
一、前言
随着网络安全攻防演练活动的推进,国内许多厂商产品的安全性越来越高,传统的漏洞挖掘思路已经不太容易能挖到漏洞了,许多时候需要分析代码的业务逻辑,将多个业务逻辑组合起来形成一个完整的漏洞利用。本篇文章将以抛砖引玉的方式,用笔者之前挖到的一个漏洞(已修复)为例,分享在漏洞挖掘方面的一些思路以及Trick。
该漏洞由三部分组成:特别的任意文件上传、身份认证绕过、RASP绕过及jsp访问拦截绕过。通过该漏洞可以在目标服务器达成远程代码执行的目的。
二、特别的任意文件上传
该漏洞就是由于系统中对上传文件格式以及跨目录做了严格的限制,直接找不到任意文件上传漏洞,但是通过两部分业务逻辑组合可以达成任意文件上传的目的。分为如下两个步骤:
2.1 上传文件并在数据库中记录
某认证后jersey类型的web接口会执行到如下代码,从this.params中获取两个值后调用loadFileForImage方法,此处的this.params中存储的是http请求包中的参数,所以用户完全可控。
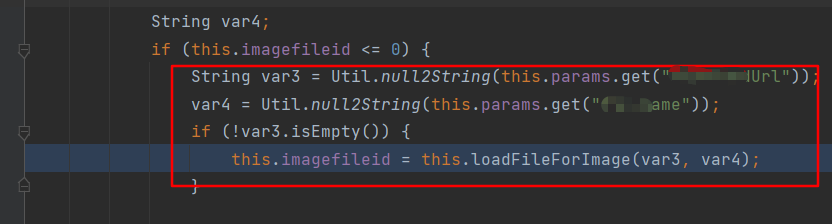
loadFileForImage方法调用ImageConvertUtil#downloadUrl方法获取输入流后赋值给var8的data属性,var2赋值给ImagFileName属性,分别表示文件输入流和文件名,然后调用saveImageFile方法。
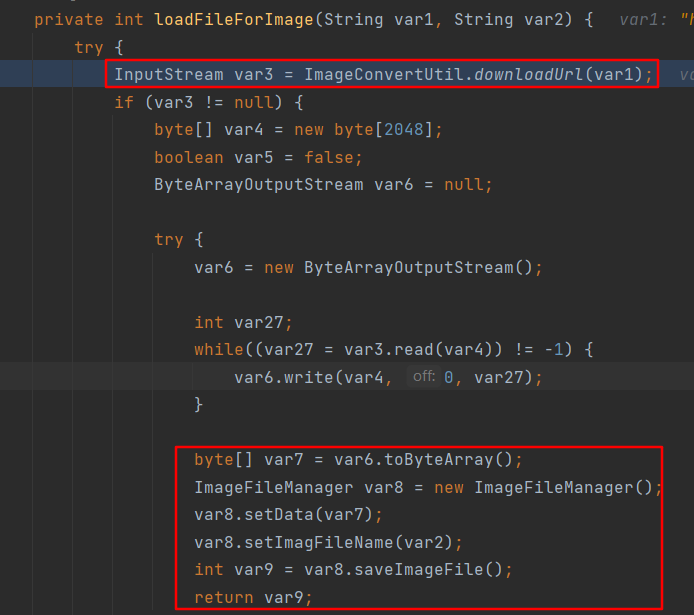
download方法根据用户提供的url直接获取输入流并返回,此处其实也存在一个ssrf漏洞。
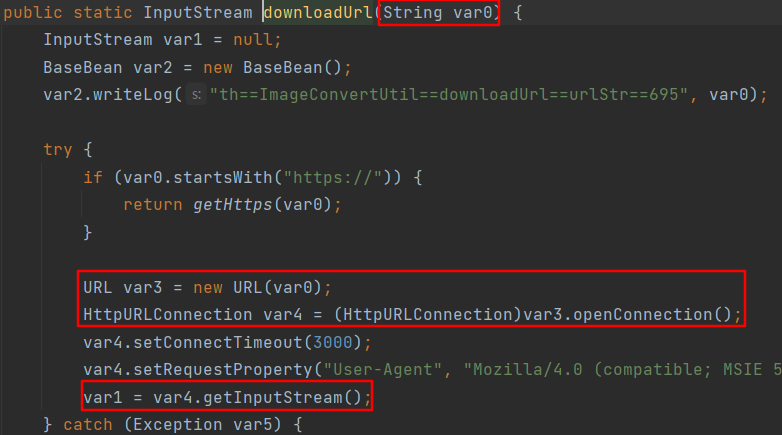
saveImageFile方法关键代码主要有2部分逻辑,第一部分是调用ZipOutputStream.write方法将this.data(前边获取的文件输入流)写入zip文件。由于默认var6为 1,所以文件名是.zip结尾的,因此文件写入时文件名不可控。
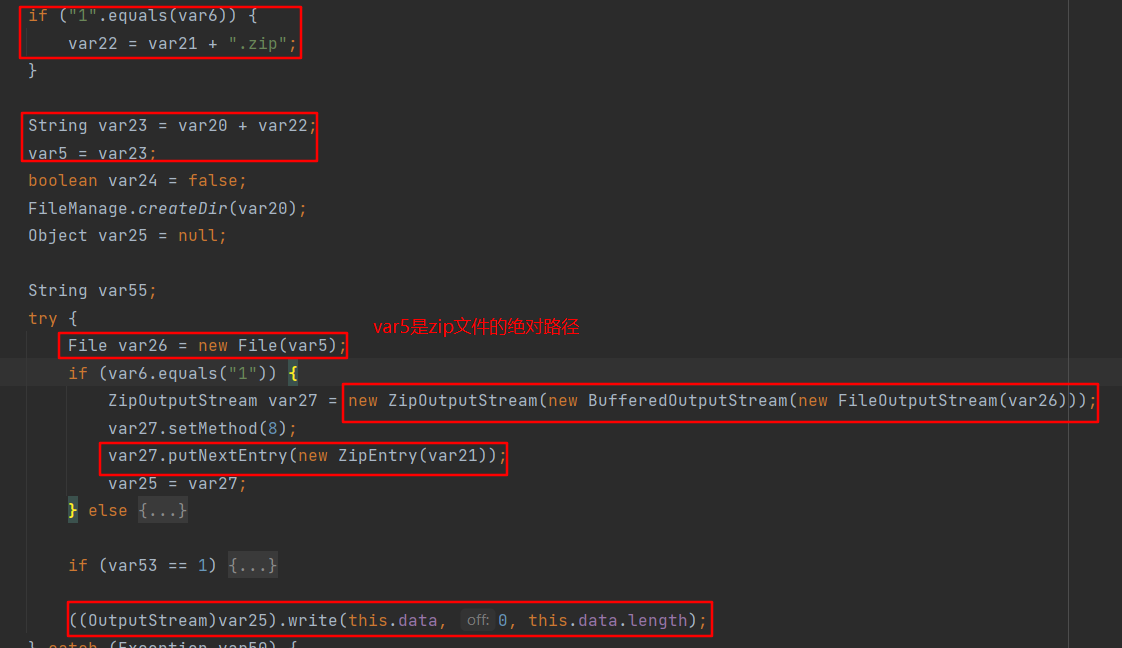
第二部分逻辑是在zip文件写入完成后执行一段insert sql语句将这次文件写入操作记录在数据中。数据库中imageFileId字段表示当前操作的数字编号,imageFileName字段是前面设置的imagFileName属性用户可控,fileRealPath是zip文件绝对路径。

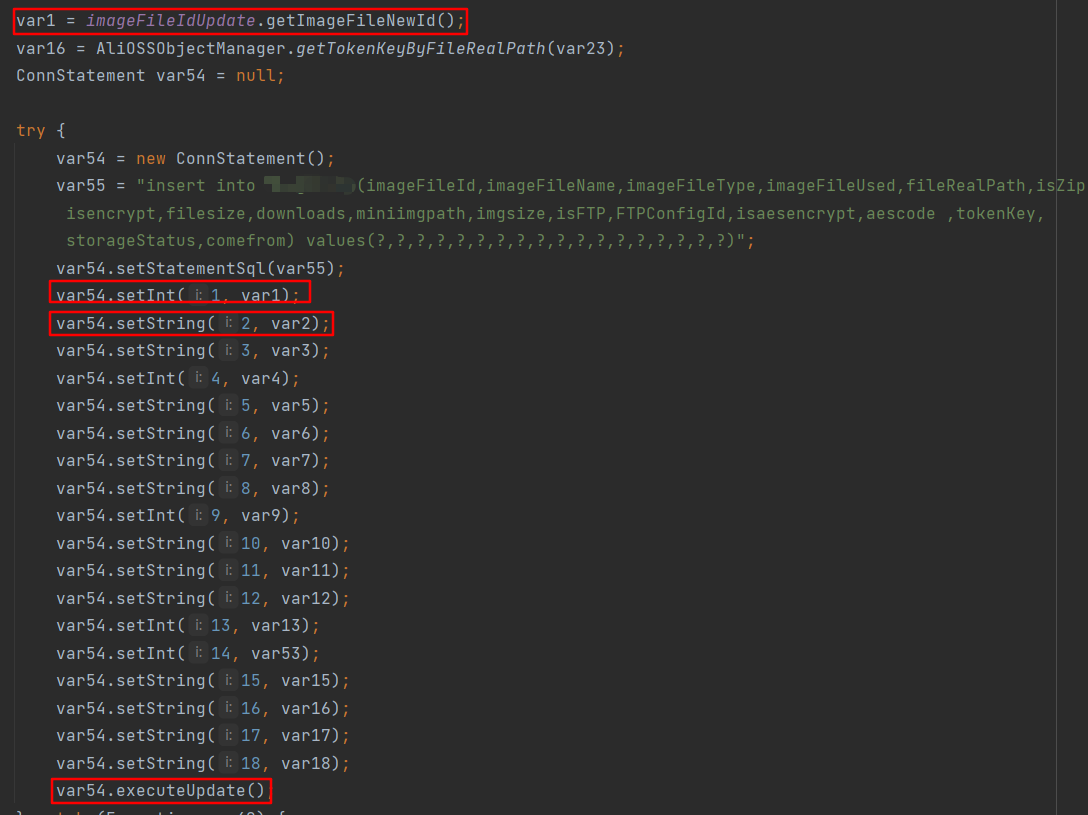
2.2 查数据库写文件
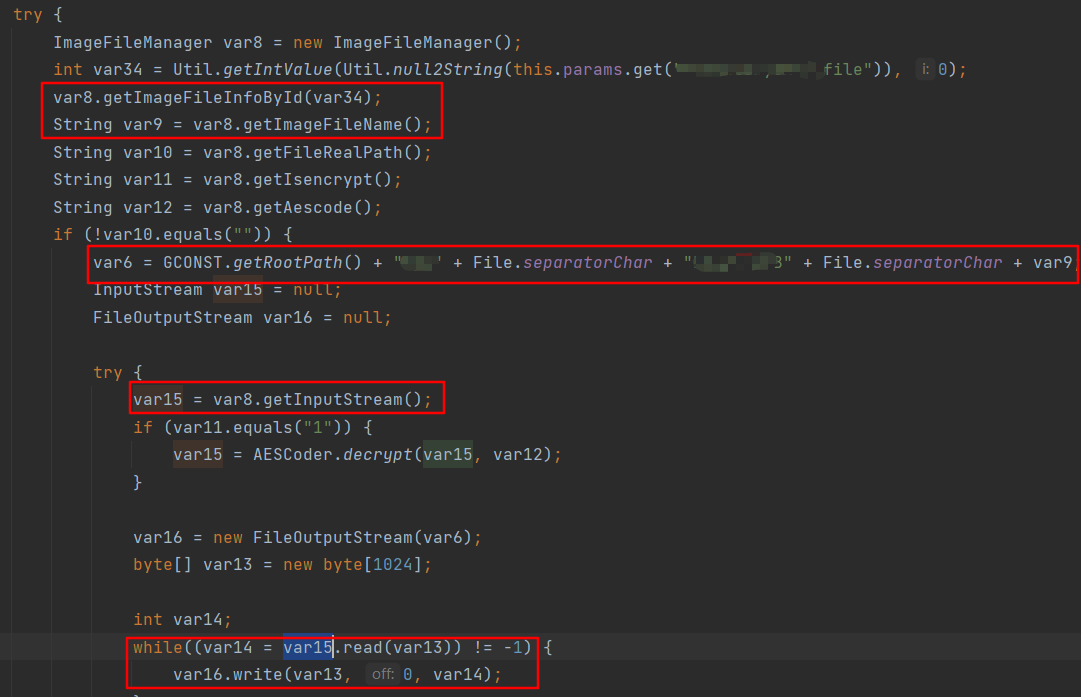
另一个认证后的jersey类型的web接口会调用到如下代码,该方法中new 一个ImageFileManager 对象var8,先调用getImageFileInfoById方法,再调用ImageFileManager#getInputStream获取其输入流后用FileOutputStream#write方法写入目标文件中,目标文件名是通过和var8.getImageFileName()拼接而成的。所以要是能控制var8的输入流和imageFileName属性就可以写入任意文件。而ImageFileManager 构造方法中所有并未给其属性赋值,所以赋值的过程一定在getImageFileInfoById方法中,方法参数var34是用户可控的。
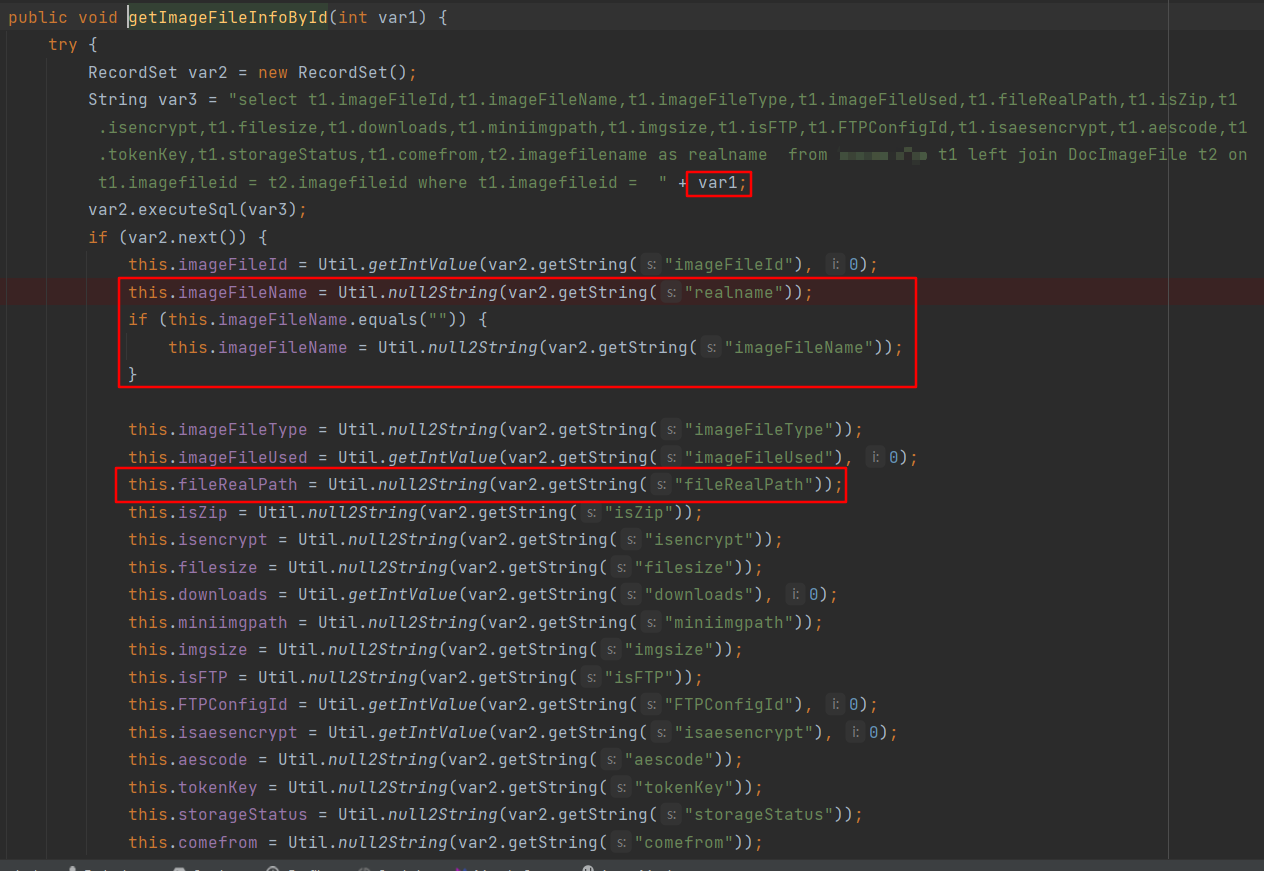
getImageFileInfoById中根据imagefileid查数据库将值赋值给对应的属性,因为插入数据库的时候realname字段没写入值所以还是会获取imageFileName。
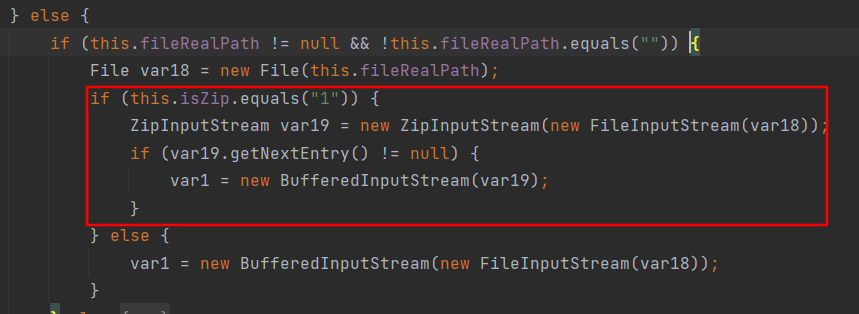
再看 getInputStream方法,获取fileRealPath路径的文件输入流并返回,关键代码如下:
2.3 小结
- 上传文件并在数据库中记录这一步骤可根据用户指定url获取输入流以zip形式保存在服务器上,并在数据库中保存文件相关信息包括用户指定的ImageFileName、zip文件的绝对路径等,最后返回imagefileid值。
- 查数据库写文件这一步骤根据用户输入的imagefileid值,将对应zip文件内容写入新文件中,新文件名是和ImageFileName值拼接而成。
以上两步结合就可以实现任意文件上传。
系统给所有jersey类型的web接口配置了filter去做身份认证,那么如何绕过身份认证呢?以下提供一种绕过的思路。
三、身份认证绕过
该身份认证绕过是利用invoker servlet的特性完成的。
3.1 invoker servlet简介及特性
invoker servlet是resin、tomcat等提供的功能,可以通过 URL 动态调用classpath中的任意servlet,甚至系统中没配置的servlet在都可以被调用。以下是resin官方文档中的描述。
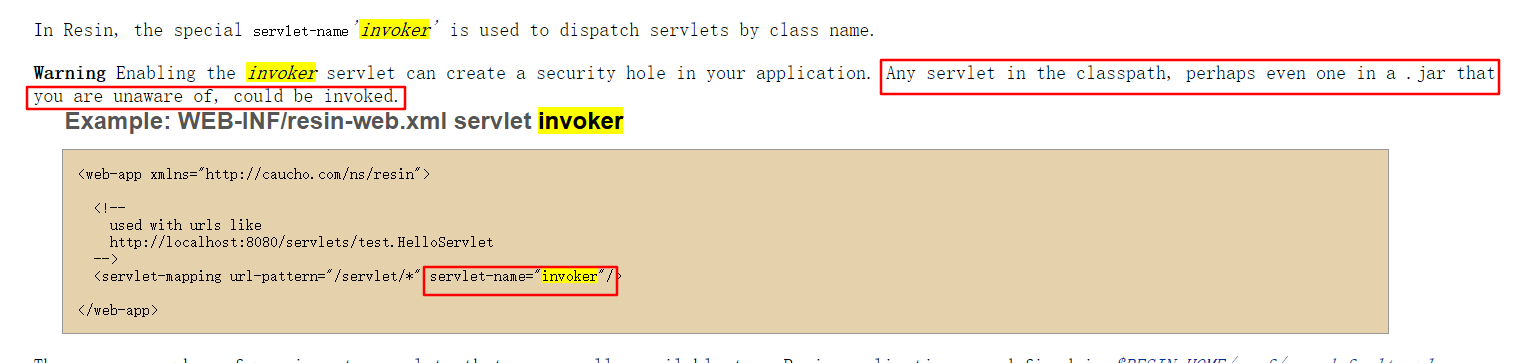
invoker servlet一般是在resin如下xml配置文件配置
WEB-INF/resin-web.xml
$RESIN_HOME/conf/app-default.xml
$RESIN_HOME/conf/resin.xml
......
以下是WEB-INF/resin-web.xml配置invoker servlet的例子
<web-app xmlns="http://caucho.com/ns/resin">
<!--
used with urls like
http://localhost:8080/servlets/test.HelloServlet
-->
<servlet-mapping url-pattern="/servlet/*" servlet-name="invoker"/>
</web-app>
以下是 $RESIN_HOME/conf/app-default.xml配置invoker servlet的例子
<cluster>
<web-app-default>
<servlet-mapping url-pattern="*.jsp" servlet-name="jsp"/>
<servlet-mapping url-pattern="*.xtp" servlet-name="xtp"/>
<servlet-mapping url-pattern="/servlet/*" servlet-name="invoker"/>
<servlet-mapping url-pattern="/" servlet-name="file"/>
</web-app-default>
</cluster>
tomcat7开始默认是不开启invoker servlet的。一般是在$TOMCAT_HOME/conf/web.xml中配置,例子如下。
<servlet>
<servlet-name>invoker</servlet-name>
<servlet-class>
org.apache.catalina.servlets.InvokerServlet
</servlet-class>
<init-param>
<param-name>debug</param-name>
<param-value>0</param-value>
</init-param>
<load-on-startup>2</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>invoker</servlet-name>
<url-pattern>/servlet/*</url-pattern>
</servlet-mapping>
Invoker Servlet本身是一个servlet,假设他的url-pattern是/InvokerPattern,则可以通过形如/InvokerPattern/package.name.servletname方式去调用其他servlet。
如果被调用的servlet在web.xml中配置的servlet-name是servlet-name,也可以通过形如**/InvokerPattern/servlet-name**的方式去调用。
假设被调用的servlet的url-pattern是/servletpattern,那么通过invoker servlet调用时url由原来的/servletpattern变成了/InvokerPattern/package.name.servletname或**/InvokerPattern/servlet-name**,所以给**/servletpattern**配置的过滤器将不会被调用,只会调用Invoker Servlet 适用的过滤器以及/* 等统配过滤器。
因此invoker servlet有两个很重要的特性:
- 调用任意classpath中的servlet(包括未在web.xml或者使用注解等方式显式配置的servlet)
- 绕过被调用的servlet配置的过滤器
3.2 绕过
目标系统中$RESIN_HOME/conf/resin.xml中配置了invoker servlet。

认证后任意文件上传漏洞的web接口都是jersey类型的web接口,jersey是通过com.sun.jersey.spi.container.servlet.ServletContainer路由分发的,该类也是一个servlet。
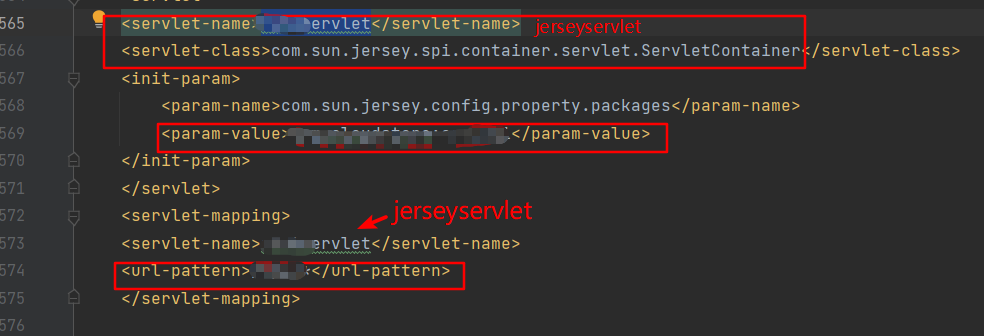
所以可以通过/InvokerPattern/jerseyservlet/web接口path的方式访问去绕过jerseyservlet所配置的身份认证的filter。
四、RASP及jsp访问拦截绕过
绕过身份认证后发包上传jsp文件,访问404,经过调试发现系统中有2个拦截:RASP拦截以及jsp访问拦截。
4.1 RASP拦截
系统使用agent对关键方法做了hook,以防止危险操作。
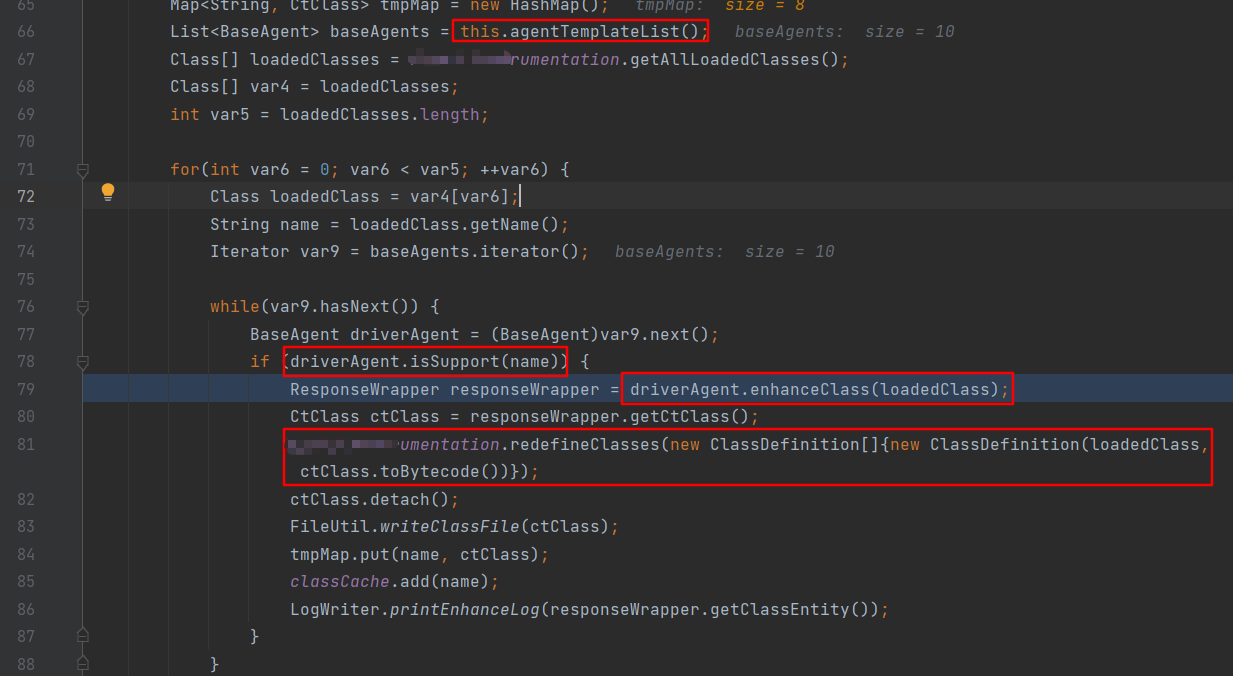
主要逻辑是用agentTemplateList根据配置生成BaseAgent实例,每个BaseAgent实例classEntity属性中维护着要被hook的方法的信息。遍历所有已经加载的类,如果类名在classEntity中,调用每个BaseAgent实例的enhanceClass方法,最终调用BaseAgent#insertCodeBefore在被hook的方法最前面插入自定义逻辑代码。最后利用Instrumentation#redefineclass将修改后的字节码还原成java对象。

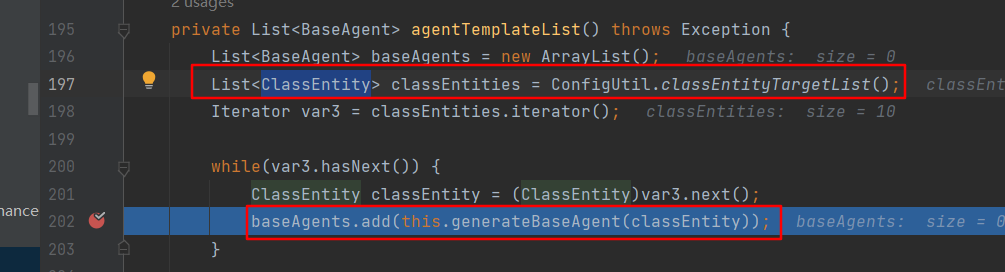
跟进agentTemplateList方法,其中的逻辑就是根据配置获取ClassEntity,赋值给对应的BaseAgent类的classEntity属性,配置在xml文件中,根据类全限定名、方法名、方法参数确定要被hook的方法。
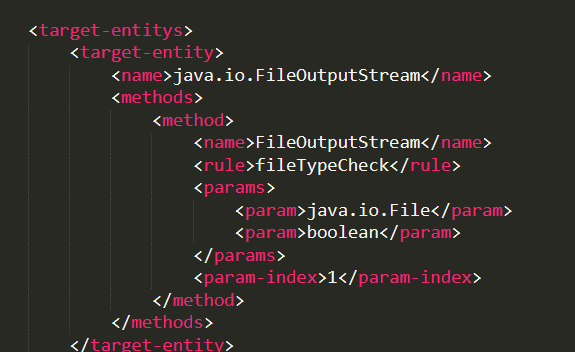
BaseAgent有不同的实现类,分别对应命令执行、文件写入等的hook逻辑,文件写入实现类的doEnhanceClass方法中调用insertCodeBefore在java.io.FileOutputStream#FileOutputStream(java.io.File, boolean)前插入了一段代码。
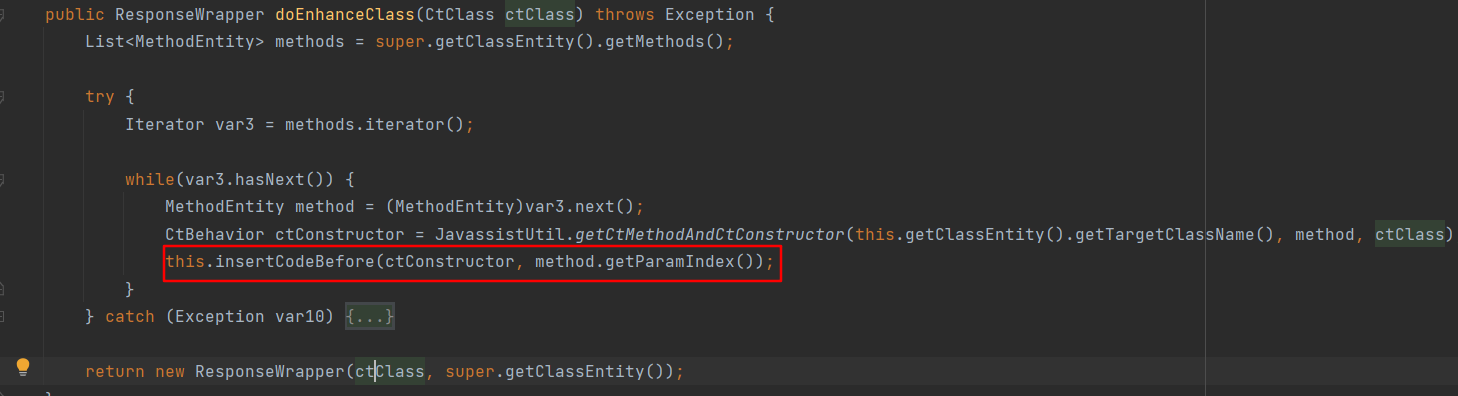
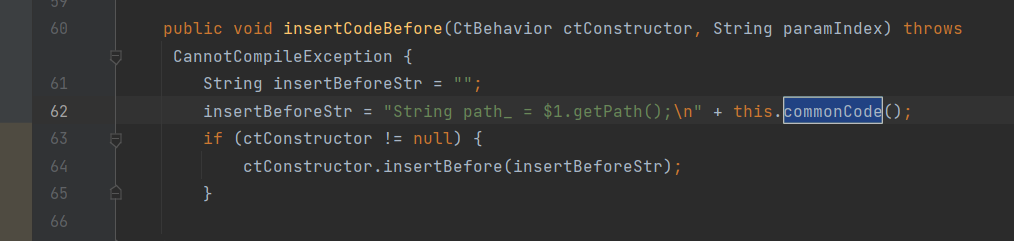
插入的代码如下,主要逻辑是文件路径转小写,如果后缀在黑名单中,且访问的url不以skipWriteUrlCheck白名单开头,且文件路径不以skipWritePathCheck白名单开头,则文件不合法,不让写入。但是没限制../等跨目录字符。
//调用FileOutputStream第一个参数的getPath方法,也就是获取文件路径
String path_ = $1.getPath();
if (path_ == null) {
path_ = "";
}
path_ = path_.replaceAll("/+","/");
//path_转小写,所以大写绕过不行
path_ = path_.replaceAll("\\\\+","/").toLowerCase();
String value_ = "";
try {
java.lang.Class aClass_ = Class.forName("xxxx.yyy.zzz.bridge.bridge.RequestPathBridge");
// 获取请求uri
value_ = aClass_.getMethod("getValue", null).invoke(null, null).toString();
} catch (java.lang.Exception exception) {
System.out.println("增强File源码异常:" + exception.toString());
value_ = "";
}
if (path_.contains("./")) {
System.out.println(">>agent file path check only log, path_= " + path_ + " url = " + value_);
}
//获取文件写入黑名单
String fileNotAllowWrite = System.getProperty("fileNotAllowWrite");
if (fileNotAllowWrite != null && !value_.equals("") && !fileNotAllowWrite.contains("*.*")) {
String[] fileNotAllowWriteSplit = fileNotAllowWrite.split(",");
for (int i = 0; i < fileNotAllowWriteSplit.length; i++) {
String suffix = fileNotAllowWriteSplit[i];
//检测文件后缀是否在黑名单中
if (path_.endsWith(suffix)) {
String skipWriteUrlCheck = System.getProperty("skipWriteUrlCheck");
String skipWritePathCheck = System.getProperty("skipWritePathCheck");
String agentRootPath = System.getProperty("agent-root-path");
if (skipWriteUrlCheck != null && skipWritePathCheck != null) {
boolean flag = false;
String[] skipWriteUrlCheckSplit = skipWriteUrlCheck.split(",");
//url白名单则跳过拦截操作
for (int m = 0; m < skipWriteUrlCheckSplit.length; m++) {
String writeUrl = skipWriteUrlCheckSplit[m];
value_
if (value_.startsWith(writeUrl)) {
flag = true;
}
}
if (!flag) {
String[] skipWritePathCheckSplit = skipWritePathCheck.split(",");
//写入文件路径以白名单开头则跳过检测
for (int j = 0; j < skipWritePathCheckSplit.length; j++) {
String writePath = skipWritePathCheckSplit[j];
if (path_.startsWith(writePath)) {
flag = true;
}
}
}
//agentRootPath为系统根路径
if (!flag && agentRootPath != null && !path_.contains(agentRootPath)) {
flag = true;
}
//flag为false就不允许写入,默认为false
if (!flag) {
throw new RuntimeException("[security reject]接口或者写出路径不允许,uri=" + value_ + " path=" + path_);
}
}
}
}
} else {
if (fileNotAllowWrite == null) {
System.out.println("[security reject]日志仅仅为记录,并无拦截操作,路径:" + path_ + ",文件不允许写入类型:" + fileNotAllowWrite);
}
}
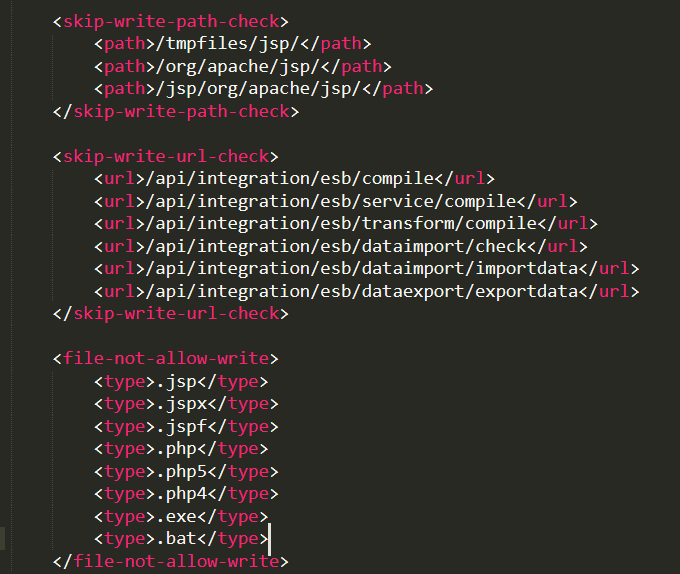
文件写入黑名单也在xml文件中配置,黑名单中没有.class
4.2 jsp访问拦截
当通过web访问jsp时会在一个通配的filter中调用到如下代码,逻辑是获取访问的jsp对应的file对象,如果file不存在则返回true字符串表示通过检测,如果jsp文件存在则进入else分支进行检测。
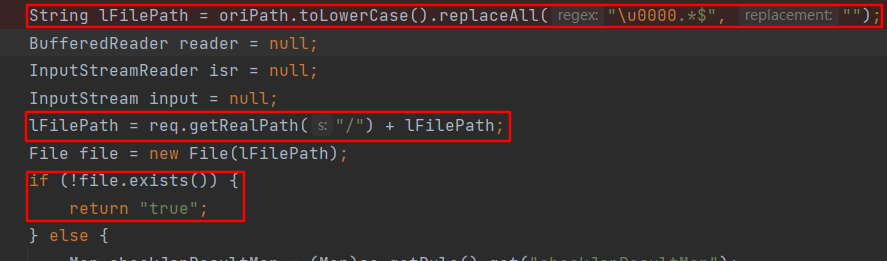
else分支的关键代码如下,检测jsp文件中的每一行是否包含危险方法字符串,如果包含则直接返回false字符串代表着检测失败。
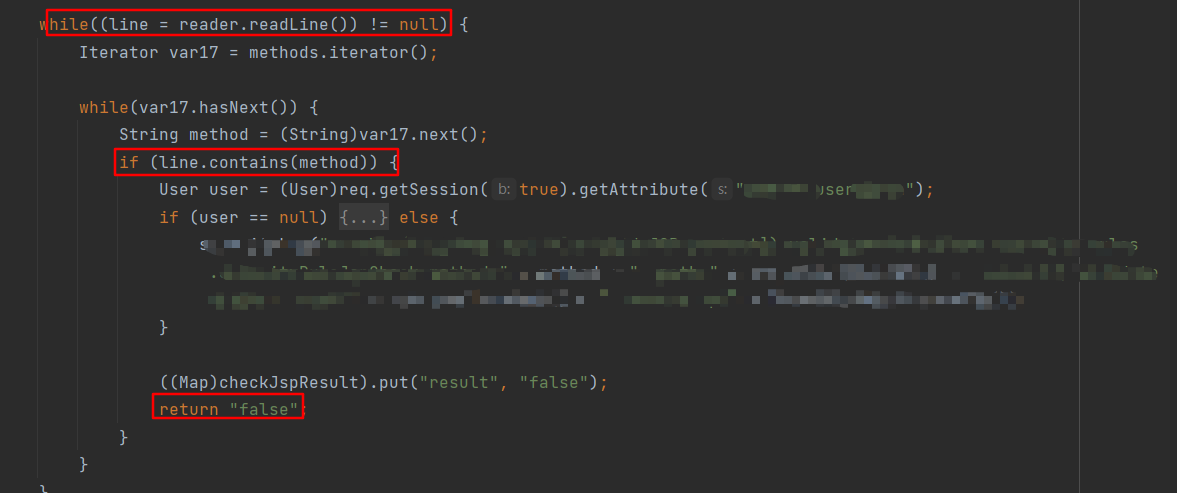
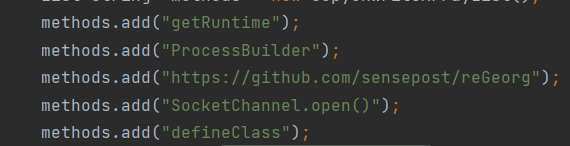
这里单纯的绕过jsp访问拦截只需要在上传的webshell中使用其他方法即可,但是如何既绕过rasp拦截又绕过jsp访问拦截,这就需要利用resin对jsp路由分发特性了。
4.3 resin jsp路由分发特性导致绕过
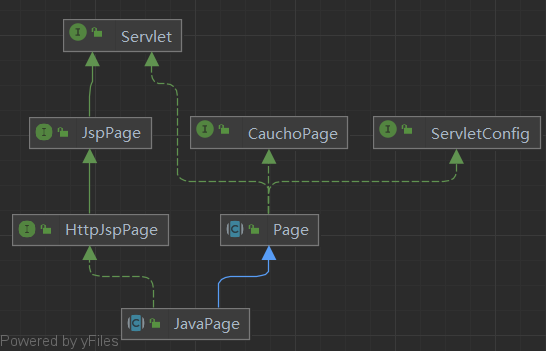
我们知道在第一次访问一个jsp文件时,servlet容器会经过jsp文件翻译成servlet源码 –> servlet源码编译成class文件 –> 加载并实例化servlet –> 路由分发到该servlet的过程。resin对java EE jsp规范的实现在com.caucho.jsp.JavaPage类中,其继承关系图如下。
例如本地$web根目录/1/mmuz.jsp在第一次访问后会在$RESIN_HOME/webapps/web根目录/WEB-INF/work/_jsp/_1目录下生成如下4个文件,.java文件是jsp翻译成的servlet的源码,两个class文件是源码编译后的文件。

生成JavaPage和路由转发的逻辑在com.caucho.server.dispatch.PageFilterChain#doFilter中,先获取Page对象,获取到就调用page.pageservice方法进行路由分发,关键代码如下
public void doFilter(ServletRequest request, ServletResponse response) throws ServletException, IOException {
HttpServletRequest req = (HttpServletRequest)request;
HttpServletResponse res = (HttpServletResponse)response;
FileNotFoundException notFound = null;
SoftReference<Page> pageRef = this._pageRef;
Page page;
if (pageRef != null) {
page = (Page)pageRef.get();
} else {
page = null;
}
if (page == null || page._caucho_isModified()) {
try {
this._pageRef = null;
//pagRef中没有page对象就开始编译page
page = this.compilePage(page, req, res);
if (page != null) {
this._pageRef = new SoftReference(page);
this._isSingleThread = page instanceof SingleThreadModel;
}
} catch (FileNotFoundException var13) {
page = null;
notFound = var13;
}
}
if (page == null) {
...
} else if (req instanceof HttpServletRequest) {
try {
//获取page后路由分发
page.pageservice(req, res);
}
...
跟进compilePage到com.caucho.jsp.PageManager#getPageEntry ,关键代码如下,主要逻辑是将url去掉协议、host和web系统上下文路径的部分转换成编译后servlet的全限定名,调用createPage方法
private Page getPageEntry(Entry entry, String uri, String pageURI, Path path, ServletConfig config, ArrayList<PersistentDependency> dependList) throws Exception {
Page page = entry.getPage();
if (page != null && !page._caucho_isModified()) {
return page;
} else {
if (page != null && !page.isDead()) {
try {
page.destroy();
} catch (Exception var17) {
log.log(Level.FINE, var17.toString(), var17);
}
}
//获取web系统根路径
Path rootDir = this.getWebApp().getRootDirectory();
//pageURI是jsp文件的url去掉host和web系统上下文路径的部分
String rawClassName = pageURI;
//path.getPath()获取jsp文件的绝对路径
if (path.getPath().startsWith(rootDir.getPath())) {
rawClassName = path.getPath().substring(rootDir.getPath().length());
}
//rawClassName如果是/1/mmuz.jsp则会转换为"_jsp._1._mmuz__jsp",是jsp生成的类的全限定名
String className = JavaCompilerUtil.mangleName("jsp/" + rawClassName);
page = this.createPage(path, pageURI, className, config, dependList);
...
跟进createPage方法到com.caucho.jsp.JspManager#compile,这里是关键所在,_precompile表示是否在系统启动时编译系统中的jsp文件,开启后可以在第一次访问一个jsp时提高响应速度,_autoCompile表示jsp文件修改后自动编译。由于这两个开关默认是开启的,所以先通过preload方法获取page,获取不到才走将jsp编译这一步。
Page compile(Path path, String uri, String className, ServletConfig config, ArrayList<PersistentDependency> dependList, boolean isGenerated) throws Exception {
WebApp webApp = this.getWebApp();
JspCompiler compiler = new JspCompiler();
compiler.setJspManager(this);
compiler.setWebApp(this._webApp);
compiler.setXml(this._isXml);
Page page = null;
try {
//_precompile和_autoCompile默认都是true
if (this._precompile || this._autoCompile) {
//先调用preload方法获取page
page = this.preload(className, this.getParentLoader(), webApp.getRootDirectory(), config);
}
}
if (page != null) {
return page;
//获取不到就走这个分支
} else if (path != null && !path.isDirectory() && this._autoCompile) {
Path jspJarPath = null;
boolean isPathReadable = path.canRead();
if (jspJarPath != null) {
path = jspJarPath;
}
JspCompilerInstance compilerInst = compiler.getCompilerInstance(path, uri, className);
compilerInst.setGeneratedSource(isGenerated);
compilerInst.addDependList(dependList);
//preload方法获取不到就将jsp翻译成servlet并编译
page = compilerInst.compile();
Path classPath = this.getClassDir().lookup(className.replace('.', '/') + ".class");
this.loadPage(page, config, (LineMap)null, uri);
if (classPath.canRead()) {
page._caucho_addDepend(classPath.createDepend());
}
return page;
} else {
return null;
}
...
com.caucho.jsp.JspManager#preload关键代码如下,将WEB-INF\work路径添加到DynamicClassLoader的path中,之后加载并实例化fullClassName,成功后return fullClassName实例。
Page preload(String className, ClassLoader parentLoader, Path appDir, ServletConfig config) throws Exception {
//fullClassName就是getPageEntry方法中的className,
String fullClassName = className;
String mangledName = className.replace('.', '/');
Path classPath = this.getClassDir().lookup(mangledName + ".class");
//将WEB-INF\work路径添加到DynamicClassLoader的path中,以便于在后续在该目录下进行类加载
DynamicClassLoader loader = SimpleLoader.create(parentLoader, this.getClassDir(), (String)null);
Class<?> cl = null;
//加载jsp对应的servlet类fullClassName
cl = Class.forName(fullClassName, false, loader);
//实例化
HttpJspPage jspPage = (HttpJspPage)cl.newInstance();
Page page = null;
if (jspPage instanceof CauchoPage) {
CauchoPage cPage = (CauchoPage)jspPage;
cPage.init(appDir);
if (cPage instanceof Page) {
((Page)cPage)._caucho_setJspManager(this);
}
((Page)page)._caucho_addDepend(classPath.createDepend());
this.loadPage((Page)page, config, (LineMap)null, className);
//返回page对象
return (Page)page;
...
根据上述代码逻辑可知,获取page的过程中会先在WEB-INF/work/_jsp目录下加载并实例化jsp编译后的class,成功则直接返回page。获取不到才走将jsp翻译成servlet并编译这一分支。所以WEB-INF/work/_jsp目录下有class文件就可以直接访问,并不需要存在jsp文件。
因此上传webshell在resin下编译后的class文件,就可以绕过文件上传时Rasp对于文件后缀的拦截,在访问webshell时jsp访问拦截过程中由于服务器只有webshell对应的class文件而没有jsp文件,导致取不到jsp的File对象,也可以直接绕过jsp访问拦截。
五、总结&思考
本文分享了业务逻辑组合导致的文件上传漏洞、invoker servlet特性导致的权限认证绕过、resin对于jsp路由分发处理的特性导致的防护拦截绕过三部分组合而成的一个完整漏洞利用。除了resin的特性是一个通用的Trick,文件上传和rasp及jsp访问拦截绕过部分是和目标系统代码强相关的,不能在挖掘其他系统漏洞的时候完全复用,但是大体的思路也是有一定参考意义的。
在看到文件名后缀是zip时,一般来说就认为不存在文件上传漏洞了。但是如果带着理解代码逻辑的想法去分析完这部分代码并且看看该类中的其他方法,很容易就能发现还有个逻辑是通过查数据库把zip文件内容写入到新文件,两者组合就能形成一个任意文件上传。再结合invoker servlet的功能就能将认证后的漏洞变成认证前的漏洞。最后再利用resin的特性就可以绕过拦截防护。
这一案例说明了在漏洞挖掘过程中,仅仅依赖于单个代码片段的审查往往是不够的,更多的时候需要仔细分析代码的业务逻辑、各种组件的特性、相互之间的关联性,将这些点结合起来往往会有意想不到的效果。
六、参考链接
https://www.caucho.com/resin-4.0/reference.xtp