
一、Rust 简介
Rust语言自其发布以来就备受人们关注,作为一门现代的系统级编程语言,Rust在安全性方面引起了人们的极大兴趣。它与其他语言相比,引入了一系列创新的安全特性,旨在帮助开发者编写更可靠、更安全的软件。在这个基础上,许多大厂开始纷纷在自己的项目中引入Rust,比如Cloudflare的pingora,Rust版的git – gitxoide,连微软都提到要将自家的win32k模块用rust重写,足以见得其火爆程度。
之所以人们对Rust那么充满兴趣,除了其强大的语法规则之外,Rust提供了一系列的安全保障机制也让人非常感兴趣,其主要集中在以下几个方面:
- 内存安全:Rust通过使用所有权系统和检查器等机制,解决了内存安全问题。它在编译时进行严格的借用规则检查,确保不会出现数据竞争、空指针解引用和缓冲区溢出等常见的内存错误。
- 线程安全:Rust的并发模型使得编写线程安全的代码变得更加容易。它通过所有权和借用的机制,确保在编译时避免了数据竞争和并发问题,从而减少了运行时错误的潜在风险。
- 抽象层安全检测:Rust提供了强大的抽象能力,使得开发者能够编写更加安全和可维护的代码。通过诸如模式匹配、类型系统、trait和泛型等特性,Rust鼓励使用安全抽象来减少错误和提高代码的可读性。
Rust强大的编译器管会接管很多工作,从而尽可能的减少各种内存错误的诞生。
二、Rust 不会出现漏洞吗?
在 Rust 的各类机制下,开发人员在编译阶段被迫做了相当多的检查工作。同时在 Rust 的抽象机制下,整体的开发流程得到了规范,理论上应该是很难再出现漏洞了。然而,安全本质其实是人,错误本质上是由人们的错误认知引发的。即便是在 Rust 的保护之下,人们也是有可能犯错,从而导致新的问题的出现。对于这种场景,我们可以用一种宏观的方法论来概括,那就是认知偏差。这里可以用一个图来大致描述一下这个认知偏差:

换句话说,在使用Rust开发中,人们认为Rust能够提供的防护和Rust实际上提供的防护,这两者存在一定的差异。具体来说,可以有一下几种场景:
- Rust 检查时,能否防护过较为底层的操作状态?
- Rust 自身特性是否会引入问题?
- Rust 能否检查出作为mod 或者 API被其他人调用时,也能完全保护调用安全吗?
为了能够更好的了解认知差异,接下来我们就介绍几种比较典型的 Rust 下容易出现的漏洞。
三、漏洞案例一:对操作系统行为错误的认知
再进行开发过程中,Rust 通常会需要与操作系统底层进行交互。然而在这些操作过程中,本质上是对底层的API 或者对底层操作系统的操作,此时考察的是开发者对于操作系统的理解。而Rust编译器的防护机制并无法直接作用于这些底层的操作系统对象,从而会导致错误的发生。
一种常见的认知偏差就是默认操作系统提供的特性,比如说接下来要提到的特殊字符过滤规则。
3.1 BatBadBut(CVE-2024-24576)
在2024年4月,安全研究员RyotaK公开了一种他发现现有大部分高级语言中常见的漏洞类型,取名为BatBadBut,其含义为batch文件虽然糟糕,但不是最糟糕的。
batch files and bad, but not the worst
在Windows下,想要执行bat文件就必须要启动一个cmd.exe,所以执行的时候通常会变成cmd.exe /c test.bat。
每个高级语言在Windows平台下需要创建新的进程的时候,最终都会调用Windows的APICreateProcess。为了防止命令注入,它们大多数会对参数进行一定的限制,然而Windows平台下的CreateProcess存在一定的特殊行为,使得一些常见的过滤手段依然能够被绕过。作者给了一个nodejs的例子,在nodejs中,当进行进程创建的时候,通常是这样做的
const { spawn } = require('child_process');
const child = spawn('echo', ['hello', 'world']);
这种做法通常是没问题的,此时由CreateProcess创建的进程为echo,参数为后续的两个参数。同时,这个调用过程中伴随的如下的过滤函数,会将"过滤成\"
/*
* Quotes command line arguments
* Returns a pointer to the end (next char to be written) of the buffer
*/
WCHAR* quote_cmd_arg(const WCHAR *source, WCHAR *target) {
/*
* Expected input/output:
* input : hello"world
* output: "hello\"world"
* output: "hello world\\"
*/
}
此时,上述的指令会形成如下的指令:
echo "hello" "world"
然而,当遇到如下代码的时候,情况会发生变化:
const { spawn } = require('child_process');
const child = spawn('./test.bat', ['"&calc.exe']);
因为 Windows 并没有办法直接的启动一个bat文件,所以实际上启动的时候,Windows执行的实际逻辑变成了
cmd.exe /c ""test.bat "\"&calc.exe"
而实际上,在Windows中的\并非是我们理解的那种能将所有符号进行转义,转义字符。其只能转义\本身,类似于作为路径的时候,以及转义换行符。所以,上述的命令实际上等价于:
cmd.exe /c ""test.bat ""&calc.exe"
此时命令解析模式如下:
cmd.exe /c ""test.bat"" & calc.exe"
| | | |
+--------+------------+---+---+----+----+
| | |
v v v
这个部分为cmd /c 解析 &符号 calc.exe执行
可见依然发生了命令注入。实际上,如果想要在Windows下进行我们常规理解下的命令转换,要使用^符号,例如将上述指令修改成如下的形式,即可防止命令注入:
cmd.exe /c test.bat "^"^&calc.exe"
作者给出了他测试过的受到影响的语言:
- Erlange
- Go
- Haskell
- Java
- Node.js
- PHP
- Python
- Ruby
- Rust
这些语言的内置Execute或者Command函数都或多或少会受到影响。
3.2 Rust CVE-2024-24576
Rust也有这样的问题,所以进行了紧急修复,但是Rust一开始似乎是意识到了.bat的特异性行为,还给出了相关处理函数:
pub(crate) fn make_bat_command_line(
script: &[u16],
args: &[Arg],
force_quotes: bool,
) -> io::Result<Vec<u16>> {
// Set the start of the command line to `cmd.exe /c "`
// It is necessary to surround the command in an extra pair of quotes,
// hence the trailing quote here. It will be closed after all arguments
// have been added.
let mut cmd: Vec<u16> = "cmd.exe /d /c \"".encode_utf16().collect();
// skip some code
for arg in args {
cmd.push(' ' as u16);
// Make sure to always quote special command prompt characters, including:
// * Characters `cmd /?` says require quotes.
// * `%` for environment variables, as in `%TMP%`.
// * `|<>` pipe/redirect characters.
const SPECIAL: &[u8] = b"\t &()[]{}^=;!'+,`~%|<>";
let force_quotes = match arg {
Arg::Regular(arg) if !force_quotes => arg.bytes().iter().any(|c| SPECIAL.contains(c)),
_ => force_quotes,
};
append_arg(&mut cmd, arg, force_quotes)?;
}
}
然而它在处理的过程中,并未对双引号正确处理,而是同样使用了\:
fn append_arg()
for x in arg.encode_wide() {
if escape {
if x == '\\' as u16 {
backslashes += 1;
} else {
if x == '"' as u16 {
// Add n+1 backslashes to total 2n+1 before internal '"'.
cmd.extend((0..=backslashes).map(|_| '\\' as u16));
}
backslashes = 0;
}
}
cmd.push(x);
}
在这边,错误的使用了\\作为过滤字符,所以同样导致了问题的出现。
这里参考网上流传的poc:
use std::io::{self, Write};
use std::process::Command;
fn main() {
println!("enter payload here");
let mut input = String::new();
io::stdout().flush().expect("Failed to flush stdout");
io::stdin().read_line(&mut input).expect("Failed to read from stdin");
let output = Command::new("./test.bat")
.arg(input.trim())
.output()
.expect("Failed to execute command");
println!("Output:\n{}", String::from_utf8_lossy(&output.stdout));
}
当我们传入"&calc.exe时候就能弹出计算器,此时观察命令行的参数可以看到如下的内容:
cmd.exe /d /c ""D:\CVE-2024-24576\target\debug\test.bat" "\"&calc.exe""
Rust给出的修复在这边。经分析,可以知道主要是引入了函数append_bat_arg,在对各种字符串做了过滤之后,假设遇到双引号,则再次插入另一个,从而阻止绕过的发生:
// Loop through the string, escaping `\` only if followed by `"`.
// And escaping `"` by doubling them.
let mut backslashes: usize = 0;
for x in arg.encode_wide() {
if x == '\\' as u16 {
backslashes += 1;
} else {
if x == '"' as u16 {
// Add n backslashes to total 2n before internal `"`.
cmd.extend((0..backslashes).map(|_| '\\' as u16));
// Appending an additional double-quote acts as an escape.
cmd.push(b'"' as u16);
}
}
}
3.3 认知错误分析
实际上,这个漏洞本身和Rust关联不大,但是我们仍然可以用这个认知模型对这个漏洞进行分析:
- 开发人员认知:Windows中,
\与Linux下含义相同 - 实际运行环境:Windows中的
^与Linux下\语义相同
这种对于操作系统的认知差异导致了这个问题的出现。
四、漏洞案例二:对特性的认知错误
4.1 内存重排序问题
在之前的文章中 提到过,Rust的结构体的变量顺序可能会由于内存对齐问题进行重排序,这边简单复习一下,假设存在结构体:
struct TestStruct {
field1: u8,
field2: u32,
field3: u16,
}
上述结构体如果在C里面写的话,可以写作如下的形式:
struct test
{
char a;
int b;
short c;
};
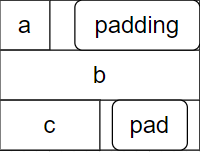
此时,这个结构体的大小是什么呢?
实际上,假设我们打印结构体的大小和偏移,会得到这个答案:
Size of struct test: 12 bytes
Offset of 'a': 0 bytes
Offset of 'b': 4 bytes
Offset of 'c': 8 bytes
因为结构体对齐的时候,会遵顼三个原则:
- 第一个成员的起始地址为0
- 每个成员的首地址为自身大小的整数倍
- 总大小为成员大小的整数倍
由于b的起始地址必须是4对齐,所以所有的变量都被迫进行了4字节对齐,从而形成了这个状态。
那么这个结构体在Rust中的内存排布是如何的呢?
struct TestStruct {
field1: u8,
field2: u32,
field3: u16,
}
如果我们尝试打印他们的偏移的话,可以得到如下的结果:
let foo = TestStruct {
field1: 12,
field2: 3, // Using u32 to store char as its ULE representation
field3: 456,
};
println!("Size of TestStruct: {}", size_of::<TestStruct>());
println!("Offset of 'field1': {}", offset_of!(TestStruct, field1));
println!("Offset of 'field2': {}", offset_of!(TestStruct, field2));
println!("Offset of 'field3': {}", offset_of!(TestStruct, field3));
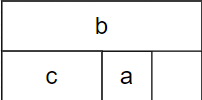
Size of TestStruct: 8
Offset of 'field1': 6
Offset of 'field2': 0
Offset of 'field3': 4
从IDA中看,也可看到类似的结果:
TestStruct[6] = 12;
*(_DWORD *)TestStruct = 3;
*(_WORD *)&TestStruct[4] = 456;
可以看到field2和field3的偏移发生了变化,其原因源自于之前提到过的对齐特性,Rust会尽可能的缩小结构体大小,会因此调换结构体成员的变量顺序,从而保证结构体尽可能地小。
4.2 repr
然而在实际开发中,我们有时候不需要编译器对我们的结构体进行操作,此时可以通过声明:
#[repr(C)]
关键字,强行让结构体排序不发生变化。
同时,我们可以看到,Rust还是尽可能地保证了结构体在4/8字节上的对齐,然而在某些场景中,我们可能希望结构体能够尽可能地小,此时可以声明:
#[repr(packed)]
来强行要求结构体不要保留padding。这两种做法都是非常常见的。
4.3 RUSTSEC-2024-0346
这个漏洞出现在 Rust 下的一个zerovec 模块中,这个模块特点为零拷贝,本质上是对现有对象进行引用以及一些序列化相关的操作。
根据文档,zerovec的底层核心是一个叫做ULE的特征辅助实现的,其实现大致如下:
pub unsafe trait ULE
where
Self: Sized + Copy + 'static,
{
// Required
fn validate_byte_slice(bytes: &[u8]) -> Result<(), ZeroVecError>;
// Some automatically provided methods elided
}
这个特征要求利用unsafe 的函数直接的获取对应的字节流是否有效。在这基础上,如果我们将要包含的数据大小是不定长的,则需要实现VarULE这一个特性:
pub unsafe trait VarULE: 'static {
fn validate_byte_slice(_bytes: &[u8]) -> Result<(), ZeroVecError>;
unsafe fn from_byte_slice_unchecked(bytes: &[u8]) -> &Self;
// Some automatically provided methods elided
}
这个函数会要求对底层的数据进行一些操作从而完成进行数据拷贝,所以底层可以理解会存在【序列化】的过程。
该漏洞提供的POC如下:
use std::str::FromStr;
use icu_calendar::Date;
use icu_datetime::{options::length, DateFormatter};
use icu_locid::Locale;
fn main() {
let locale = Locale::from_str("en-u-ca-japanese").unwrap();
let formatter = DateFormatter::try_new_with_length(&locale.into(), length::Date::Full).unwrap();
let date = Date::try_new_iso_date(2020, 5, 30).unwrap().to_any();
dbg!(formatter.format_to_string(&date).unwrap());
}
上述这段代码逻辑基本上就是做了一个时间格式化,然而在底层却触发了断言,导致了崩溃。经过开发者定位,最终确定有问题的数据结构如下:
#[cfg_attr(feature = "serde", derive(serde::Deserialize))]
pub struct JapaneseErasV1<'data> {
/// A map from era start dates to their era codes
#[cfg_attr(feature = "serde", serde(borrow))]
pub dates_to_eras: ZeroVec<'data, (EraStartDate, TinyStr16)>,
}
在这段代码中,成员dates_to_eras对应的ZeroVec所关联的结构体就是Tuple(EraStartDate, TinyStr16),这两个结构体定义如下:
pub struct EraStartDate {
/// The year the era started in
pub year: i32,
/// The month the era started in
pub month: u8,
/// The day the era started in
pub day: u8,
}
pub type TinyStr16 = TinyAsciiStr<16>;
#[repr(transparent)]
#[derive(PartialEq, Eq, Ord, PartialOrd, Copy, Clone, Hash)]
pub struct TinyAsciiStr<const N: usize> {
bytes: [AsciiByte; N],
}
可以看到,EraStartDate为8字节,而TinyStr16为16字节。而在ZeroVec中,其使用了宏来处理这种情况:
//! # Examples
//!
//! ```
//! use zerovec::ZeroVec;
//!
//! // ZeroVec of tuples!
//! let zerovec: ZeroVec<(u32, char)> = [(1, 'a'), (1234901, '啊'), (100, 'अ')]
//! .iter()
//! .copied()
//! .collect();
//!
//! assert_eq!(zerovec.get(1), Some((1234901, '啊')));
//! ```
macro_rules! tuple_ule {
($name:ident, $len:literal, [ $($t:ident $i:tt),+ ]) => {
#[doc = concat!("ULE type for tuples with ", $len, " elements.")]
#[repr(packed)] // 注意这里
#[allow(clippy::exhaustive_structs)]
pub struct $name<$($t),+>($(pub $t),+);
可以看到,当遇到tuple类型的时候,ZeroVec会使用packed关键字将其封装,从而保证数据占用空间的大小不会太大。 由于是tuple,所以这里的结构体中不存在对应的实际成员,使用的时候只能使用self.0或者self.1来操作对应的EraStartDate和TinyStr16。 然而,这里的tuple却并不如我们看到的那样排序,当加上packed关键字后,其会发生一个重排序的过程,例如下面代码:
// #[derive(Debug)]
#[repr(packed)]
pub struct EraStartDate {
/// The year the era started in
pub year: i32,
/// The month the era started in
pub month: u8,
/// The day the era started in
pub day: u8,
}
// #[repr(C)]
#[repr(packed)]
// #[repr(packed,C)]
pub struct TestTuple(EraStartDate, [AsciiByte; 16]);
实际运行起来的时候,我们会得到如下的结果:
Tuple Size: 22
EraStartDate Size: 6
EraStartDate Offset: 16
TinyStr16 Size: 16
TinyStr16 Offset: 0
此时可以发现,EraStartDate和TinyStr16的顺序发生了颠倒。那么此时在使用tuple来操作对象的时候,原先位于0位置的EraStartDate就变成了TinyStr16,从而造成了漏洞的产生。
4.4 修复策略与认知差异分析
实际上,这个漏洞的修复非常简单,是需要将声明改成:
#[repr(C,packed)]
即可强迫Rust使用C语言的内存排序对其进行严格的顺序声明,从而阻止这类漏洞的产生。
如果从认知差异的角度触发,这个漏洞其实就是一种非常典型的认知差异,表现为对语言特性理解的差异:
- 开发人员认知:Rust中,
packed字段未提及重排序,所以不会发生重排序问题 - 实际运行环境:Rust中,
packed字段不会决定排序,所以可能发生重排序
实际上,现在去Rust官网阅读文档也会发现,packed关键字明确提到了可能会发生重排序。然而开发者们在开发的过程中,依然可能存在记忆混淆等认知错误的问题,从而导致漏洞本身的出现。
五、漏洞案例三:对生命周期的错误认知
5.1 CVE-2024-27284
这个漏洞是Casandra-rs中的问题。
由于没有PoC,所以只能推测漏洞点的大致位置
这个库是一个分布式数据库的Rust封装实现。由于数据库操作不可避免的要与数据库操作,所以有大量底层数据操作,因此引入了unsafe关键字,并且有很多迭代器存在,这个过程中就会导致漏洞的出现。
漏洞的关键点在于迭代器的误用,分析patch可以看到这样的逻辑:
- impl<'a> Iterator for ResultIterator<'a> {
- type Item = Row<'a>;
- fn next(&mut self) -> Option<<Self as Iterator>::Item> {
+ impl LendingIterator for ResultIterator<'_> {
+ type Item<'a> = Row<'a> where Self: 'a;
+
+ fn next(&mut self) -> Option<<Self as LendingIterator>::Item<'_>> {
unsafe {
match cass_iterator_next(self.0) {
cass_false => None,
cass_true => Some(self.get_row()),
}
}
}
- impl<'a> ResultIterator<'a> {
- /// Gets the next row in the result set
- pub fn get_row(&mut self) -> Row<'a> {
+ impl ResultIterator<'_> {
+ /// Gets the current row in the result set
+ pub fn get_row(&self) -> Row {
unsafe { Row::build(cass_iterator_get_row(self.0)) }
}
这里有几个比较明显的修复特征
- Iterator 切换成了 LendingIterator
- Item定义有了微妙的变化,但是始终和
Raw<'a>相关 get_row的返回值由Row<'a>换成了Row
我们这里可以全部过一遍这些修复点: 首先是这里的LendingIterator,其实是其内部实现的一个特殊的数据结构:
pub trait LendingIterator {
type Item<'a>
where
Self: 'a;
}
这样声明后,迭代器的生命周期就会被强制与其Item指向的对象生命周期保持一致。
其次,这里提到了Raw<'a>定义如下:
- pub struct Row<'a>(*const _Row, PhantomData<&'a CassResult>);
+ pub struct Row<'a>(*const _Row, PhantomData<&'a _Row>);
可以看到,原先的Row关联的生命周期为CassResult,而新的Row关联的生命周期为_Row。
然后,这个get_row所操作的是一个unsafe对象,这个对象来自cpp部分:
const CassRow* cass_iterator_get_row(const CassIterator* iterator) {
if (iterator->type() != CASS_ITERATOR_TYPE_RESULT) {
return NULL;
}
return CassRow::to(static_cast<const ResultIterator*>(iterator->from())->row());
}
class ResultIterator : public Iterator {
ResultIterator(const ResultResponse* result)
, result_(result)
, row_(result) {
}
const Row* row() const {
assert(index_ >= 0 && index_ < result_->row_count());
if (index_ > 0) {
return &row_;
} else {
return &result_->first_row();
}
}
const ResultResponse* result_;
Row row_; // < ----- 注意这里
};
get_row会返回一个Row对象,这个row对象来自于ResultIterator这个结构体中定义的row对象,此时我们可以知道,结构体关系如下:
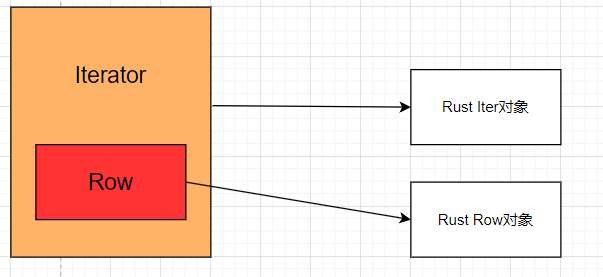
此时可以得出一个结论:
ResultIterator和Row公用一段内存空间
同时,根据之前修改的代码,可以观察到这里修改:
- impl<'a> Iterator for ResultIterator<'a> {
- type Item = Row<'a>;
- fn next(&mut self) -> Option<<Self as Iterator>::Item> {
+ impl LendingIterator for ResultIterator<'_> {
+ type Item<'a> = Row<'a> where Self: 'a;
+
+ fn next(&mut self) -> Option<<Self as LendingIterator>::Item<'_>> {
这两个迭代器虽然都关联了Row<'a>,但是这个对象的定义同样发生了变化:
- pub struct Row<'a>(*const _Row, PhantomData<&'a CassResult>);
+ pub struct Row<'a>(*const _Row, PhantomData<&'a _Row>);
原先的Row<'a>声明的时候,与CassResult关联,这个CassResult即为我们调用数据库查询功能后,能够得到的类型,而新版本的Row<'a>则是与_Row关联,这个_Row就是前文提到过的Row指针。 同时,next函数就是迭代器在迭代过程中会自动调用获取下一个迭代对象的指针,如果我们罗列一下之前提到过的所有函数获得对象的关系,是这样的:
- get_result能够获取CassResult
- CassResult.iter() 能够获取 ResultIterator
- ResultIterator在递归过程中,通过next获取Row
然而我们在修复前,CassResult和Row的生命周期一致,但是ResultIterator和Row对象未强制要求生命周期一致, 此时漏洞触发的原因就呼之欲出:
由于未强制关联Row与ResultIterator,而ResultIterator和Row共用一套内存,当ResultIterator被销毁,Row未被销毁的场合,就会引发漏洞
总结一下,poc形式如下:
let mut tmp_row = None;
let result = function.get_result();
{
for row in result.iter() {
if condition.satisfied():
tmp_row = Some(row)
break;
}
}
println!("here will cause problem {:?}", tmp_row);
此时,由于get_result获取的CassResult未被销毁,此时对应的Row<'a>也就是tmp_row不会被Rust认为超出生命周期,然而此时的result.iter()获取的ResultIterator已经被销毁了,最终导致了UAF的产生。
我们根据上述的模型,写了一个类似的POC,形式如下:
let result = ResultSet::new();
let mut taget_row = result.iter().get_row();
for row in result.iter() {
taget_row = row;
// println!("ks name = {}", col);
break;
}
taget_row.visit();
println!("target iterator is {:?}", taget_row);
let result = ResultSet::new();
此时能够成功的触发一个UAF问题

5.2 认知错误总结
从认知差异的角度触发,这个漏洞其实是一种基于逻辑错误而导致的内存问题。其虽然与unsafe关键字关联,但是实际上它从设计层面就出现了问题,概括来讲就是
- 开发人员认知:
Row与Iterator存放在同一内存中,两者可在同一时刻释放,不会发生内存问题;Row生命周期与CassResult关联,从而保证两者生命周期长度一致,防止内存泄漏; - 实际运行环境:
Row与Iterator可能不在同一个声明域中使用,可能存在Iterator提前释放的场景。
可以猜到,在开发的时候,开发者应该着重考虑了内存泄露的问题,并且假定迭代器创建的对象会被用户拷贝,抑或是保留在指定的生命周期中,然而实际开发过程中,错误的生命周期声明会导致检查的失效,从而导致UAF问题的出现。
六、总结
Rust虽然是一个相当安全的语言,但是其安全范围是有限的,问题尤其会在人们错误的理解Rust提供的安全能力这种认知错误场合中出现。
根据我们前文的漏洞,可以总结出以下几种脱离了Rust防护机制的情形:
- 漏洞与操作系统底层关联,Rust编译器无法感知
- Rust 本身的特性导致的问题出现
- 开发者错误声明Rust生命周期的场合
通过对此类边界的观测,能够更加容易发现漏洞点,同样也能借此观测软件的防护情况, 加强软件防护。