一、前言
Rust反编译一直是比较困难的问题,Rust强调零成本抽象,在使用高级特性(如泛型、闭包、迭代器等)时为了不引入额外的运行时开销,编译器会生成高度优化且复杂的机器码,从而难以直接恢复高层的抽象结构,除此之外,Rust 的所有权系统及其借用检查器在编译过程中被彻底消解成运行时代码。这个过程生成了许多低级的内存管理代码,这些代码在反编译时难以重新构建成高层次的所有权和生命周期语义。尽管反编译 Rust 代码有诸多困难,但进行 Rust 反编译依然具备现实意义,例如分析闭源Rust代码,寻找潜在的安全漏洞。本文旨在学习Rust基本内存数据结构及其内存布局,并且通过反编译视角理解Rust编译器到底做了什么事。
值得注意的时,Rust目前没有确定内存模型,因此本文谈到的是Rustc编译器实现的Rust模型。
Rust 目前没有确定内存模型
Rust does not yet have a defined memory model. Various academics and industry professionals are working on various proposals, but for now, this is an under-defined place in the language.
二、反编译器准备
本文中的很多例子会使用到反编译工具,例如IDA或者ghidra。ghidra在11版本以后增加了对Rust支持,在使用ghidra进行反编译Rust工具时只需要选中Demangler Rust即可。
IDA则需要额外的IDARustDemangler插件,不管是ghidra的Demangler Rust功能亦或是IDARustDemangler插件,其功能都是将Rust二进制文件中经过编译器mangle过的符号进行demangle,得到原始符号,以下以IDA得视角对比了demangle之前与demangle之后得代码视图,可以看到可读性大大增加。
demangle之前:

demangle之后:

三、函数调用__Rustcall
在x86_64平台UNIX系统下面,Rust遵循System V ABI,即传参会通过rdi、rsi、rdx、rcx、r8、r9等,返回值会通过rax,在某些情况下,compiler会进行返回值优化(Return Value Optimization,RVO),这时候函数调用约定就会发生变化,返回值不再是使用rax进行传递,而是使用rdi(函数的第一个参数)。以如下例子为例,我们查看ghidra编译器到底做了什么?
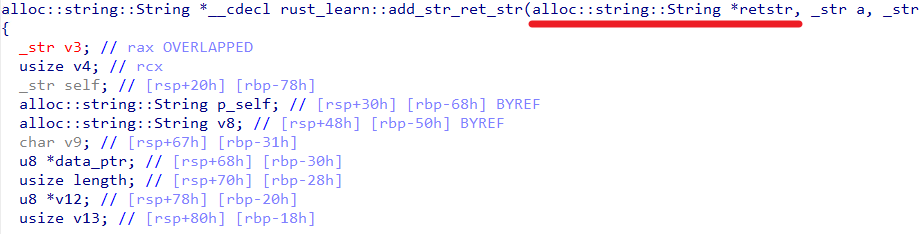
fn add_str_ret_str(a:&str,b:&str)->String{
return a.to_string()+&b.to_string();
}
对于上述代码,因为在返回时新建了对象(没有新建对象不会触发RVO,此时依旧通过rax传递对象),会触发返回值优化,使得返回值通过第一个参数进行传递。
IDA视角下得Rustcall,IDA会将第一个参数命名为retstr,提醒用户这个字段是返回值。
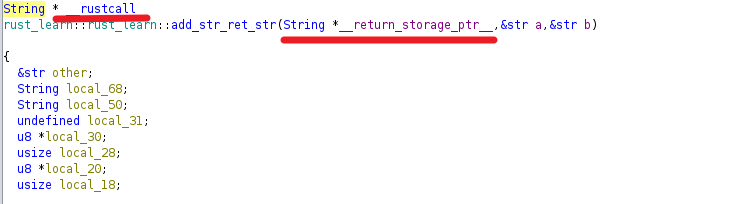
在ghidra视角下rust调用使用__rustcall关键字标识,ghidra使用return_storage_ptr来标记返回值。
四、Rust内存布局
在Rust中基本类型、引用(存储的是变量的地址,大小为8字节)、数组(连续内存块)与传统的C、C++内存布局一样,因此本文不再赘述。本文主要探究Rust特有实现,例如动态数组、String、动态大小类型(Dynamic Sized Type,DST)。
4.1 动态数组与String
Rust中的动态数组Vec以及String类型的底层实现与C++容器相同,其采用三个部分来表示,分别是:
- pointer:指向数据字节流buffer中存储的数据;
- length:buffer中字节流的字节长度;
- capacity:buffer的长度。
实际上看String的实现,会发现String的实现基于Vec,以下代码摘自Rust底层实现:
#[derive(PartialEq, PartialOrd, Eq, Ord)]
#[stable(feature = "rust1", since = "1.0.0")]
#[cfg_attr(not(test), lang = "String")]
pub struct String {
vec: Vec<u8>,
}
#[stable(feature = "rust1", since = "1.0.0")]
#[cfg_attr(not(test), rustc_diagnostic_item = "Vec")]
#[rustc_insignificant_dtor]
pub struct Vec<T, #[unstable(feature = "allocator_api", issue = "32838")] A: Allocator = Global> {
buf: RawVec<T, A>,
len: usize,
}
#[allow(missing_debug_implementations)]
pub(crate) struct RawVec<T, A: Allocator = Global> {
ptr: Unique<T>,
cap: Cap,
alloc: A,
}
下面我们看看这样一个简单的程序,其在堆上创建了一个动态数组,数组的每个元素存储String类型。
let mut vec =vec!["hello".to_string(),"world".to_string()];
//vec[1]="rust".to_string();
println!("{:?}",vec)
其DeBug模式下反编译对应的部分代码如下,观察整个代码可以看到程序做了以下事情 :
- 调用
exchange_malloc分配vec动态数组vec; - 两次调用
to_string分别创建"hello"、"world" String;(self_8以及v8,注意!这里由于RVO,函数使用第一个参数传递返回值) - 使用vec存储两个String。
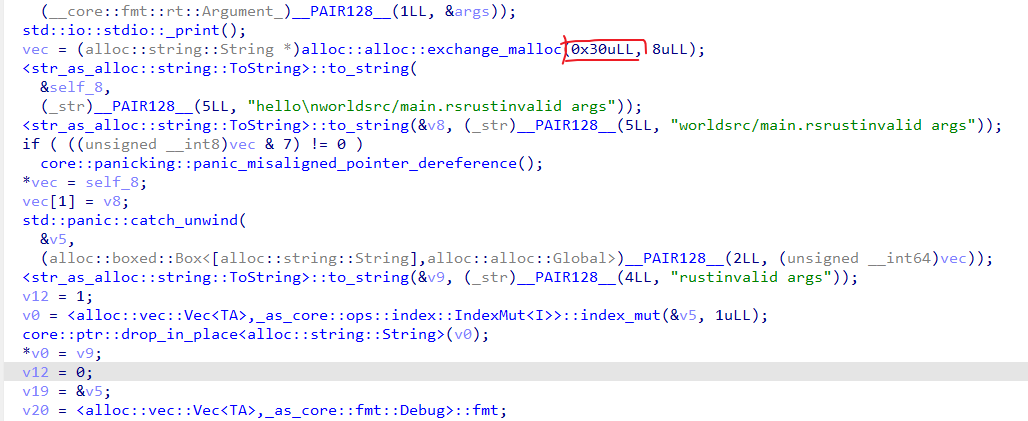
可以看到整体的代码变得可读性不是很高,出现了与源代码有很多出入的部分,例如std::catch_unwind、<alloc::vec::Vec<TA>,_as_core::fmt::Debug>::fmt等,这部分代码是由println!宏展开得到。
unsafe fn exchange_malloc(size: usize, align: usize) -> *mut u8
除此之外,可以看到程序调用exchange_malloc分配堆上内存,exchange_malloc的第一个参数为分配内存的大小,第二个参数为内存对齐字节。这里函数分配了0x30大小的堆上内存来存储2个String类型的变量。由此可以看到,每个String类型占据0x18大小的内存,分别用来存储ptr、capicity以及length(每个元素占用8个字节)。所以实际上内存布局如下图(由于结构体变量顺序可能由于内存对齐等问题进行重排,因此ptr、cap、len顺序可能会发生变化):
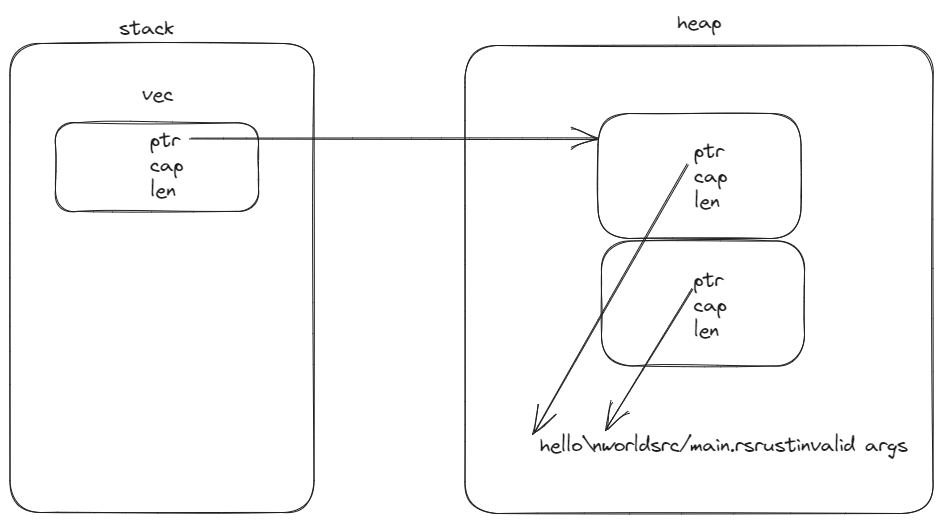
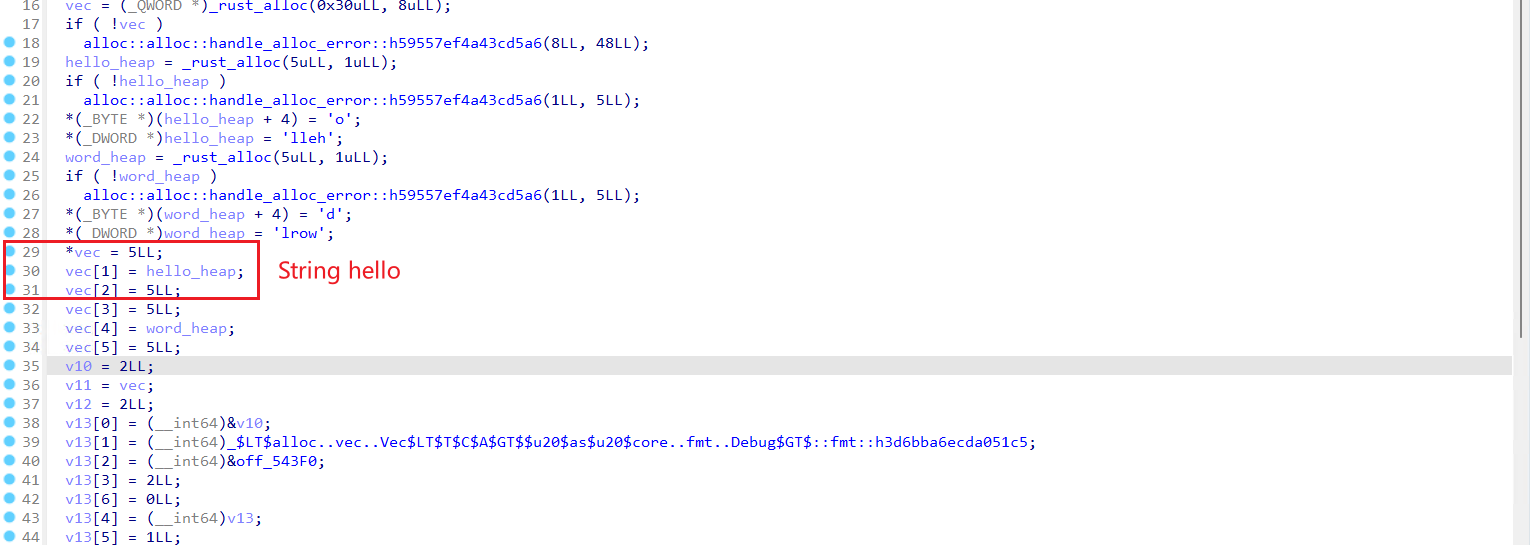
上面是debug模式下反编译器观察到的代码,String与Vec在release模式下看可能更明显的辨别出来,例如其会使用两个常量值来表明length以及capicity、使用一个指针指向实际数据。
观察一下debug版本中"hello".to_string() ,to_string函数的函数签名为fn to_string(&self)-> String,而实际调用to_string的汇编代码如下,to_string对应的汇编代码:

可以看到to_string函数调用实际上传递了3个实参,第一个是返回值rdi,那第二、三个参数是什么?是"hello"字符串嘛?那第三个参数是什么? 这里直接给出答案:第二个是"hello"字符串地址,第三个是长度,那么为什么一个"hello"(这里的"hello"类型是str,即字符串切片)需要传递两个参数?这里不得不提一下胖指针(fat pointer)。
4.2 Fat Pointer
Fat pointer实际上相当于两个指针,其中一个指针指向数据,另一个指针携带数据相关的metadata。在Rust语言中,Fat pointer主要用于DST,从而让编译器在编译时便可以静态知道类型的大小。那么什么是DST呢?
DST
A fat pointer contains a pointer plus some information that makes the DST “complete” (e.g. the length).
DST是Dynamic Sized Types,即动态大小类型,指的是"编译器静态无法获取该类型大小,只能在运行时动态获得"。 在Rust里面,属于DST的有四类:[T]和str、特征对象、DST和外部类型。
切片[T]和str
//str示例 let s1: str = "Hello there!"; //DST let s2: str = "How's it going?"; //DST //切片示例 let arr = [1, 2, 3, 4, 5]; let s3 = arr[1..3] //DST特征对象(Trait Object):类似于C++里的多态 ,后面我们会通过具体例子来讲解。
其他:由于本文探究Rust常见数据类型,因此本文不关注自定义DST和外部类型。
[T]与str
首先我们看切片与str,我们通过std::mem::size_of查看不同类型的输出,可以看到因为&u32与&[u32;2]的大小在运行时可知,因此Rust编译器认为其为普通指针,大小为8字节。对于&[u32],由于[u32]的大小编译时无法知道(因为编译器只知道该切片的每个元素大小,但是不知道长度),编译器将其实现为16字节的Fat pointer。
dbg!(std::mem::size_of::<&u32>());//[src/main.rs:100:5] std::mem::size_of::<&u32>() = 8
dbg!(std::mem::size_of::<&[u32; 2]>());//[src/main.rs:101:5] std::mem::size_of::<&[u32; 2]>() = 8
dbg!(std::mem::size_of::<&[u32]>());//[src/main.rs:102:5] std::mem::size_of::<&[u32]>() = 16 因为[u32]是DST
在这种情况下,fat pointer类似于下面的结构,即一个指针指向数据buffer,一个指针保存buffer的长度。
struct SliceRef {
ptr: *const u32,
len: usize,
}
对于str类型,len表示字节长度值;对于切片类型,表示的是数组元素的数目。
特征对象
特征对象(trait object)在Rust中使用Box<dyn Trait>或者&dyn Trait来表示实现了某个Trait的对象,我们同样使用如下的例子来了解Rust的fat pointer,可以看到常规对象Cat运行时大小已知,因此指向其的引用(&Cat)底层使用普通指针,而特征对象dyn Animal大小运行时未知(你不知道实现Animal Trait的对象有哪些),因此Rust底层使用fat pointer来表示,其大小为16字节。
trait Animal {
fn speak(&self);
}
struct Cat;
impl Animal for Cat {
fn speak(&self) {
println!("meow");
}
}
dbg!(size_of::<&Cat>());//size_of::<&Cat>() = 8
dbg!(size_of::<&dyn Animal>());//size_of::<&dyn Animal>() = 16
在这种情况下,fat pointer类似于:
struct TraitObjectRef {
data_ptr: *const (),
vptr: *const (),
}
其中data_ptr指向实际的结构体,vptr指向trait包含的方法。
最后,我们通过如下一段代码来探究特征对象的底层内存模型。
struct Dog {
name: String,
age: i8,
}
struct Cat {
lives: i8,
}
trait Pet {
fn talk(&self) -> String;
}
impl Pet for Dog {
fn talk(&self) -> String {
format!("Woof, my name is {}!", self.name)
}
}
impl Pet for Cat {
fn talk(&self) -> String {
String::from("Miau!")
}
}
fn main() {
let pets: Vec<Box<dyn Pet>> = vec![
Box::new(Cat { lives: 9 }),
Box::new(Dog { name: String::from("Fido"), age: 5 }),
];
for pet in pets {
println!("Hello, who are you? {}", pet.talk());
}
}
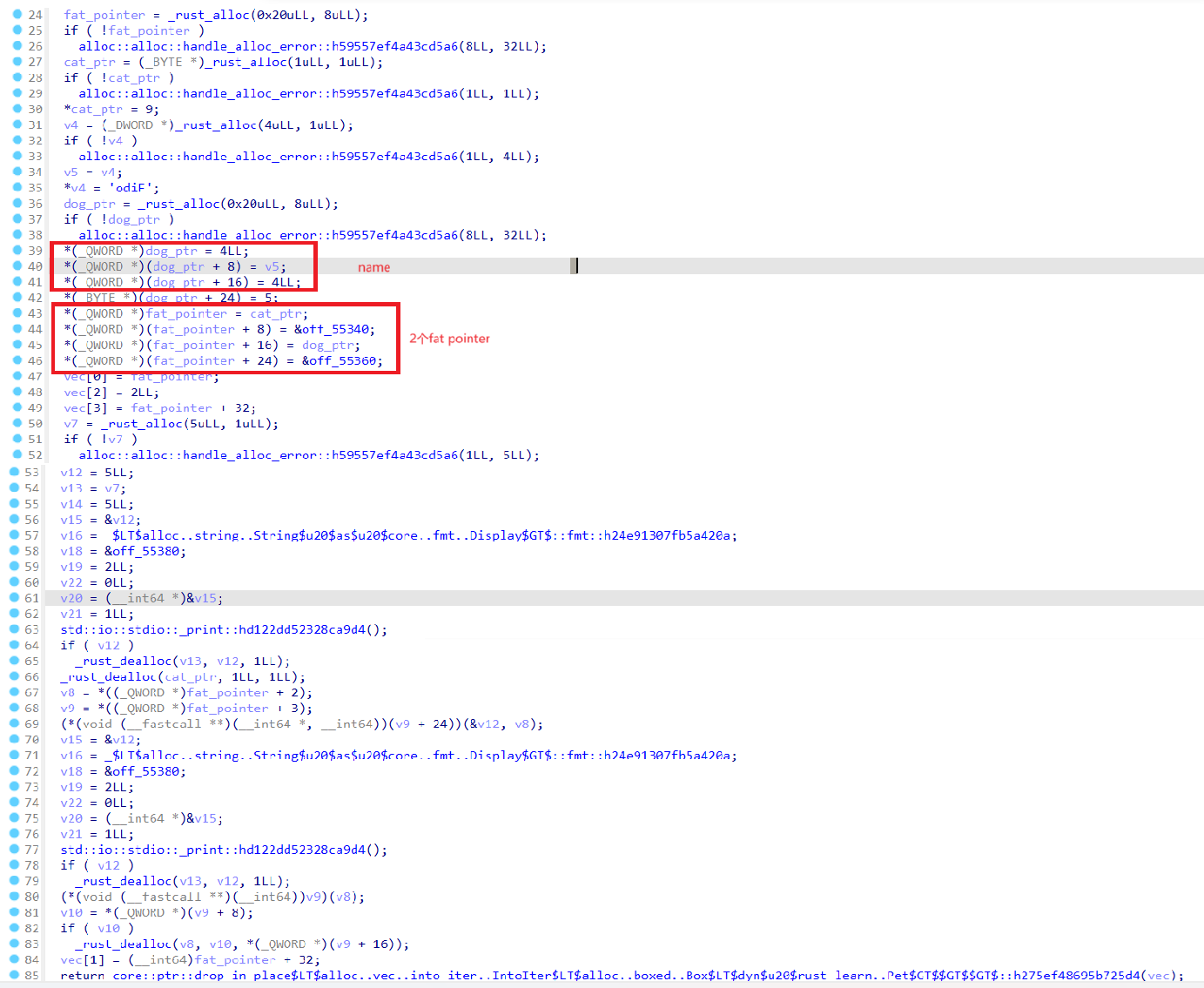
其debug模式下反编译代码如下,关键部分都由注释解释,可以看到程序存在以下操作:
- 通过exchange_malloc分配0x20大小的堆内存,vec指向该内存;
- 通过exchange_malloc分配1字节堆内存,对应的是Cat结构体;
- 通过exchange_malloc分配0x20字节堆内存,对应的Dog结构体(String类型的name占据0x18个字节,尽管age为i8类型,考虑到内存对齐,age占据0x8字节);
- 将分配的cat结构体指针和Dog结构体指针存储到vec中,可以看到这里除了存储两个结构体指针外,额外分别存储了不同的变量(分别为v0、Dog_as_Rust_learn::Pet::vtable),其类似于C++中的虚函数表,用于存储特征对象实现的特征函数。
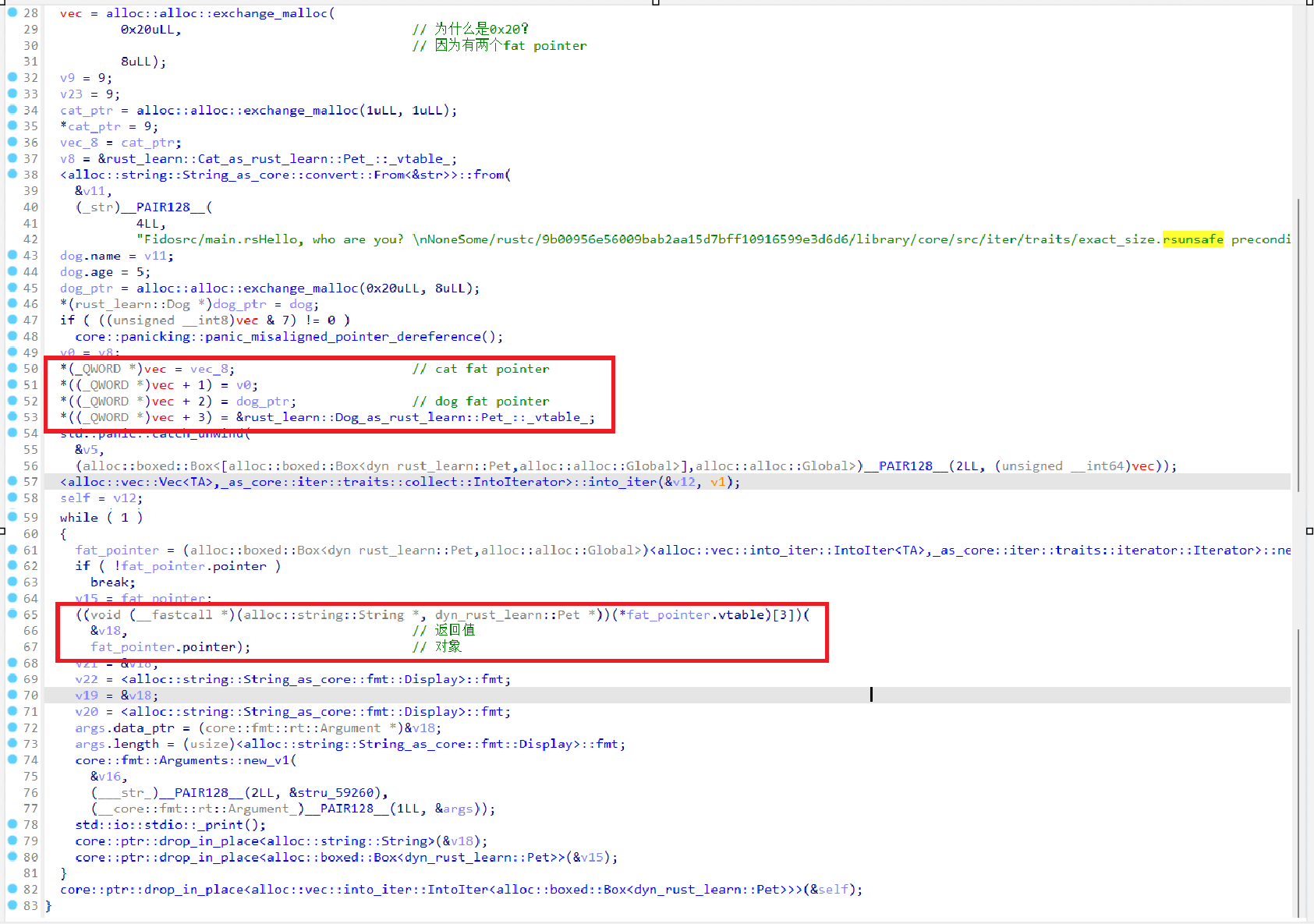
在这种情况下,Rust内存布局如下,其中vtable前0x18字节为析构函数、vtable大小以及对齐值。
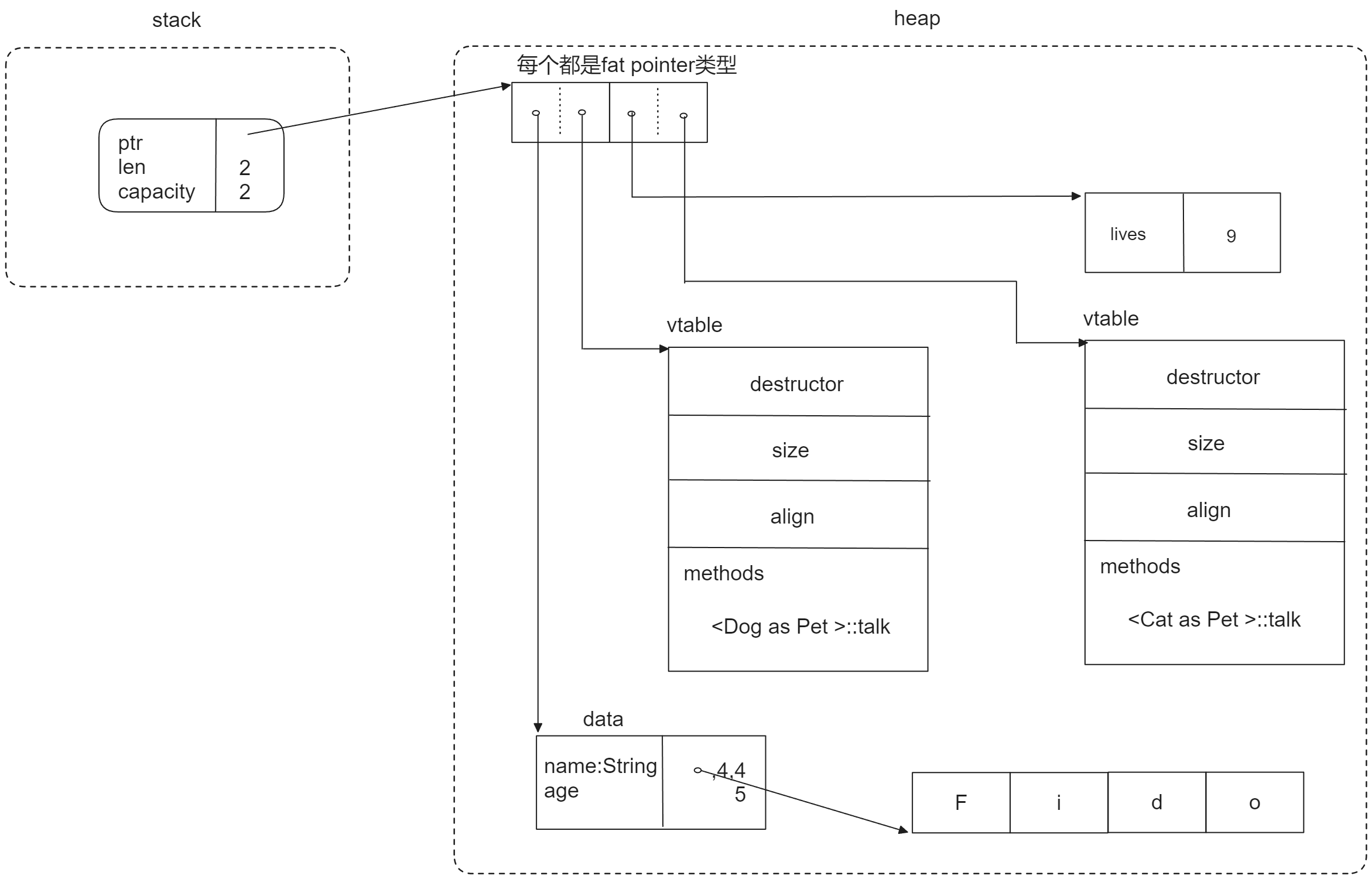
在release版本中,内存布局不会变化,但是会因为编译器的优化导致可读性非常差,例如编译器会展开循环(当循环次数不大的时候),这就会导致你看不出来这是一个循环。例如如下代码:
4.3 ENUM
Rust的enum属于tagged union,tagged union用来保存可以采用不同但固定的值的数据结构。任何时候只能使用其中一种类型,并且标记字段明确指示正在使用哪种类型。
enum DummyEnum<A, B> {
A(Box<A>),
B(Box<B>),
}
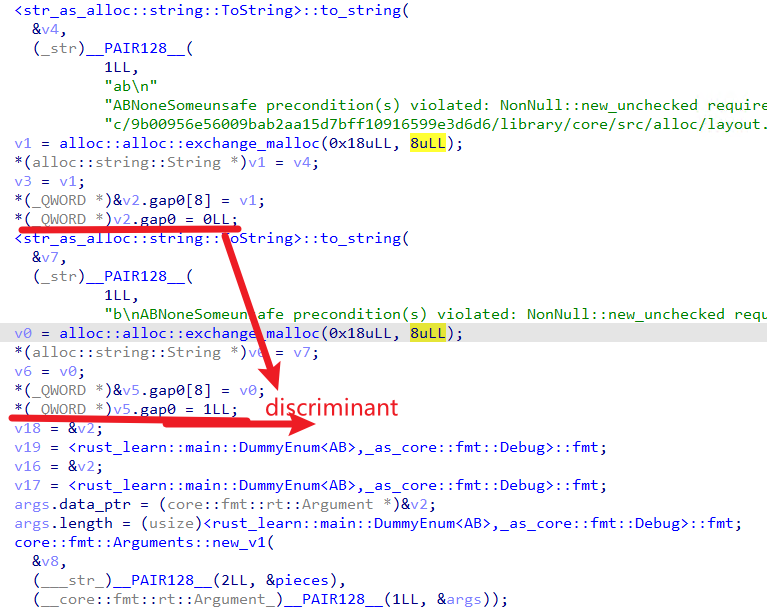
因此,在Rust中,上面的enum在反编译视角看到的内容是,通过u8类型的discriminant值来表示当前enum类型指向的实际类型。
// DummyEnum {
// is_a_or_b: u8,
// data: usize,
//
}
看这样一段代码:
enum Name{
A(String),
B(String)
}
fn main() {
let a =Name::B("a".to_string());
let a=Name::A("b".to_string());
}
其反编译代码如下,可以看到存在一个额外的数据存储discriminant。
4.4 Struct
Rust结构体内存布局与其成员变量息息相关,如果存在Vec或者String类型的成员变量,则该变量采用(ptr、capacity、length)三元组来表示,如果存在DST,则使用fat pointer来表示,看看如下的例子:
struct Data <'a>{
names: Vec<String>,
slice: &'a str,
dimension: (usize, usize),
}
let novel = String::from("Call me Ishmael. Some years ago...");
let data =Data{
names:vec!["hello".to_string(),"world".to_string()],
slice:&novel,
dimension:(1,1)
};

上图为其对应的IDA反编译结果,由于篇幅问题,这里不进行详细解释,其内存布局为:

4.5 Box
Rust智能指针内存布局类似于类似传统的指针,这里不再赘述。
4.6 Rc
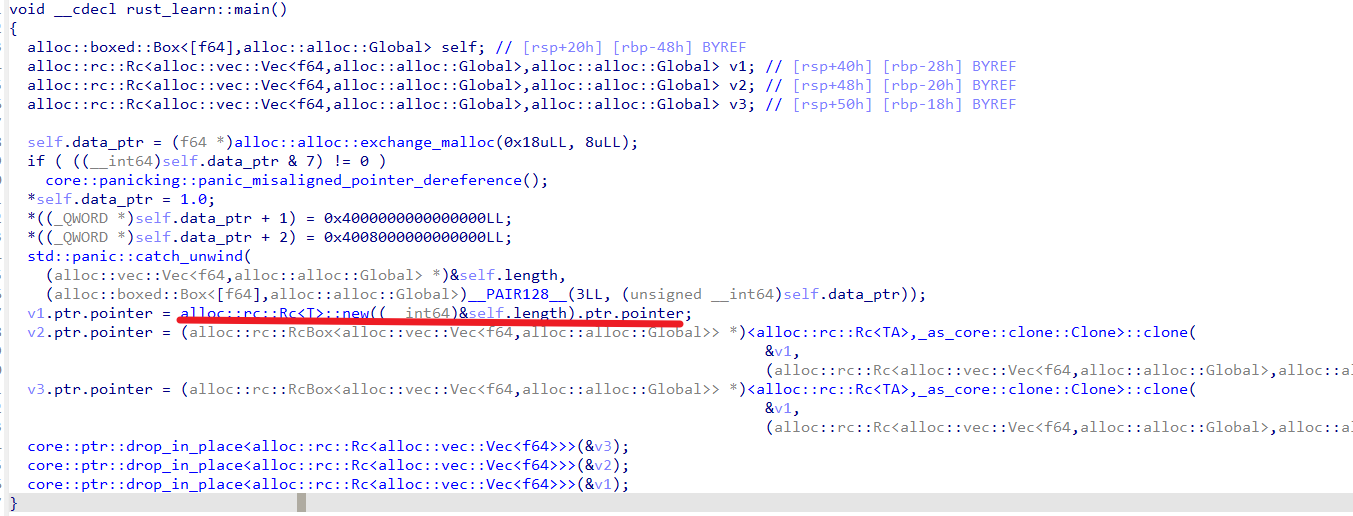
在Rust中,Rc 跟踪引用的数量,这相当于包裹在 Rc 值的所有者的数量,因此其除了指向数据之外,会存储数据对应的强引用(strong)、弱引用个数(weak)。当将 vector 包裹在智能指针 Rc 里时,用于存储 vector head 的三个机器字长(ptr、len、cap)会和引用计数一起分配到堆上。以如下的例子为例,其内存布局如下:
use std::rc::Rc;
let vec_var = vec![1.0, 2.0, 3.0];
let foo = Rc::new(vec_var);
let a = Rc::clone(&foo);
let b = Rc::clone(&foo);

实际上通过源代码就可以窥探到Rc的内存布局,下图展示了Rc的相关源代码,其中PhantomData和alloc=Global都是0大小的类型,所以不占用内存, 因此逆向的时候,内存里实际看到的就是ptr指针及其指向的strong、weak以及value。
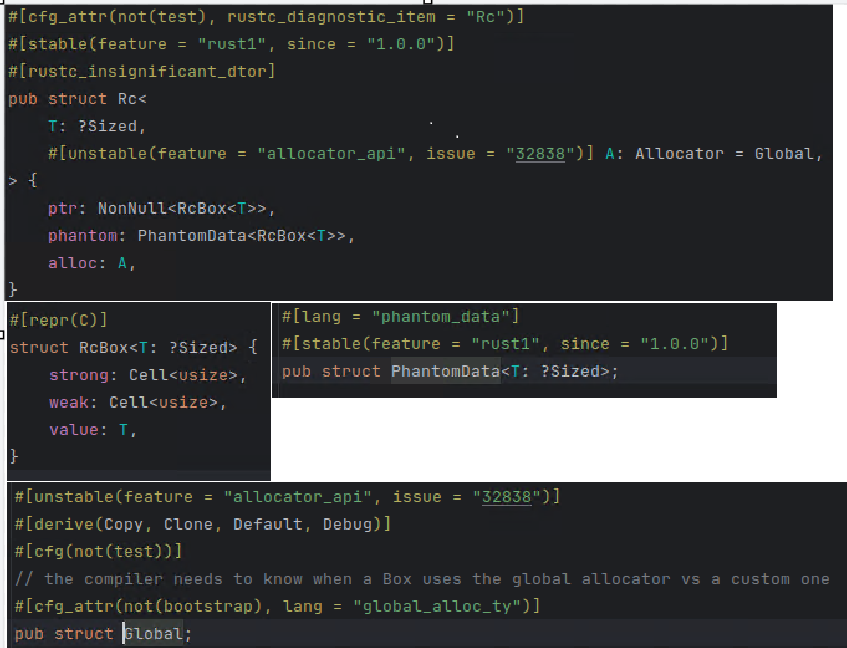
Rc在反编译代码中很容易就可以识别出来,通过Rc<T>关键词识别。
五、总结
所以,是什么让Rust这么反编译可读性很差?
正如在前言里所言,Rust 编译器的极致裁量权导致源代码与编译得到的机器码存在天壤之别,进而导致反编译算法恢复出来的伪代码与原始代码存在较大出入。在Rust各式各样的优化中,变量复用会极大的增加反编译的难度。
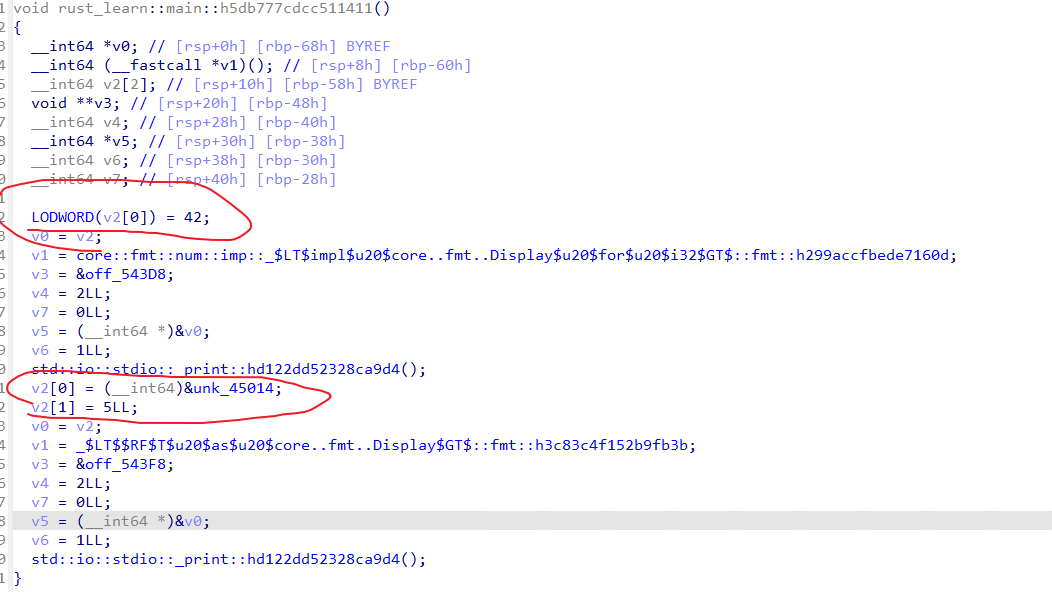
相关博客也指出了类似的问题l1nk-baby-heap-question-mark、 编译器stack rebinding引入的潜在漏洞,用一个例子简单理解以下栈变量复用(stack slot reuse)。参考如下代码,main函数中同样的栈区域(由于栈重用,a与b在main函数栈的同一块区域)指向不同类型的数据。
fn main() {
{
let a = 42; // `a` 的生命周期开始
println!("The value of a is: {}", a);
// `a` 的生命周期结束
}
{
let b = "hello"; // `b` 的生命周期开始
println!("The value of b is: {}", b);
// `b` 的生命周期结束
}
}
其反编译代码如下,可以看到v2[0]一开始指向了4字节常量42,但是后面又指向了一个字符串,类型从u32变成指针,从而造成反编译困难。