
一、前言
权限认证是一种用于控制系统资源访问的安全机制,如果权限认证存在缺陷,将对Web应用的保密性、完整性、可用性造成严重影响。 此次分享的内容是之前挖掘国内某OA漏洞时,受tomcat下路由分发特性导致认证绕过思路影响去分析的。旨在讨论Resin URI规范化特性导致的权限认证绕过问题。
二、Servlet URL匹配模式
在 java 应用中通常通过xml声明Servlet
<Servlet>
<!-- 唯一标识这个 Servlet 的名称 -->
<Servlet-name>helloServlet</Servlet-name>
<!-- Servlet 类的全限定名 -->
<Servlet-class>com.Mmuz.helloServlet</Servlet-class>
<!-- 初始化参数(可选) -->
<init-param>
<param-name>xxx</param-name>
<param-value>Hello, World!</param-value>
</init-param>
<!-- Servlet 加载顺序(可选) -->
<load-on-startup>1</load-on-startup>
</Servlet>
<!-- URL 映射配置 -->
<Servlet-mapping>
<!-- 引用上面定义的 Servlet-name -->
<Servlet-name>helloServlet</Servlet-name>
<!-- 定义 URL 映射路径-->
<url-pattern>/hello/1.Servlet</url-pattern>
</Servlet-mapping>
也可以在类定义出上使用Servlet规范中定义的WebServlet注解去声明。

Servlet声明时可以不同类型的urlpattern,当路由请求时,Servlet 会根据不同的URL模式进行匹配。匹配方式主要有4种,优先级是精确匹配 > 路径匹配 > 后缀匹配 > 缺省匹配
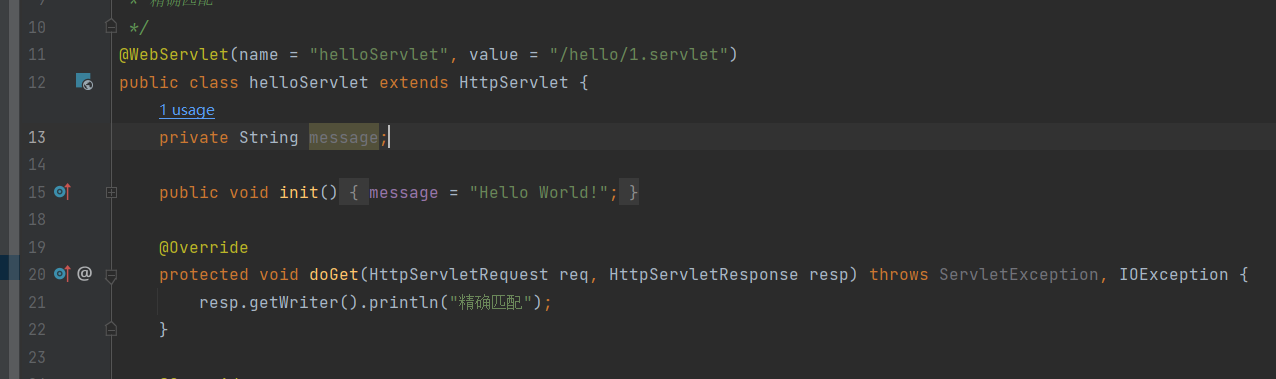
精确匹配
uri必须和url-pattern完全一致,如 /hello/1.Servlet
最长路径匹配
也叫路径匹配,指以*结尾的url-pattern,示匹配以该路径开头的所有请求,越长的路径匹配优先级越高。
/hello/*
* 由于Resin中会将*转换为 /*,所以*是路径匹配
/*
/hello/a* 匹配/hello/a/x

后缀匹配
指 .xxx 这样的,如 .jsp 、 .servlet 。

缺省匹配
指url-pattern是 / ,通常这个模式匹配所有未匹配的请求,适用于处理应用中的默认资源(如静态文件),或者用于 404 页面处理。

三、Resin Servlet 路由机制
Resin 是由 [Caucho Technology](https://www.caucho.com/) 开发的一款高性能的 Java 应用服务器(HTTP服务器+Servlet容器),广泛应用于企业级 Java 应用的部署。 Resin 相比 Tomcat 在性能和稳定性上表现更优;相比 Weblogic 架构更轻量,配置更简单,但不像 WebLogic 那样支持 Java EE 的所有规范。
Servlet容器有一个至关重要的作用是接收来自客户端(通常是Web浏览器)的HTTP请求,将这些请求解析为Servlet请求对象,然后将其路由到相应的Servlet来处理。Servlet处理后,容器会负责将其响应包装成HTTP响应并发送回客户端。以下就分析以下路由信息的维护以及路由分发过程。
3.1 Servlet-mapping添加过程
java中定义了ServletContext接口,里边提供了对Servlet、listener、filter的相关操作方法,Resin下的实现在com.caucho.server.webapp.WebApp,负责封装和管理一个独立的 Web 应用,包括应用的配置、资源、生命周期以及与 Servlet 相关的各项设置。

每个<Servlet-mapping>标签对应一个ServletMapping对象,包括Servlet-class、Servlet-name、url-pattern以及关联的Servlet实例。
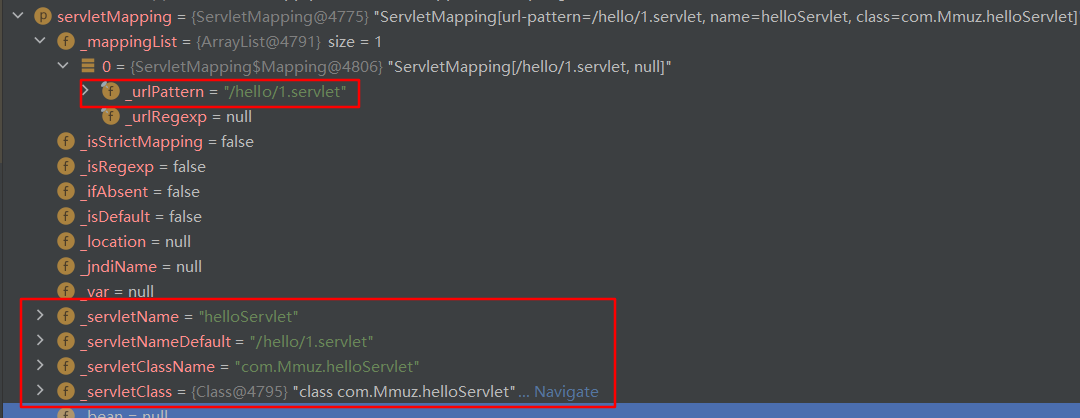
当程序启动时会调用 com.caucho.server.webapp.WebApp#addServletMapping 开始建立URL与 Servlet 实例建的映射关系。其中 init 方法接收的参数是 com.caucho.server.webapp.WebApp#_ServletMapper 成员变量,类型是 com.caucho.server.dispatch.ServletMapper ,该类作用是负责维护Web 应用中所有 ServletMapping 对象及相关信息。


init 方法中获取 urlPattern ,然后调用 ServletMapper#addUrlMapping 方法

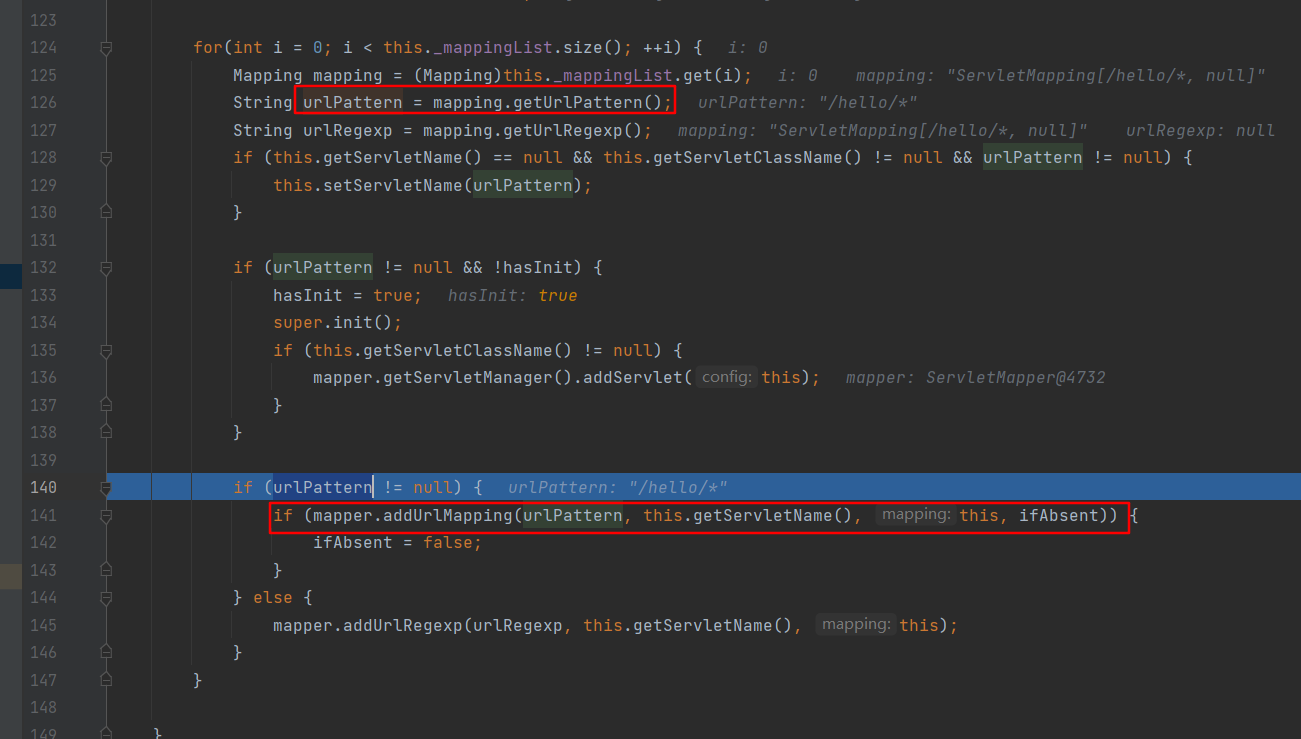
ServletMapper#addUrlMapping 中调用 _ServletMap 成员变量(类型是 com.caucho.server.dispatch.UrlMap )的 addMap 方法,传入的2个主要参数是 urlPattern 和 ServletMapping 对象。
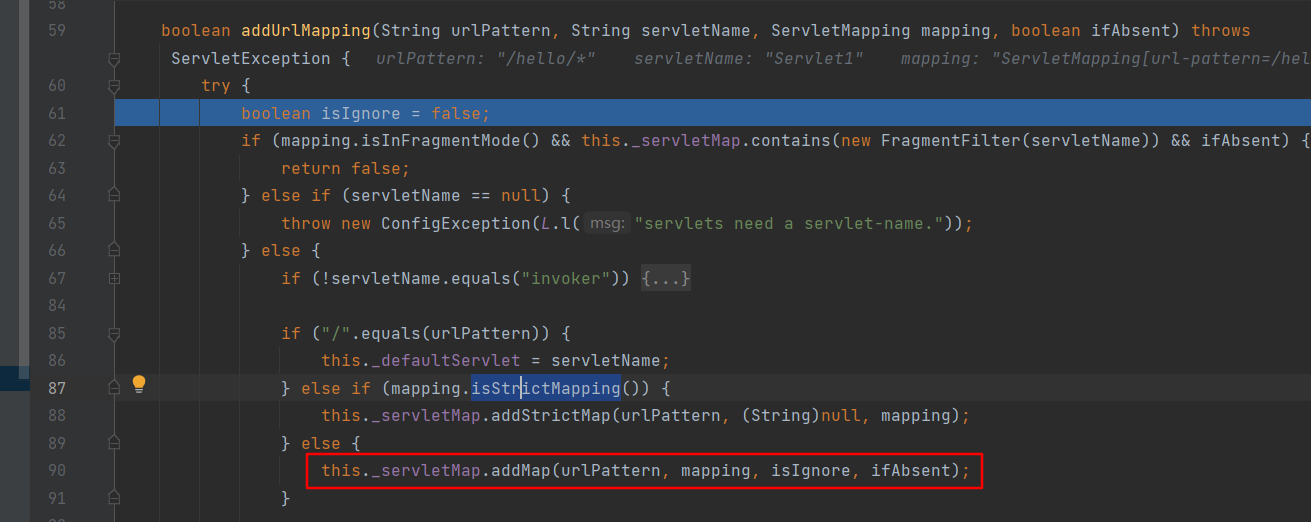
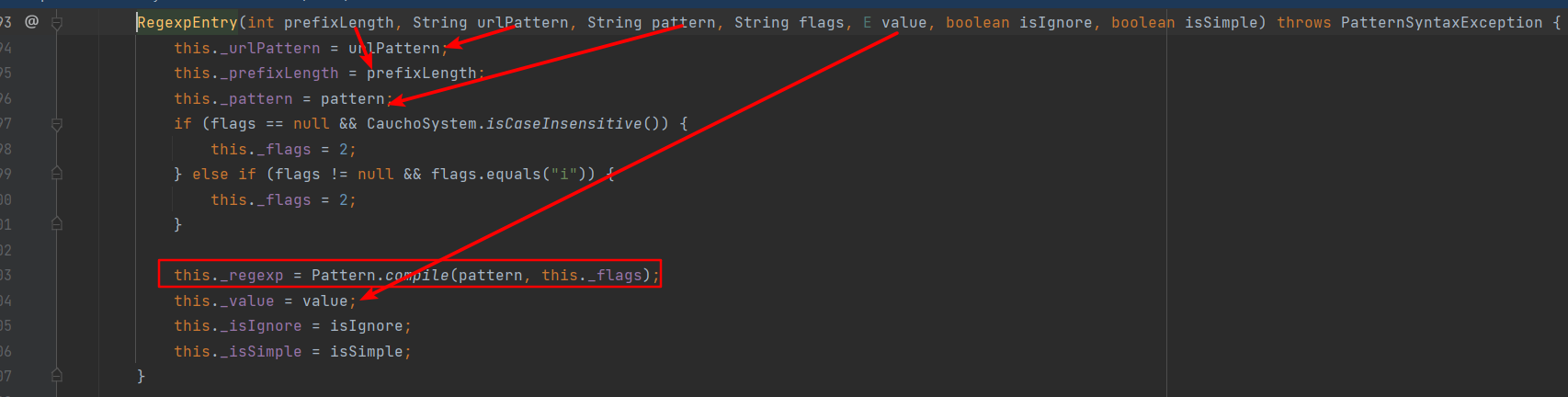
com.caucho.server.dispatch.UrlMap的_regexps成员变量中维护着其内部类com.caucho.server.dispatch.UrlMap.RegexpEntry的动态数组。RegexpEntry中存储着匹配优先级prefixlength、urlPattern、urlPattern生成的正则表达式以及和正则表达式关联的对象_value等。UrlMap和RegexpEntry类共同协作完成不同URL映射规则的存储及检索。当一个 URI 请求到达 Resin 服务器时,UrlMap 会遍历其内部存储的 RegexpEntry 对象列表,尝试使用每个 RegexpEntry 对象的正则表达式模式来匹配该 URL,如果找到匹配的 RegexpEntry 对象,则返回关联的_value。


\nUrlMap#addMap的作用是解析urlpattern转换成正则表达式cb和匹配优先级prefixLength,最后调用addRegexp方法,代码如下:
public void addMap(String pattern, String flags, E value, boolean isIgnore, boolean ifAbsent) throws PatternSyntaxException {
if (pattern.length() == 0) {
this.addRegexp(-1, "^/$", flags, value, true, isIgnore, ifAbsent);
} else {
boolean startsWithSlash = pattern.charAt(0) == '/';
//pattern 为/
if (pattern.length() == 1 && startsWithSlash) {
this.addRegexp(-1, "", flags, value, true, isIgnore, ifAbsent);
} else if (pattern.equals("/*")) {
this.addRegexp(1, "/*", flags, value, true, isIgnore, ifAbsent);
// pattern不是/也不是/*,也就是精确匹配、路径匹配、后缀匹配
} else {
int length = pattern.length();
boolean isExact = true;
if (!startsWithSlash && pattern.charAt(0) != '*') {
// 不以/开头且不以*开头就添加/
pattern = "/" + pattern;
++length;
}
int prefixLength = -1;
boolean isShort = false;
boolean hasWildcard = false;
CharBuffer cb = new CharBuffer();
cb.append("^");
for(int i = 0; i < length; ++i) {
char ch = pattern.charAt(i);
// pattern最后一位是*
if (ch == '*' && i + 1 == length && i > 0) {
hasWildcard = true;
isExact = false;
// pattern 以/*结尾,也就是路径匹配
if (pattern.charAt(i - 1) == '/') {
cb.setLength(cb.length() - 1);
if (prefixLength < 0) {
prefixLength = i - 1;
}
} else if (prefixLength < 0) {
// 形如/abc/a*,则prefixLength就是pattern删除最后一个*的长度
prefixLength = i;
}
if (prefixLength == 0) {prefixLength = 1;}
// *不在pattern最后一位,例如后缀匹配
} else if (ch == '*') {
hasWildcard = true;
isExact = false;
cb.append(".*");
if (prefixLength < 0) {prefixLength = i;}
//以*开头,即后缀匹配,标记isshort为true
if (i == 0) {isShort = true;}
//以下非正则字符,直接添加进cb
} else if (ch != '.' && ch != '[' && ch != '^' && ch != '$' && ch != '{' && ch != '}' && ch != '|' && ch != '(' && ch != ')' && ch != '?') {
cb.append(ch);
//正则字符添加\转义
} else {
cb.append('\\');
cb.append(ch);
}
}
//精确匹配生成正则最后一位添加$
if (isExact) {cb.append("$");
//其他情况 添加(?=/)|和\z
} else {
cb.append("(?=/)|" + cb.toString() + "\\z");
}
if (prefixLength < 0) {
prefixLength = pattern.length();
} else if (prefixLength < pattern.length() && pattern.charAt(prefixLength) == '/') {
--prefixLength;
}
if (cb.length() > 0 && cb.charAt(0) == '/') {
cb.insert(0, '^');
}
this.addRegexp(prefixLength, pattern, cb.close(), flags, value, isShort, isIgnore, ifAbsent, !hasWildcard);
}
}
}
prefixLength是根据urlpattern中从左到右连续的必须要存在的路径(暂且称作确定路径)的长度表示的,长度越大优先级越高。以下是精确匹配、路径匹配、后缀匹配生成正则的例子:
| 规则类型 | 确定路径 | prefixLength | 正则 | |
|---|---|---|---|---|
| /hello/1.Servlet | 精确匹配 | /hello/1.Servlet | 16=len(确定路径) | ^/hello/1\.Servlet$ |
| /hello/* | 路径匹配 | /hello/ | 5=len(确定路径)-2 | ^/hello(?=/)|^/hello\z |
| *.jsp | 后缀匹配 | 无 | 0 | ^.*\.jsp(?=/)|^.*\.jsp\z |
Resin解析漏洞xxxx.jsp/xxxx会路由到xxx.jsp就是生成的正则表达式用正向先行断言(?=/)导致xxxx.jsp/xxxx可以匹配到`^.*\.jsp(?=/)|^.*\.jsp\z正则表达式引起的。

UrlMap#addRegexp中新建一个RegexpEntry对象维护到_regexps属性中,此时_value是ServletMapping对象。

3.2 Servlet路由过程
当java应用启动完毕,用户访问一个url时,Resin则需要根据url匹配并路由到对应Servlet上,总共分两步
- 根据uri匹配到正确的ServletMapping,构建Invocation对象
- 路由分发到Servlet的service方法上
路由分发在HttpRequest#handleRequest中,先通过getInvocation方法获取响应的Invocation对象,然后再调用service方法去路由。

getInvocation方法根据uri(指去掉webapp路径的uri))获取构建Invocation对象,构建成功后加入缓存中,之后访问该uri不需要再次构建。
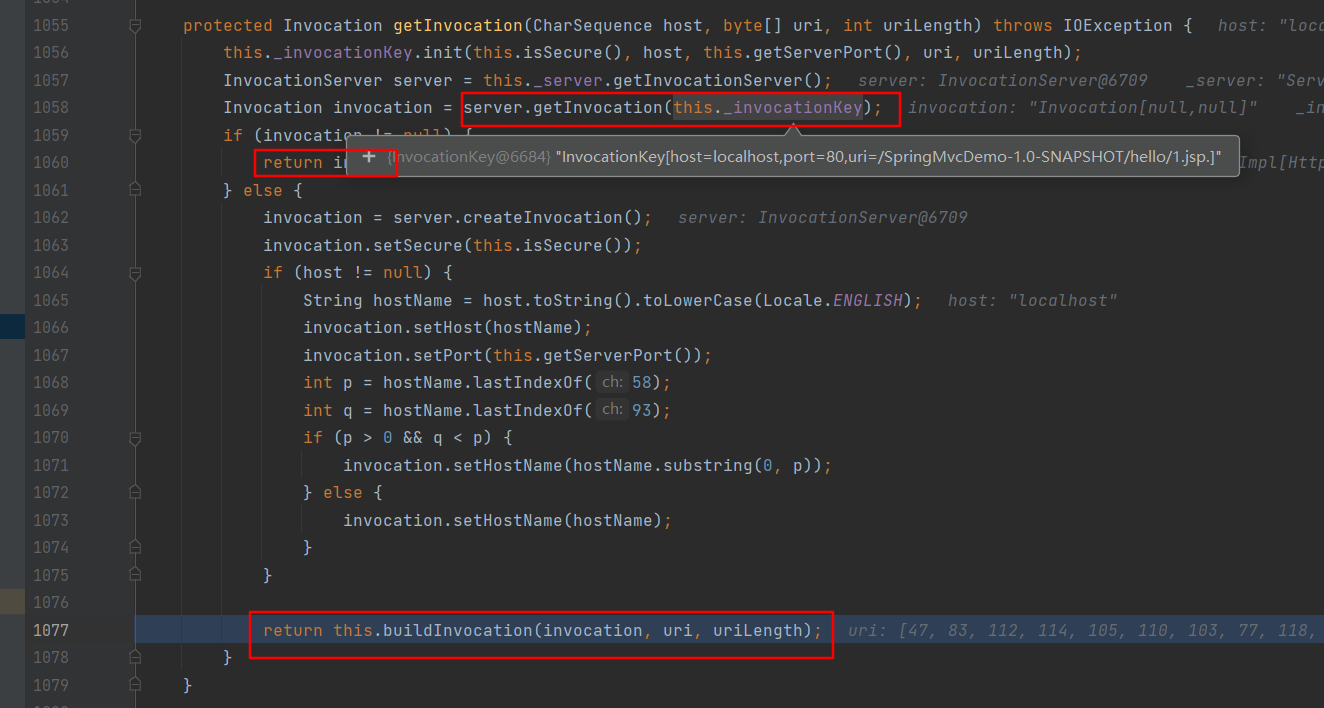
AbstractHttpRequest#buildInvocation中先调用decoder.splitQueryAndUnescape,然后再调用后buildInvocation
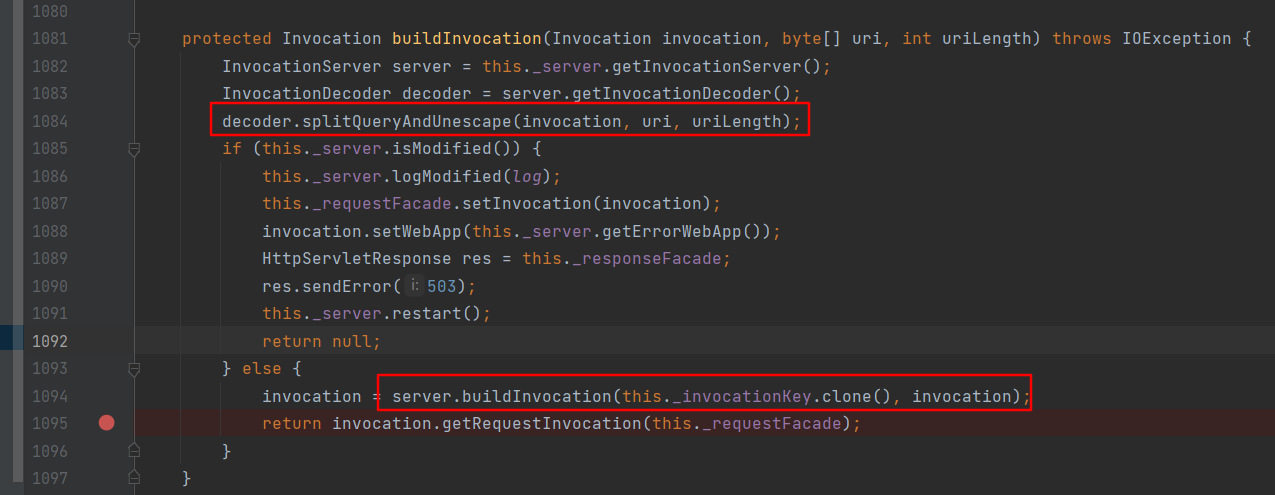
\nInvocationDecoder#splitQueryAndUnescape中先调用normalizeUriEscape方法url解码一次,再调用normalizeUri方法对进行规范化处理,之后设置为Invocation的URI和contextURI属性。
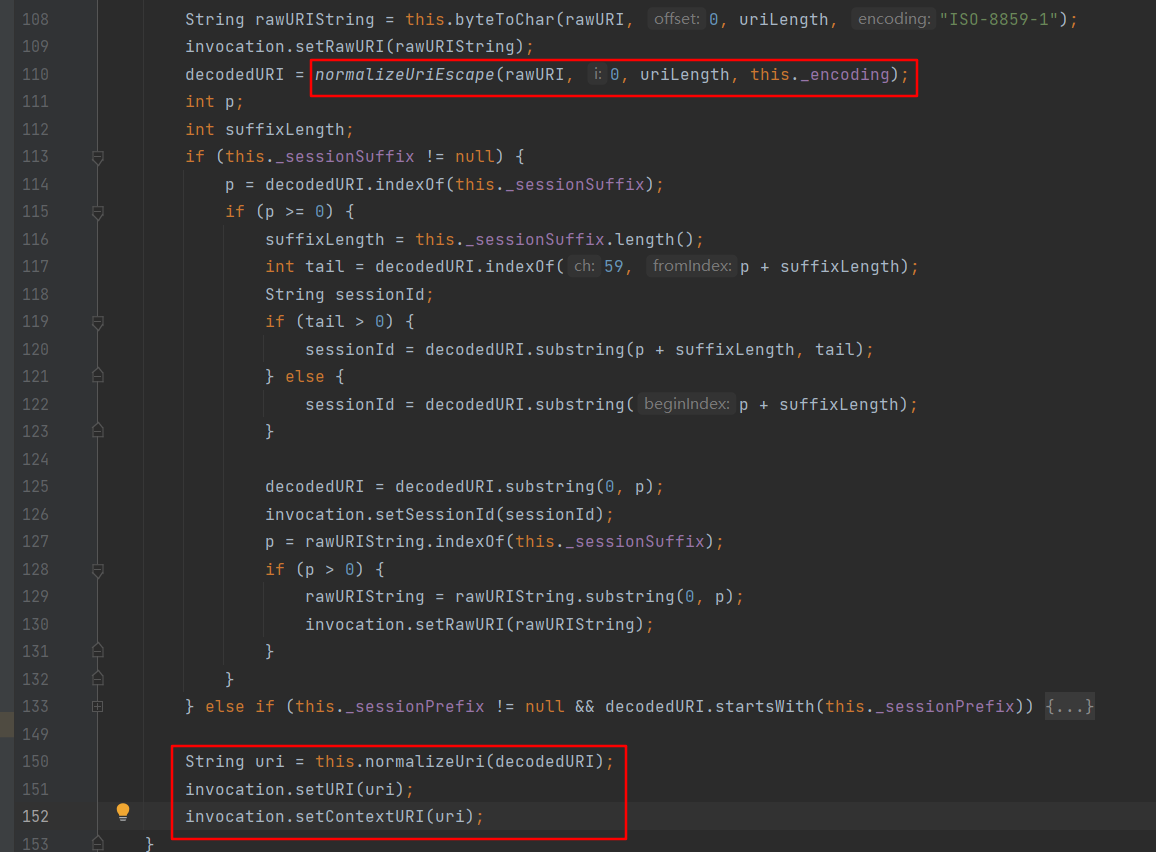
uri进行规范化处理后返回,再跟进buildInvocation,直到ServletMapper#mapServlet中,先调用stripPathParameters对前边设置的contextURI属性再做一次处理,然后调用this._ServletMap.map方法去匹配。


map方法遍历_regexps动态数组,用规范化后uri去匹配RegexpEntry中维护的正则表达式,将_prefixLength最长的Servletmapping对象返回回来。
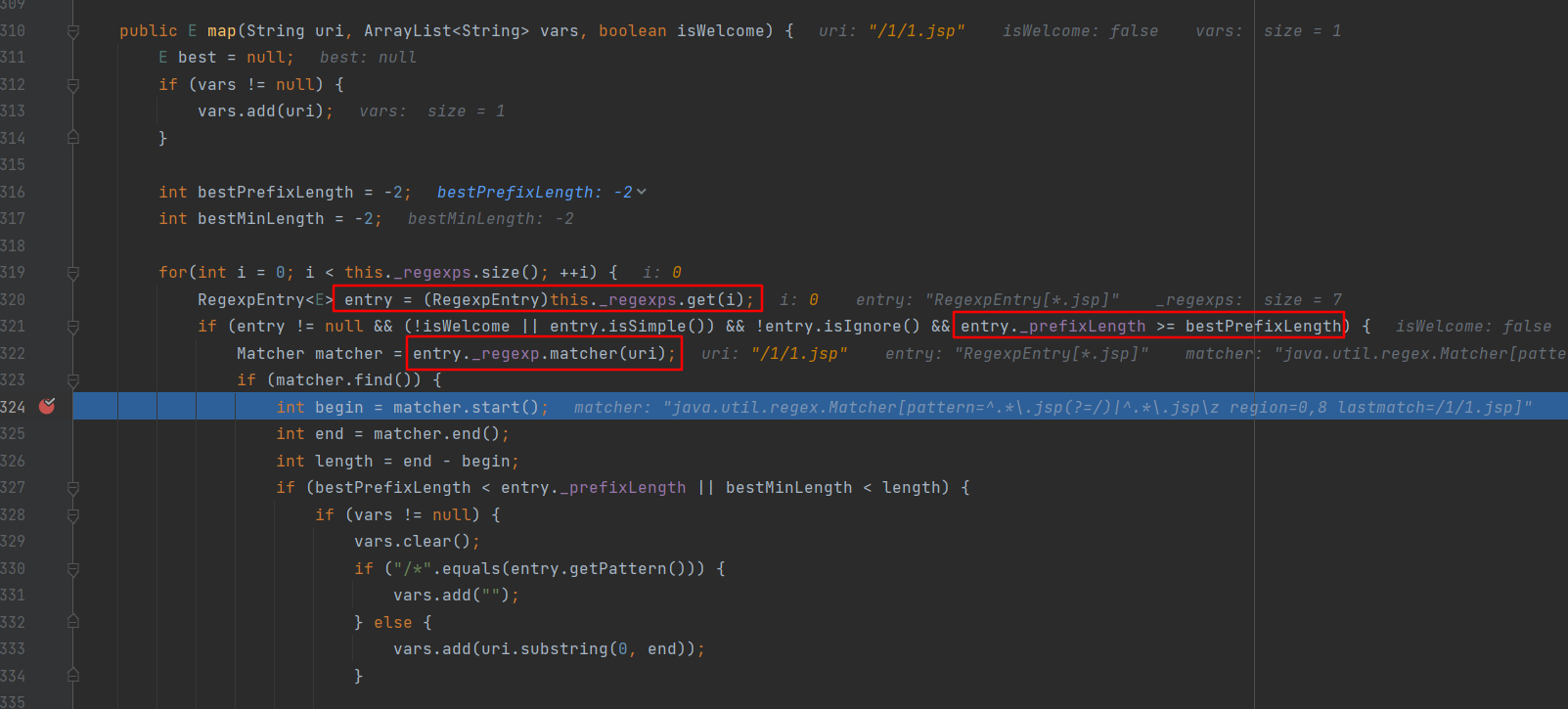
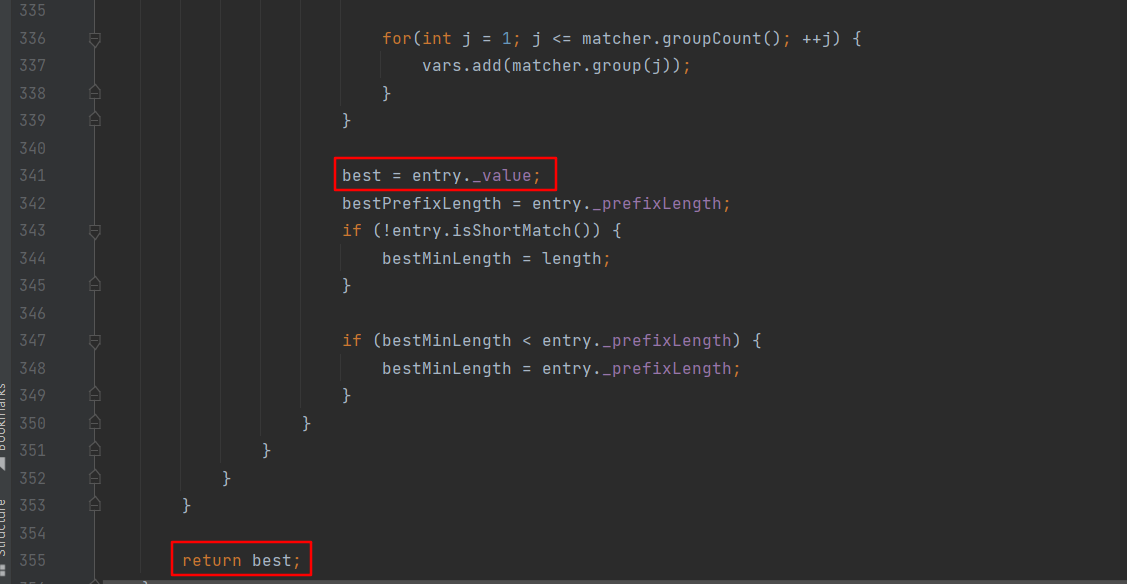
经过上述分析可知Resin将Servletmapping对象和其正则表达式等信息封装在RegexpEntry对象维护到Servletcontext中。路由时将uri先经过normalizeUri处理,再经过stripPathParameters处理,最后遍历所有的RegexpEntry对象的正则去匹配处理后的uri,匹配到就返回对应的Servletmapping对象。如果一个uri匹配到多个,则返回prefixLength最长(优先级最高)的那个。
3.3 Resin路由时URI规范化特性
低版本(<4.0.60)
InvocationDecoder#normalizeUri(Resin4.0.58)方法主要的目的是为了将/../ 以及/./这样的uri处理成规范的uri,将 \ 处理成 / ,但附带还有一些其他的操作,代码逻辑如下:
public String normalizeUri(String uri, boolean isWindows) throws IOException {
CharBuffer cb = new CharBuffer();
int len = uri.length();
if (this._maxURILength < len) {//异常
} else {
char ch;
// uri不以/或者\(以后统称为/)开头,则在最开始添加/
if (len == 0 || (ch = uri.charAt(0)) != '/' && ch != '\\') {
cb.append('/');
}
//遍历uri中每个字符
for(int i = 0; i < len; ++i) {
ch = uri.charAt(i);
//遇到不是/的字符直接添加进cb
if (ch != '/' && ch != '\\') {
if (ch == 0) {
throw new BadRequestException(L.l("The request contains an illegal URL."));
}
cb.append(ch);
//遇到/ 则开始进行校验或处理
} else {
// /不是uri中最后一个字符就进入while循环
while(i + 1 < len) {
ch = uri.charAt(i + 1);
// /x的情况 x代表非/任意字符
if (ch != '/' && ch != '\\') {
// /后不是. 直接跳出while循环将/添加进cb
if (ch != '.') {break;}
// 遇到/.x
if (len > i + 2 && (ch = uri.charAt(i + 2)) != '/' && ch != '\\') {
// 是/.x 直接跳出循环
if (ch != '.') {break;}
// 不是/../时直接异常
if (len > i + 3 && (ch = uri.charAt(i + 3)) != '/' && ch != '\\') {throw new BadRequestException(L.l("The request contains an illegal URL."));}
int j;
//遇到/../时。此时cb是uri中/../之前的内容,将cb中最后一个/ 之后的字符删除了,完成/../跨目录
for(j = cb.length() - 1; j >= 0 && (ch = cb.charAt(j)) != '/' && ch != '\\'; --j) {
}
if (j > 0) {cb.setLength(j);
} else {cb.setLength(0);}
// /../时 前边for循环已经处理过跨目录了 i+3 跳过/..
i += 3;
// 遇到/./ 直接忽略/.
} else {i += 2;}
// 遇到// 忽略第一个/
} else {++i;}
}
// windows系统遇到/时 如果cb的最后一位是.或者空格 ,也就是说uri形如 /abc{连续或单个.或者空格}/xxx 则会把{连续或单个.或者空格}删除,格式化为/abc/xxx
while(isWindows && cb.getLength() > 0 && ((ch = cb.getLastChar()) == '.' || ch == ' ')) {
cb.setLength(cb.getLength() - 1);
if (cb.getLength() > 0 && (ch = cb.getLastChar()) == '/' || ch == '\\') {
cb.setLength(cb.getLength() - 1);
}
}
cb.append('/');
}
}
// 遍历完uri生成格式化的cb后, 在windows下用while循环将cb最后一位是.或者空格删除,直到最后一位不是.或者空格为止
while(isWindows && cb.getLength() > 0 && ((ch = cb.getLastChar()) == '.' || ch == ' ')) {
cb.setLength(cb.getLength() - 1);
}
return cb.toString();
}
}
ServletInvocation#stripPathParameters(Resin4.0.58)方法,主要是想处理;的截断问题,代码逻辑如下:
public static String stripPathParameters(String value) {
StringBuilder sb = null;
int i = 0;
for(int length = value.length(); i < length; ++i) {
char ch = value.charAt(i);
// uri有;
if (ch == ';') {
// uri有/; 直接异常
if (i > 0 && value.charAt(i - 1) == '/') {
throw new IllegalArgumentException(L.l("{0} is an invalid URL.", value));
}
// xxx; 直接将xxx添加进sb
if (sb == null) {
sb = new StringBuilder();
sb.append(value, 0, i);
}
// ;后第一个/的索引
int j = value.indexOf(47, i);
//;后的所有字符中没有/ 直接返回 ;前的路径
if (j < 0) {return sb.toString();}
// ;的前一个字符是/
if (i > 0 && value.charAt(i - 1) == '/') {
i = j;
// ;的前一个字符不是/,将i置为j-1 然后此次循环结束 给i再+1 所以实际是将i置为j,即删除;到下一个/之间的东西
} else {i = j - 1;}
// 不是;直接添加到sb
} else if (sb != null) {sb.append(ch);}
}
return sb != null ? sb.toString() : value;
}
根据以上分析可知uri经过InvocationDecoder#normalizeUri和ServletInvocation#stripPathParameters后的处理规则如下。
| 序号 | uri(备注 该列/代指 /和\ ) | normalizeUri | stripPathParameters() |
|---|---|---|---|
| 1 | /xxx/./ | /xxx/ | /xxx/ |
| 2 | // | / | / |
| 3 | /123/xxx/../ | /123/ | /123/ |
| 4 | /xxx{多个.或者空格}/ | win下/xxx/ linux下不变 | win下/xxx/ linux下不变 |
| 5 | xxx{一个或多个.或者空格} (uri末尾) | win下 xxx linux下不变 | win下 xxx linux下不变 |
| 6 | /abc;xxx(uri末尾) | /abc;xxx | /abc |
| 7 | /abc;xxx/yy | /abc;xxx/yy | /abc/yy |
| 8 | /.;xxx/xxx | /.;xxx/xxx | /./xxx |
| 9 | /1;%0a/1.jsp | /1;\n/1.jsp | /1/1.jsp |
| 10 | /1/1.jsp/xxx | /1/1.jsp/xxx | /1/1.jsp/xxx |
| 11 | /..a(a表示不是/的字符) | 异常 |
所以存在一些uri通过上述两个方法处理后能和某个与servletMaping关联的正则表达式匹配,从而能正确路由。以/1/1.jsp为例,如下的uri都可以正确路由。不止下边这些方式,可以根据上述处理规则自由组合。
| 对应上表序号 | uri |
|---|---|
| 1 | /1/./1.jsp |
| 2 | /1//1.jsp |
| 3 | /1/a/../1.jsp |
| 4 | /1.%20./1.jsp |
| 5 | /1/./1.jsp.%20. |
| 6 | /1/1.jsp;;; |
| 7 | /1;xxx/1.jsp |
| 8 | /.;xx/1/1.jsp |
| 8 | /.;/1/1.jsp |
| 10 | /1/1.jsp/asd |
高版本(>=4.0.60))
在高版本下做了修复,以下代码是Resin4.0.66
normalizeUri方法新增了三点:
- uri中有
/;或者/.;直接异常,所以序号8被修复; - 将
/abc{连续或单个.或者空格}/中的.或者空格替换为_,所以序号4被修复; - uri最后一位
.或者空格替换为_,所以序号6被修复;
代码逻辑如下:
public String normalizeUri(String uri, boolean isWindows) throws IOException {
CharBuffer cb = new CharBuffer();
int len = uri.length();
if (this._maxURILength < len) {//异常
} else {
char ch;
// uri不以/或者\(以后统称为/)开头,则在最开始添加/
if (len == 0 || (ch = uri.charAt(0)) != '/' && ch != '\\') {
cb.append('/');
}
//遍历uri中每个字符
for(int i = 0; i < len; ++i) {
ch = uri.charAt(i);
//遇到不是/的字符直接添加进cb
if (ch != '/' && ch != '\\') {
if (ch == 0) {throw new BadRequestException(L.l("The request contains an illegal URL."));}
cb.append(ch);
//遇到/ 则开始进行校验或处理
} else {
// uri中最后一个字符之前的字符就进入while循环
while(i + 1 < len) {
ch = uri.charAt(i + 1);
// /x的情况 x代表非/任意字符
if (ch != '/' && ch != '\\') {
// 新增 如果是/; 直接异常
if (ch == ';') {
throw new BadRequestException(L.l("The request contains an illegal URL."));
}
// /后不是. 直接跳出while循环将/添加进cb
if (ch != '.') {break;}
// 遇到/.x
if (len > i + 2 && (ch = uri.charAt(i + 2)) != '/' && ch != '\\') {
// 新增 如果遇到/.; 直接异常
if (ch == ';') {throw new BadRequestException(L.l("The request contains an illegal URL."));}
// 是/.x 直接跳出循环
if (ch != '.') {break;}
// 不是/../时直接异常
if (len > i + 3 && (ch = uri.charAt(i + 3)) != '/' && ch != '\\') {throw new BadRequestException(L.l("The request contains an illegal URL."));}
int j;
//遇到/../时。此时cb是uri中/../之前的内容,将cb中最后一个/ 之后的字符删除了,完成/../跨目录
for(j = cb.length() - 1; j >= 0 && (ch = cb.charAt(j)) != '/' && ch != '\\'; --j) {
}
if (j > 0) {cb.setLength(j);
} else {cb.setLength(0);}
// /../时 前边for循环已经处理过跨目录了 i+3 跳过/..
i += 3;
// 遇到/./ 直接忽略/.
} else {i += 2;}
// 遇到// 忽略第一个/
} else {++i;}
}
// 修改 windows系统遇到/时 如果cb的最后一位是.或者空格 ,也就是说uri形如 /abc{连续或单个.或者空格}/xxx 则会把{连续或单个.或者空格}替换为_,格式化为/abc_{一个或多个}/xxx
while(isWindows && cb.getLength() > 0 && ((ch = cb.getLastChar()) == '.' || ch == ' ')) {
cb.setCharAt(cb.getLength() - 1, '_');
if (cb.getLength() > 0 && (ch = cb.getLastChar()) == '/' || ch == '\\') {
cb.setLength(cb.getLength() - 1);
}
}
cb.append('/');
}
}
// 将while循环修改为if 遍历完uri生成格式化的cb后, 在windows下如果cb最后一位是.或者空格 则替换为_,所以是只替换一次
if(isWindows && cb.getLength() > 0 && ((ch = cb.getLastChar()) == '.' || ch == ' ')) {
cb.setLength(cb.getLength() - 1);
}
return cb.toString();
}
}
stripPathParameters方法新增了uri中有/.;直接异常,所以序号8被修复
public static String stripPathParameters(String value) {
if (value == null) {
return null;
} else {
StringBuilder sb = null;
int i = 0;
for(int length = value.length(); i < length; ++i) {
char ch = value.charAt(i);
// uri有;
if (ch == ';') {
// uri有/; 直接异常
if (i > 0 && value.charAt(i - 1) == '/') {
throw new IllegalArgumentException(L.l("{0} is an invalid URL.", value));
}
// 新增 /.; 直接异常
if (i > 1 && value.charAt(i - 1) == '.' && value.charAt(i - 2) == '/') {
throw new IllegalArgumentException(L.l("{0} is an invalid URL.", value));
}
// xxx; 直接将xxx添加进sb
if (sb == null) {
sb = new StringBuilder();
sb.append(value, 0, i);
}
// ;后第一个/的索引
int j = value.indexOf(47, i);
//;后的所有字符中没有/ 直接返回 ;前的路径
value.indexOf(61, i);
if (j < 0) {
return sb.toString();
}
// ;的前一个字符是/
if (i > 0 && value.charAt(i - 1) == '/') {
i = j;
// ;的前一个字符不是/,将i置为j-1 然后此次循环结束 给i再+1 所以实际是将i置为j,即删除;到下一个/之间的东西
} else {i = j - 1;}
// 不是;直接添加到sb
} else if (sb != null) {
sb.append(ch);
}
}
return sb != null ? sb.toString() : value;
}
}
四、URI规范化特性导致认证绕过
通过分析Resin Servlet 路由机制可知,路由时使用规范化后的uri和RegexpEntry对象中的正则表达式去匹配,所以一些本身不能匹配的uri经过规范化后却能正确路由、后缀匹配生成的一些不合理的正则表达式(如^.*\.jsp(?=/)|^.*\.jsp\z)导致一些不合理的uri(如/1/1.jsp/xxx)也能正确路由。
有很多web应用会在filter等中设置一些uri规则去做权限认证,如果使用javax.Servlet.http.HttpServletRequest#getRequestURI方法获取未规范化的uri去判断当前请求是否需要认证,那么找到一个能正常路由但不满足认证条件的uri,则可以达成权限认证绕过的效果。

如下是windows环境下某OA的一个例子,当uri满足如下if条件时,则需要判断loginid是否为true,不为true则认证失败。
("E9".equalsIgnoreCase(sc.getEcVersion()) || "E10".equalsIgnoreCase(sc.getEcVersion())) && path.endsWith(".jsp") && (path.indexOf("/messager/") != -1 || path.indexOf("/social/") != -1) && !"/social/im/socialimgcarousel.jsp".equalsIgnoreCase(path))
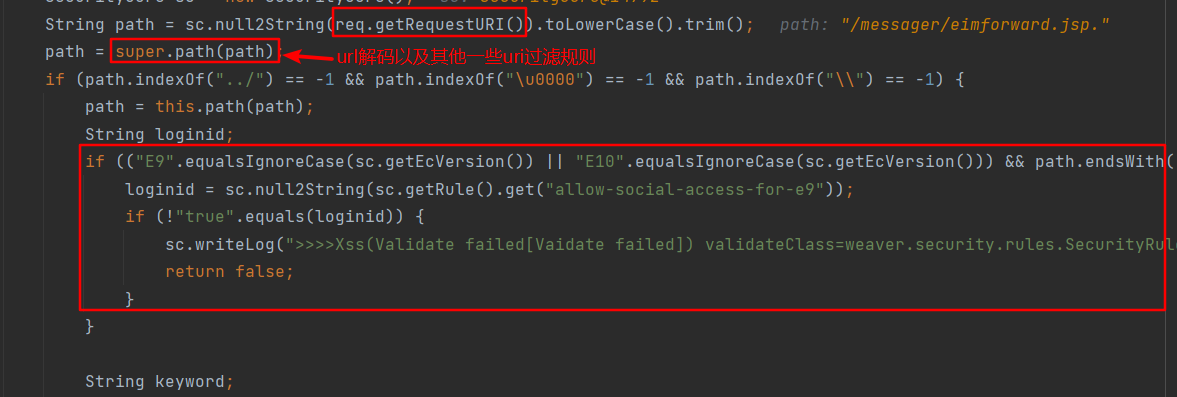
正常访问时会被认证规则拦截,响应404。
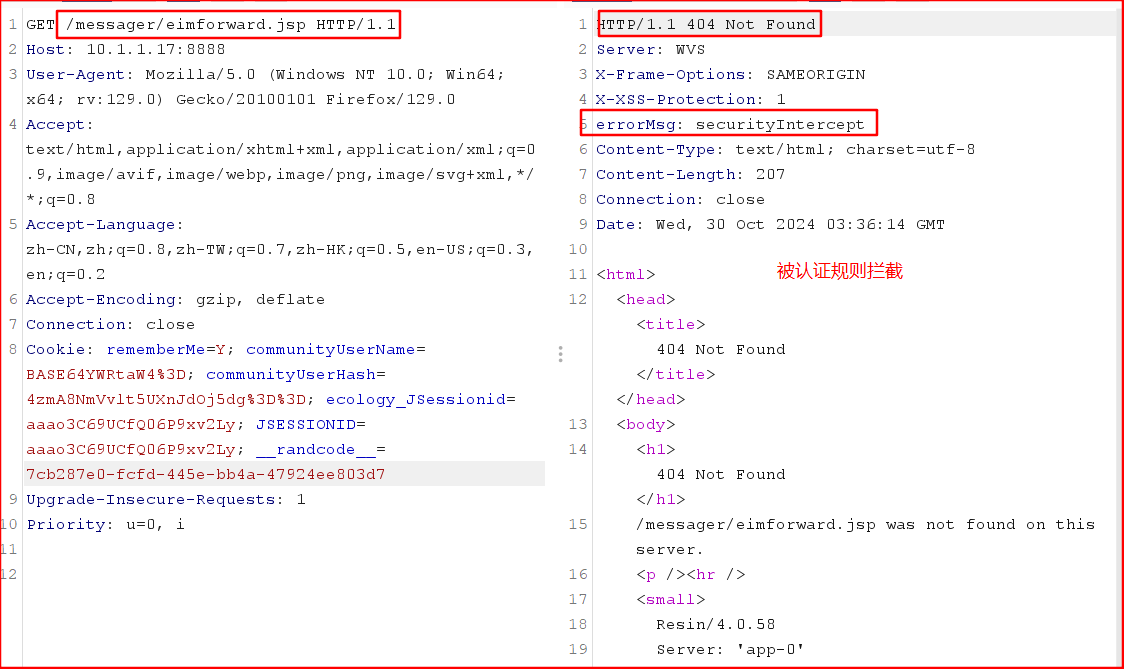
结合前边的分析的规范化特性,给出一个能正常路由且能绕过认证条件的uri,如/messager/eimforward.jsp.。

这里以某OA的一个例子说明存在这种漏洞模式,但存在构造的某些理论上可以正确路由的uri也会被拦截,这是由于某OA有很多拦截规则,可能过了某个规则但恰好被别的规则拦截,这里就不具体展开了。
五、总结
基于Servlet URL 的匹配模式、 urlpattern的正则生成逻辑和路由分发时的 URI 规范化特性,可以更深入理解 Servlet 路由机制的核心原理。这种规范化过程中处理 URI 的方式是认证绕过的关键点,尤其是当一些 Web 应用基于获取未规范化的 URI 进行权限认证时,可能导致认证机制被绕过。为了更直观地展示这一技术原理,文中结合实际案例展示了如何利用此机制实现认证绕过。