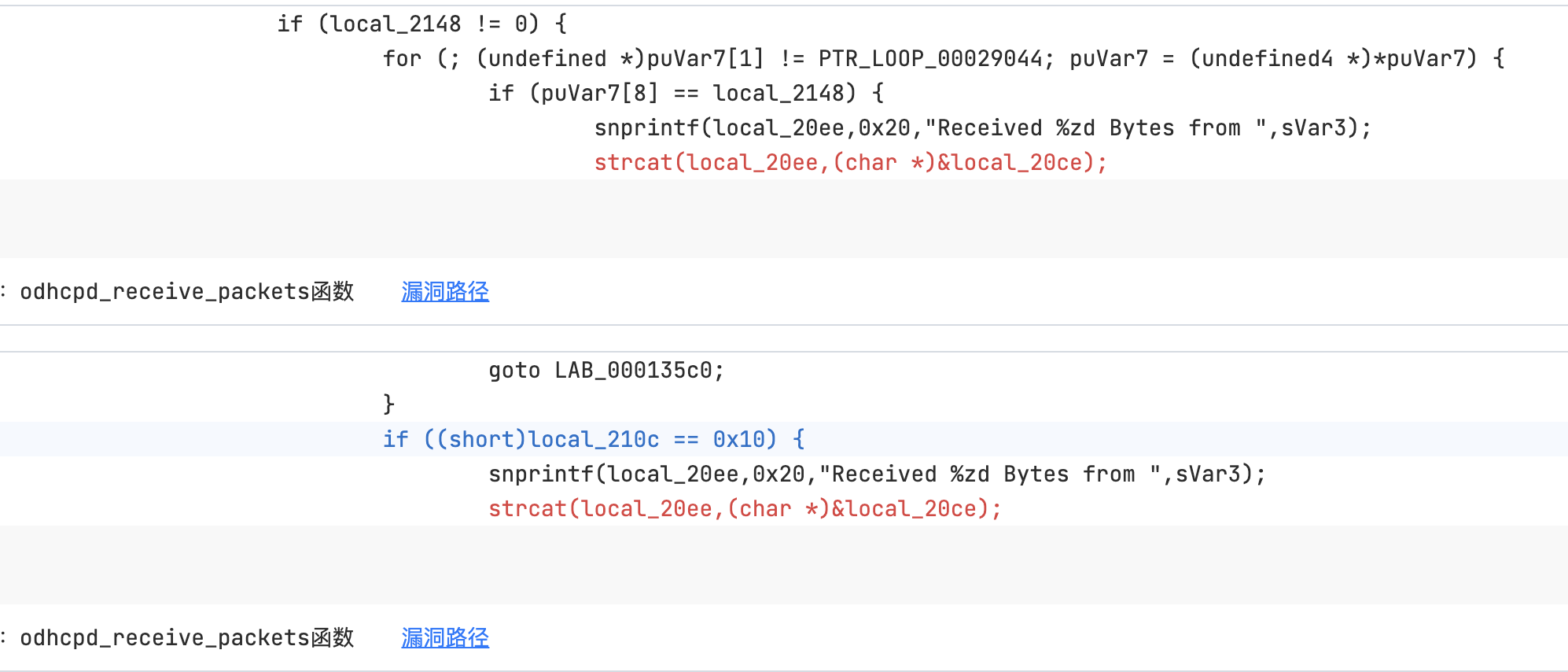
依据这种思路我们可以查询到 漏洞3,漏洞4
总结
与之类似的情况还有strcpy函数,我们依然可以依照上面的原则进行编写规则进行查询。
在现实情况中,如果我们上传了整个固件可以如此查询一下他system和popen的调用情况,那么如果他执行的是一个常量字符串那么肯定不可能是一个命令注入漏洞。因此我们可以同样对他system和popen的第一个参数类型进行限制,帮助我们初步筛选一下目标,减轻人工逆向的工作量。
1.2 针对memmove函数
首先我们来看下memmove函数的函数定义,第一个参数是dst,第二个参数是src,第三个参数是len
void *
memmove(void *dst, const void *src, size_t len);
通常memmove安全的使用方法有以下两种
调用memmove函数的时候第三个参数是一个固定的值
memmove(dest, src, sizeof(dest));memmove的dest大小是根据第三个参数的大小申请出来的
dest = malloc(size); memmove(dst, src, size);
我们针对这两种情况进行排除,编写查询命令。其中not (m)-[:dfg]-(n)即是现在第一个参数跟第三个参数之间不存在直接的数据流关系
MATCH (n:identifier{callee:"memmove", index:0}), (m:identifier{callee:"memmove", index:2})
WHERE n.function=m.function AND m.line=n.line
AND not (m)-[:dfg]-(n) WITH [m] AS taintPropagationPath
RETURN taintPropagationPath
下图即是在lldpd中查询到的结果,即两个对应的答案lldpd:0x0804F6EC,lldpd:0x0804F848
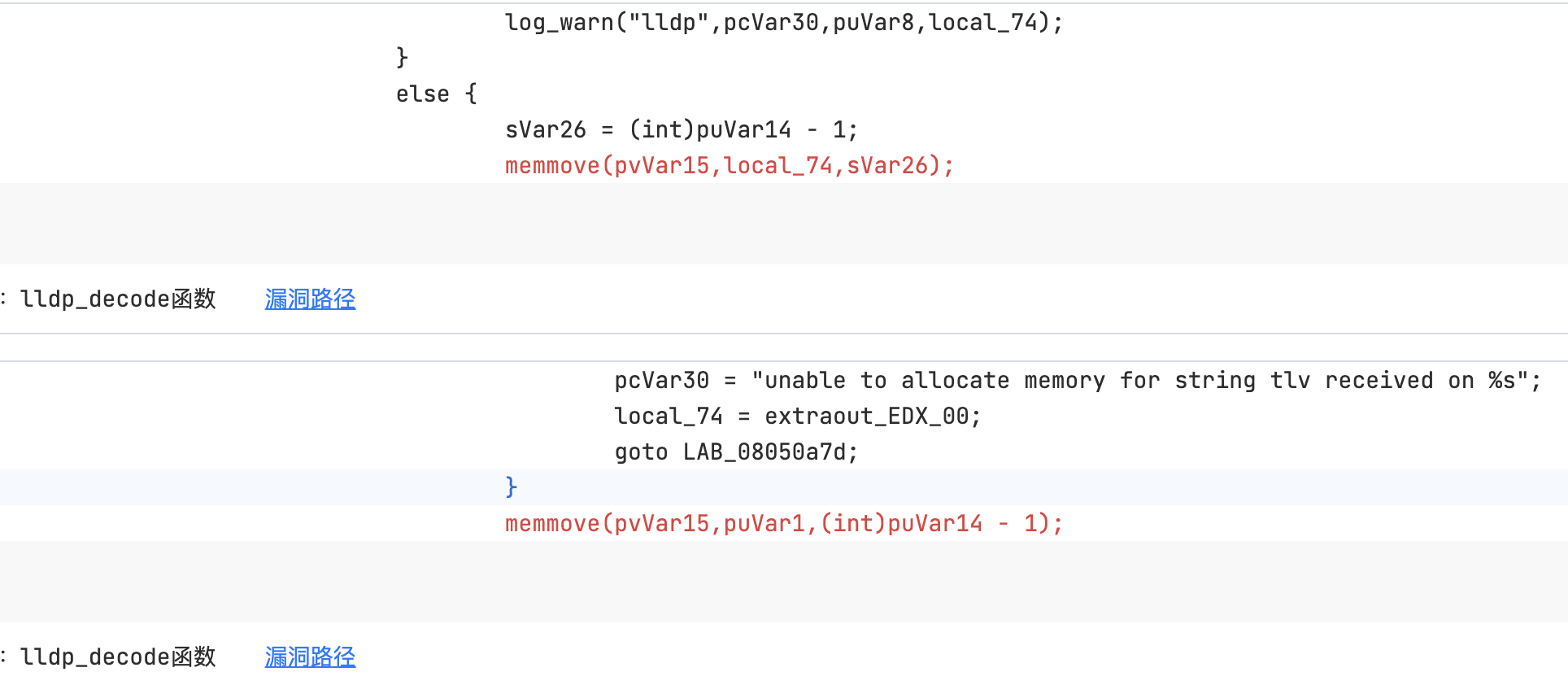
依据此思路我们在全部的二进制中进行搜索到接近20处疑似位置。得益于破壳平台可返回的疑似点的反编译代码我们可以人工快速判断一下,如果仍有比较多的不确定选项我们可以考虑针对这些特定的memmove使用污点查询来进行二次筛选。
最终我们可以查询到漏洞5 漏洞6 漏洞7 漏洞9 漏洞10 漏洞11
总结
其实如签到题的格式化字符串,其他危险函数如snprintf等都可以用这种方法查询,且也都有不错的过滤效果
但在更多的二进制一起查的时候这种查询方法还是略显粗糙,如果出现的结果仍然很多,我们可以结合污点查询或是我们人工分析出的再编写规则进行过滤。
0x02 使用污点追踪
污点追踪可以让我们聚焦数据流传播到的危险函数。
签到题,题目一,题目二所包含的漏洞类型其实都可以使用污点查询的方式来进行查询与之前提到的查询方法进行交叉验证。
2.1 使用默认source和sink
针对ustpd这个目标,我们使用下面默认的source到sink的污点查询进行查找,也就是平台定义的is_source和is_sink。
MATCH (n:identifier) WHERE n.is_source=1 WITH collect(id(n)) AS sourceSet
MATCH (m:identifier{index:0}) WHERE m.is_sink=1 WITH sourceSet, collect(id(m)) AS sinkSet
CALL VQL.taintPropagation(sourceSet, sinkSet, 1) YIELD taintPropagationPath
RETURN taintPropagationPath ORDER BY size(taintPropagationPath)
如下,我们成功查询到了签到题的格式化字符串漏洞ustpd:0x0804F571,其数据流调用也很清晰。

在赛题中其实使用标准库函数作为source点的程序比较少,因此基本没有什么误报。依据此思路我们可以查询到 漏洞1 漏洞2
不过显然,这比我们预期当中要查找到的漏洞点要少,我们还需要进一步对每个程序可能的source点进行分析,再对其进行自定义source点的污点追踪。有一些程序自定义的函数可能反编译工具无法准确识别他们的参数,我们也可以通过在ghidra中进行重定义后导出gzf文件,再上传到破壳平台上进行分析。
总结
对于一些source和sink非常明确的程序,使用这种查询方法能帮助我们快速锁定一些值得审视的攻击面且能帮助我们排除调大量无威胁的危险函数调用。
2.2 使用自定义的source,sink点
对于整数溢出漏洞,我们可以采用上面的根据参数特征来排除,或者匹配一些模式。这里笔者选择采用source点到malloc的方式来进行污点查询。因为发生整数溢出的前提也是malloc的size字段是我们可控的。
下面我们针对bfdd进行一个污点查询,其中source就设置为默认的is_source,sink设置为malloc函数。可以查询到这个漏洞即是我们设置的漏洞点bfdd:0x0805AD02
CALL VQL.getArgument("malloc",0) YIELD node WITH collect(id(node)) AS sinkset
MATCH (n:identifier) WHERE n.is_source=1 WITH collect(id(n)) AS sourceset,sinkset
CALL VQL.taintPropagation(sourceset,sinkset,3) YIELD taintPropagationPath
RETURN taintPropagationPath

当然很多情况下,程序由于间接的函数调用,或是程序存在身自定义的数据读取函数。这时使用默认的source点可能就会没有结果。这时我们需要对程序简单的进行分析,例如uhtppd其实是使用ustream_get_read_buf这个函数返回一个包含着网络通信数据的buffer地址。我们就可以将ustream_get_read_buf这个函数的返回值作为一个source点。
在题目中存在少量查到数据流但是并非是漏洞点的情况,但是数量不多且破壳平台返回了详细的污点追踪路径情况,因此很容易排除掉。最后依据此思路可以查询 漏洞8 漏洞12 漏洞13 漏洞14
在实际情况中如果我们遇到了某个数据流中有明显的check点导致后续的危险函数调用是安全的,我也可以通过写对应的规则去排除这种情况。
总结
适用于对程序进行了一定分析后,自动化寻找一些自己感兴趣的数据流。基于这些数据流进行分析,即使在没有符号执行的条件下也是可以大大减轻我们分析的工作量的。
0x03根据漏洞上下文查询
3.1 根据函数名判断函数功能
而对于类似于第三题这种实现为循环拷贝的转码函数,一种思路是我们可以从函数名的角度入手,利用下面的正则匹配匹配出具有类似编码功能的函数
MATCH (n:function)
WHERE n.name =~ ".*decode.*|.*hex.*"
RETURN n.name LIMIT 1000
以下四个漏洞均可使用这种思路查出
漏洞16 漏洞17 漏洞18 漏洞19
3.2 根据函数结构判断函数功能
寻找到一个成环的cfg(control flow graph),这部分成环的cfg一般都是一个循环操作。然后我们再观察该循环操作所对应的code_line(对应的反编译代码)中是否有我们关心的操作。如对于该函数传入的参数param_2的赋值操作。这个语句也可以考虑写的更精确一些,比如成环中间经过的所有basic_block都可以判断下其所属的code_line中有无我们关心的操作。
MATCH (m:code_line)<-[:own]-(n:basic_block)-[:cfg*1..3]->(n) WHERE m.name contains "*param_2" RETURN DISTINCT n.function LIMIT 1000
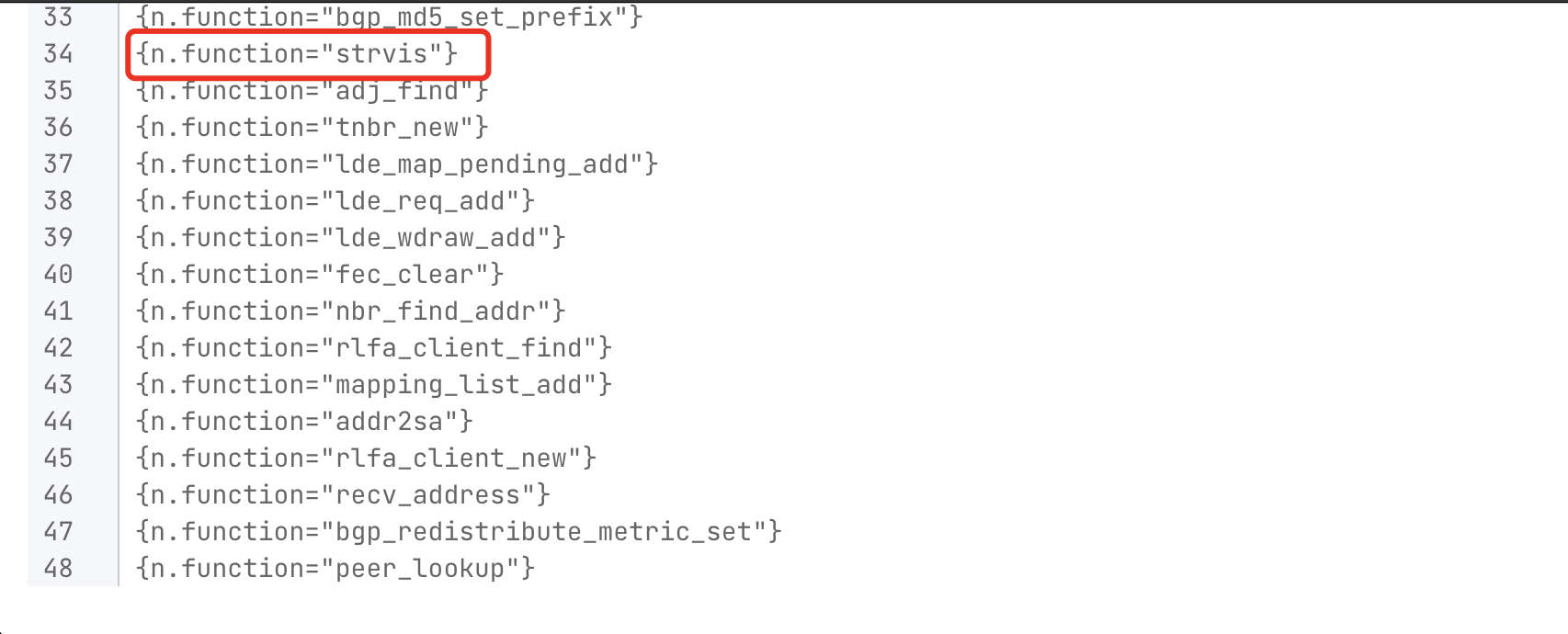
依据此思路可以查询到 漏洞20,但我们可以看到上面的查询方法查找到符合这种定义的函数有48个。这时候依据题目给出的提示寻找解码类型的函数。这里查询到的很多函数明显从名称上来看就可以判断不是我们需要关注的。故此我们可以通过再编写规则这些函数所在的文件,这个函数的名称,调用这个函数处的参数类型进行筛选。
总结
利用破壳平台还可以根据程序的一些basic_block的结构信息,ast的相关信息等进行查询。有一些通过参数类型,数据流不好识别的漏洞模式特征通过基本块或者语法树的特征可能更容易识别到。
0x04 写在最后
破壳平台在设计之初就一直在思考怎么让漏洞挖掘工程师和静态分析工具进行更高效的人机结合,我们考虑到常用的漏洞扫描工具很难将使用者对特定目标的经验加入进去,所以使用了查询交互式漏洞挖掘的思路,用户可以不断地编程来搜索漏洞、逼近漏洞,沉淀出针对某些漏洞的“专属”规则,甚至实现批量扫描;同时我们在日常工作中还深刻认识到漏洞挖掘有时候以团队的形式开展可以更高效,所以我们依托查询交互式漏洞挖掘这种模式,让用户和小伙伴们可以“开黑”挖洞。
当然,破壳平台目前还有很多不足,例如漏洞查询语言当前门槛和学习成本较高、UI还不够美观、平台容易崩等情况,在接收到反馈后我们也制定了开发计划,将一步步的完善;我们也计划放出更多的案例文档来帮助大家学习,向大家展示平台更多的用法,希望大家可以和破壳平台一起成长。
0x05 题目答案
漏洞1
从recvfrom函数接收到的数据直接作为printf函数的格式化字符串参数使用
cc = recvfrom(ufd.fd, &buf, sizeof(buf), 0, (struct sockaddr *)&sl, &salen);
if (cc < 0)
{
switch (errno)
{
case EINTR:
continue;
case EAGAIN:
return;
default:
cc = 0;
}
}
snprintf(log_buf, sizeof(log_buf), "recvfrom recved : %s", buf);
printf(log_buf);
简单送分格式化字符串,可以根据题目提示设置source点与sink点进行污点查询
MATCH (n:identifier) WHERE n.callee = "recvfrom" AND n.index=1 WITH collect(id(n)) AS sourceSet
MATCH (n:identifier) WHERE n.callee = "printf" AND n.index=0 WITH sourceSet, collect(id(n)) AS sinkSet
CALL VQL.taintPropagation(sourceSet, sinkSet, 3) YIELD taintPropagationPath
RETURN taintPropagationPath
ustpd:0x0804F571
漏洞2
漏洞附件为ustp
在ustp附件中的bridge_bpdu_rcv函数中,会调用如下代码,其中snprintf的第二个参数是可控的,这样把h拷贝到paket上时会造成缓冲区溢出,
char packet[1300];
snprintf(packet, l, "LLC header and the data %s", h);
LOG("header len %d, data %s", l, packet);
使用recvfrom函数的buffer参数作为source点,snprintf的size参数作为sink点进行污点传播
MATCH (n:identifier) WHERE n.callee = "recvfrom" AND n.index=1 WITH collect(id(n)) AS sourceSet
MATCH (n:identifier) WHERE n.callee = "snprintf" AND n.index=1 WITH sourceSet, collect(id(n)) AS sinkSet
CALL VQL.taintPropagation(sourceSet, sinkSet, 3) YIELD taintPropagationPath
RETURN taintPropagationPath
ustpd:0x0804F79B
漏洞3
漏洞附件为odhcpd
odhcpd_receive_packets在解包过程中存在缓冲区溢出漏洞。由strcat造成
char buf[32];
snprintf(buf, 0x20u, "Received %zd Bytes from ", len);
strcat(buf, ipbuf);
syslog(7, "%s", buf);
这个和下面的漏洞3可以是同一思路,因为这几个二进制中使用strcat函数的地方一共也没有几处,因此直接对危险函数strcat查询即可
MATCH (n:identifier) WHERE n.callee="strcat" AND n.index=1
RETURN n
odhcpd:0x000035F9
漏洞4
附件odhcpd
同样是strcat造成的漏洞
if ( destiface )
{
for ( i = interfaces.list_head.next; i->prev != interfaces.list_head.prev; i = i->next )
{
if ( i[4].next == (list_head *)destiface )
{
snprintf(buf, 0x20u, "Received %zd Bytes from ", len);
strcat(buf, ipbuf);
syslog(7, "%s");
((void (__cdecl *)(odhcpd_receive_packets::$54E5DB5725EA5BD631F9B1F8B1B758E1 *, uint8_t *, int, list_head *, void *))u[1].cb)(
&addr,
data_buf,
len,
i,
dest);
}
}
}
查找危险函数就可以筛选出
MATCH (n:identifier) WHERE n.callee="strcat" AND n.index=1
RETURN n
odhcpd:0x000036A9
漏洞5
附件为bgpd
在bgp_flowspec_ip_address函数中psize是用户可控的,这个值没有检查就被传入给了memcpy的第三个参数造成了缓冲区溢出
prefix_local.prefixlen = nlri_ptr[offset];
psize = PSIZE(prefix_local.prefixlen);
offset++;
prefix_local.family = afi2family(afi);
if (prefix_local.family == AF_INET6) {
prefix_offset = nlri_ptr[offset];
if (ipv6_offset)
*ipv6_offset = prefix_offset;
offset++;
}
memmove(&prefix_local.u.prefix, &nlri_ptr[offset], psize);
寻找第一个参数和第三个参数之间没有dfg(data flow graph)数据流关系的memmove函数调用。这种查询思路一个是排除了第三个参数为常数的情况,一个是排除了下面这种情况:
buf = malloc(n+1);
memmove(buf, data, n);
以下是查询语句
MATCH (n:identifier{callee:"memmove", index:0}), (m:identifier{callee:"memmove", index:2}) WHERE n.function=m.function AND m.line=n.line AND not (m)-[:dfg]-(n)
RETURN m.function, m.file
bgpd:0x8146C95
漏洞6
附件为bgpd
在bgp_capability_parse中memmove的第三个参数来自于用户可控的数据,但是并没有对其大小做限制
switch (caphdr.code) {
case CAPABILITY_CODE_MP: {
*mp_capability = 1;
/* Ignore capability when override-capability is set. */
if (!CHECK_FLAG(peer->flags,
PEER_FLAG_OVERRIDE_CAPABILITY)) {
/* Set negotiated value. */
ret = bgp_capability_mp(peer, &caphdr);
/* Unsupported Capability. */
if (ret < 0) {
/* Store return data. */
char tmp_buf[0x30];
memmove(tmp_buf, sp, caphdr.length + 2);
strcpy(*error, tmp_buf);
*error += caphdr.length + 2;
}
ret = 0; /* Don't return error for this */
}
} break;
寻找第一个参数和第三个参数之间没有数据流关系的memmove函数调用
MATCH (n:identifier{callee:"memmove", index:0}), (m:identifier{callee:"memmove", index:2}) WHERE n.function=m.function AND m.line=n.line AND not (m)-[:dfg]-(n)
RETURN m.function, m.file
bgpd:0x08149FE1
漏洞7
附件为bgp
在bgp_route_refresh_receive函数中,pize来自于用户数据后续没有进行范围检测即传入了memmove第三个参数中
if ((ok = (p_pnt < p_end)))
orfp.p.prefixlen = *p_pnt++;
/* afi checked already */
orfp.p.family = afi2family(afi);
/* 0 if not ok */
psize = PSIZE(orfp.p.prefixlen);
if (psize > 0)
memmove(&orfp.p.u.prefix, p_pnt, psize);
寻找第一个参数和第三个参数之间没有数据流关系的memmove函数调用
MATCH (n:identifier{callee:"memmove", index:0}), (m:identifier{callee:"memmove", index:2}) WHERE n.function=m.function AND m.line=n.line AND not (m)-[:dfg]-(n)
RETURN m.function, m.file
bgpd:0x08144EE0
漏洞8
在relay_process_headers中snprintf的第二个参数可控,也就是size字段可控,可以造成溢出
newline = strchr(buf, '\n');
if (!newline)
break;
line_len = newline + 1 - buf;
snprintf(log_buf, line_len, "%s", newline);
printf("%s", log_buf);
这里使用通常的污点追踪即可查询,我们可以通过一些自动化手段或人工判断出uhttpd文件中常用的source包含了ustream_get_read_buf等函数。
因此我们可以设置ustream_get_read_buf的返回值为source点,snprintf的第二个参数进行污点查询
MATCH (n:identifier) WHERE n.callee = "ustream_get_read_buf" AND n.index=-1 WITH collect(id(n)) AS sourceSet
MATCH (n:identifier) WHERE n.callee = "snprintf" AND n.index=1 WITH sourceSet, collect(id(n)) AS sinkSet
CALL VQL.taintPropagation(sourceSet, sinkSet, 3) YIELD taintPropagationPath
RETURN taintPropagationPath
uhttpd:0x0805108A
漏洞9
附件为ldpd
在session_get_pdu中dlen是可控的,dlen的长度会超过avf的长度造成memmove越界。
static ssize_t session_get_pdu(struct ibuf_read *r, char **b)
{
struct ldp_hdr l;
size_t av, dlen, left;
av = r->wpos;
if (av < sizeof(l))
return (0);
memcpy(&l, r->buf, sizeof(l));
dlen = ntohs(l.length) + LDP_HDR_DEAD_LEN;
if ((*b = malloc(dlen)) == NULL)
return (-1);
memcpy(*b, r->buf, dlen);
left = av - dlen;
memmove(r->buf, r->buf + dlen, left);
r->wpos = left;
return (dlen);
}
寻找第一个参数和第三个参数之间没有数据流关系的memmove函数调用
MATCH (n:identifier{callee:"memmove", index:0}), (m:identifier{callee:"memmove", index:2})
WHERE n.function=m.function AND m.line=n.line AND not (m)-[:dfg]-(n)
RETURN m.function, m.file
ldpd:0x080671A8
漏洞10
附件lldpd
在函数lldp_decode中,没有检测tlv_size是不是为0,后续在PEEK_BYTES造成缓冲区溢出
{
log_warn("lldp",
"unable to allocate memory for id tlv "
"received on %s",
hardware->h_ifname);
goto malformed;
}
memmove(b, pos, tlv_size - 1);
寻找第一个参数和第三个参数之间没有数据流关系的memmove函数调用
MATCH (n:identifier{callee:"memmove", index:0}), (m:identifier{callee:"memmove", index:2})
WHERE n.function=m.function AND m.line=n.line AND not (m)-[:dfg]-(n)
RETURN m.function, m.file
lldpd:0x0804F6EC
漏洞11
附件lldpd
同样是在函数lldp_decode中,不过是另一个case,没有检测tlv_size是不是为0,后续在PEEK_BYTES造成缓冲区溢出
{
log_warn("lldp",
"unable to allocate memory for string tlv "
"received on %s",
hardware->h_ifname);
goto malformed;
}
memmove(b, pos, tlv_size - 1);
寻找第一个参数和第三个参数之间没有数据流关系的memmove函数调用
MATCH (n:identifier{callee:"memmove", index:0}), (m:identifier{callee:"memmove", index:2})
WHERE n.function=m.function AND m.line=n.line AND not (m)-[:dfg]-(n)
RETURN m.function, m.file
lldpd:0x0804F848
漏洞12
附件bgpd
在函数bgp_notify_receive中,tmp_size是16位的数据,进行左移会造成整数溢出。后续malloc的大小会远小于memcpy的数据,最终溢出。
tmp_size = outer.length << 3;
if (inner.length) {
peer->notify.length = inner.length;
peer->notify.data = malloc(tmp_size);
memcpy(peer->notify.data, inner.raw_data, inner.length);
}
在bgpd中,通过人工或AI方法可以分析得知stream_getw,stream_getc等函数均可以作为source点。此时我们可以使用stream_getw函数为的返回值为source点,malloc函数的第一个参数为sink点进行污点查询
MATCH (n:identifier) WHERE n.callee = "stream_getw" AND n.index=-1 WITH collect(id(n)) AS sourceSet
MATCH (n:identifier) WHERE n.callee = "malloc" AND n.index=0 WITH sourceSet, collect(id(n)) AS sinkSet
CALL VQL.taintPropagation(sourceSet, sinkSet, 2) YIELD taintPropagationPath
RETURN taintPropagationPath
bgpd:0x081443F6
漏洞13
附件bgpd
同上,在函数bgp_notify_receive中,tmp_size是16位的数据,进行右移会造成整数溢出。后续malloc的大小会远小于memcpy的数据,最终溢出。
/* For further diagnostic record returned Data. */
if (inner.length) {
peer->notify.length = inner.length;
peer->notify.data = malloc(tmp_size);
memcpy(peer->notify.data, inner.raw_data, inner.length);
}
查询思路同漏洞1
bgpd:0x081444E5
漏洞14
同上,在函数bgp_notify_receive中,tmp_size是16位的数据,进行右移会造成整数溢出。后续malloc的大小会远小于memcpy的数据,最终溢出。
/* For debug */
{
int i;
int first = 0;
char c[4];
if (inner.length) {
inner.data = malloc(tmp_size);
for (i = 0; i < inner.length; i++)
if (first) {
snprintf(c, sizeof(c), " %02x",
stream_getc(peer->curr));
查询思路同漏洞1
bgpd:0x08144535
漏洞15
在control_read函数中bcb_left来自于用户可控的数据,读取了四个字节,但是并没有限制其大小。后续malloc的时候会造成整数溢出
/* Validate header fields. */
plen = ntohl(bcm.bcm_length);
bcb->bcb_buf = malloc(sizeof(bcm) + bcb->bcb_left + 1);
if (bcb->bcb_buf == NULL) {
zlog_warn("%s: not enough memory for message size: %zu",
__func__, bcb->bcb_left);
control_free(bcs);
return;
}
这个二进制程序中用read做source点即可
CALL VQL.getArgument("malloc",0) YIELD node WITH collect(id(node)) AS sinkset
CALL VQL.getArgument("read",1) YIELD node WITH collect(id(node)) AS sourceset, sinkset
CALL VQL.taintPropagation(sourceset,sinkset,3) YIELD taintPropagationPath
RETURN taintPropagationPath
bfdd:0x0805AD02
漏洞16
附件:uhttpd
漏洞1存在于uh_b64decode,其中tmp_buf长度是有限的,但是auth的长度可能会大于tmp_buf的空间
char tmp_buf[0x80];
if (auth && !strncasecmp(auth, "Basic ", 6))
{
auth += 6;
uh_b64decode(tmp_buf, auth, strlen(auth));
pass = strchr(tmp_buf, ':');
if (pass)
{
user = tmp_buf;
*pass++ = 0;
}
}
对函数名中包含decode和hex的进行查询。这里使用了正则匹配的方法。当然IDA和python脚本也可以实现类似的功能,不过在多文件等情况中使用这种图数据库查询语句是一种更为简单的平替。
MATCH (n:function)
WHERE n.name =~ ".*decode.*|.*hex.*"
RETURN n.name LIMIT 1000
uhttpd:0x08050812
漏洞17
附件:uhttpd
漏洞存在于uh_path_lookup中,其在调用uh_urldecode函数时会溢出uh_buff
/* no query string, decode all of url */
else if (uh_urldecode(&uh_buff[docroot_len],
url, strlen(url)) < 0)
return NULL;
与漏洞1相同
uhttpd:0x0804E4F3
漏洞18
附件:uhttpd
漏洞存在于uh_path_lookup中,其在调用uh_urldecode函数时会溢出uh_buff。
/* urldecode component w/o query */
if (pathptr > url)
{
if (uh_urldecode(&uh_buff[docroot_len], url, pathptr - url) < 0)
return NULL;
}
同上
uhttpd:0x0804E52D
漏洞19
附件: odchpd-ipv6
该漏洞存在于附件odhcp-v6中,在dhcpv6_ia_handle_IAs中调用odhcpd_hexlify,其中olen没有长度限制会造成缓冲区溢出
dhcpv6_for_each_option(start, end, otype, olen, odata)
{
if (otype == DHCPV6_OPT_CLIENTID)
{
clid_data = odata;
clid_len = olen;
if (olen == 14 && odata[0] == 0 && odata[1] == 1)
memcpy(mac, &odata[8], sizeof(mac));
else if (olen == 10 && odata[0] == 0 && odata[1] == 3)
memcpy(mac, &odata[4], sizeof(mac));
odhcpd_hexlify(duidbuf, odata, olen);
}
同上
odchpd-ipv6:0x0000D361
漏洞20
附件:sshd
在sshd附件中setproctitle函数中会调用strnvis函数,该函数实际是从v8到v9进行了拷贝,但是v8的大小是小于v9的。这个函数功能是转化不可见字符。
char v8[512]; // [esp+1Ch] [ebp-61Ch] BYREF
char v9[1024]; /
strvis(v8, v9, 27);
sshd:0x0008C045
MATCH (m:code_line)<-[:own]-(n:basic_block)-[:cfg*1..3]->(n)
WHERE m.name contains "*param_2"
RETURN DISTINCT n.function