
一、前言
在操作系统中,每当谈及异步,通常都是使用多线程/多进程来实现多任务的执行。然而在现代开发过程中,往往会听到一个新的概念:协程。这是一种更轻量化的并发处理模型,协程被广泛集成到诸如 Go、JavaScript、Rust 和 Python 等主流语言中,成为异步编程的核心工具。为了更好地理解协程,从而探究协程中可能存在的相关的安全问题,文章将简要介绍协程的起源与基本概念,然后通过分析协程模型的特点揭示潜在的安全风险,最后结合真实的漏洞案例,展示协程可能引发的安全隐患,并讨论如何更有效地规避这些问题。
由于内容较多,文章将分为上下两篇。在本文上篇中,会介绍协程的定义,包括常见的协程的用途以及协程在代码中的形式,接下来会给大家一个直观的感受,推断协程是如何诞生的。
二、什么是协程
关于协程的定义,这里直接摘自AI:
协程与传统函数调用的主要区别在于控制权的转移和状态的保存,这使得协程可以在中途挂起并在稍后恢复。
总结来看,协程具有如下的特征:
- 它不是一个由操作系统提供的特性,它是基于语言层面模拟的一个效果;
- 调度需要显示的声明起转换过程。
这里需要注意的是,协程于线程并非是同一个层级的概念,协程是一个用户态模拟的概念,而线程属于操作系统的原生概念。
通常,协程挂起的时候,会保存当前的上下文,包括栈堆以及寄存器等等。
由于协程非一个存在于操作系统的概念,所以对于操作系统而言,它并非真实存在,这就导致传统的调试器无法直接看到它,也就不存在直接观察它的办法。为了能对其有一个比较感性的认知,我们可以尝试先从编程语言中感受它的存在形式。在不同于语言中,协程的呈现形式也不同。比如在python中,协程的函数一般长成这样:
import asyncio
async def my_coroutine():
print("Start coroutine")
await asyncio.sleep(1)
print("End coroutine")
async def main():
print("Start main")
await my_coroutine()
print("End main")
## Run the main function
asyncio.run(main())
其输出如下:
Start main
Start coroutine
End coroutine
End main
可以看到有几个关键点:
- 程序以异步的形式运行;
- 存在async/await关键字,被声明的函数才具有协程异步的能力;
- 需要使用asyncio.run将其包裹。
在协程使用更加广泛的go语言中,协程的代码如下所示:
package main
import (
"fmt"
"time"
)
func asyncTask(done chan string) {
time.Sleep(2 * time.Second)
done <- "Task completed"
}
func main() {
done := make(chan string)
go asyncTask(done)
result := <-done
fmt.Println(result)
}
在go语言中,使用goroutine概念描述协程,基本上所有的函数都会运行在goroutine中。并且使用channel的概念(就是: <-)让变量能够在不同的协程间通信。但是也可以看到几个特征:
- 开启新的协程的时候,需要使用关键字go;
- 使用channel同步数据的时候,程序会有类似同步的机制发生。
除了上述语言,Rust、Javascript、Lua等不同语言都提供了协程的支持。协程这个概念其实提出的很早,但是在这几年硬件性能的增长,以及云计算、分布式等场景对大量并发计算的需求,使得协程变成了一个非常理想的方案。这几年C++也开始提供对协程的支持,反映了协程这个概念对于开发模型的重要意义。
2.1 M:N 调度模型
在协程描述场景中,常常能听说类似于M:N模型的说法,这里的M:N调度模型描述了协程与操作系统线程之间的映射关系:
- M 表示协程的数量:程序中可以有多个协程,通常远多于线程;
- N 表示操作系统线程的数量:协程运行的基础资源。
在这种模型中,通常用于描述多数的协程M在系统调度策略下,被放到少数的线程N上执行。这样一来就能尽可能地减少线程地调度,从而提搞程序地运行效率。
三、协程发展史
如果想要比较彻底的明白一个概念,最好是从它的诞生史来看它是怎么来的。接下来将一步步介绍协程诞生的过程。
31. 最初的开始 - Duff’s device
达夫设备(Duff’s device)是一个C语言编程技巧,但是这个技巧提出了一种类似状态的思想,利用状态描述可以让程序从某一个中间态,而并非开始位置开始运行,这个过程也被称之为循环展开(unrolling loop),这种重要的思想指导了后面协程的诞生。
在很早年的时候,有一名叫做Tom Duff的工程师,他曾面临一个如下的场景:有一个往屏幕输入的寄存器(假设叫做to,当以*to进行数据写入的时候会自动将数据写入屏幕),此时有一个连续的内存记录我们将要写入的数据(这里记为from)。于是为了能渲染这个画面,他写出了如下的代码:
{
do { /* count > 0 assumed */
*to = *from++;
} while (--count > 0);
}
然而,现实中的寄存器(早期是8个)肯定不是连续的内存,所以需要手动写一个赋值,类似于:
register count;
{
register n = count / 8;
do {
*to0 = *from++;
*to1 = *from++;
*to2 = *from++;
*to3 = *from++;
*to4 = *from++;
*to5 = *from++;
*to6 = *from++;
*to7 = *from++;
} while (--n > 0);
}
问题在于,这个from只想的数据并非一定是8的倍数,这种【不对齐的循环】问题就可能会带来无效的循环逻辑,达夫就提出了一种取巧的方式,本质上就是巧妙地利用switch的松散特性:
register count;
{
register n = (count + 7) / 8;
switch (count % 8) {
case 0: do { *to7 = *from++;
case 7: *to6 = *from++;
case 6: *to5 = *from++;
case 5: *to4 = *from++;
case 4: *to3 = *from++;
case 3: *to2 = *from++;
case 2: *to1 = *from++;
case 1: *to0 = *from++;
} while (--n > 0);
}
}
在处理数据的时候,优先将不对齐的部分先进行赋值,然后再以倍数进行赋值,从而减少循环语句中执行每条语句的次数。
这段代码在现在来看,其实已经不具备太好的优化能力,并且其可读性其实并不好,然而这个代码抽象来说,提出了一种观念,就是在循环中同时保持对状态的计算,正如这个count%8的值,它间接的影响了这个循环的位置,使其会从循环不同的位置开始。
这种在循环中插入执行状态的一种思想,可以被称之为达夫设备,也就是后来生成器诞生的原因。
3.2 历史的变迁 - 生成器 yield
很多时候,都有读入文件的需求。但是绝大多数的场合,都是对文件内容按行进行解析,而不需要一口气读入。实际上,很多文件都非常大,如果一口气读入所有的文件内容,程序就会变得卡顿。
通常情况,程序会推荐按照如下的方式读入数据:
function read():
/* reads the content in the desired number
of steps and returns back control to parser
but saves its own state of function. */
function parse():
a = read()
while (a)
{
// do something
a = read()
}
换句话说,就是不一次性读入所有的数据,而是按照行处理数据。
然而,这种写法有一个问题,就是读文件的逻辑和处理文件的逻辑耦合在了一起,希望程序能够做到如下的效果:
- 每次只读入一行,并且返回一行的内容。
可以将上面的代码简单抽象成一个循环的样式,如果再C语言,希望类似于:
int read(void)
{
int i;
for (i = 0; i < 10; i++)
return i; /* Well on the first run itself
the function will be destroyed */
}
然而实际上,C中一旦遇到了返回,那么这个程序的上下文便会被毁坏,从而导致程序必须从头开始循环。
解决方案也很简单,回想再第一段中提到的达夫设备,也就是利用状态影响循环起始位置,或者说,引入状态这个概念,利用状态主动保留程序的运行上下文,从而使得程序可以从指定的位置开始运行。
在C语言中,可以用static实现这个效果:
// C++ program to demonstrate how coroutines
// can be implemented in C++.
#include <iostream>
using namespace std;
int range(int a, int b)
{
static long long int i;
static int state = 0;
switch (state) {
case 0: /* start of function */
state = 1;
for (i = a; i < b; i++) {
return i;
/* Returns control */
case 1:
cout << "control at range"
<< endl; /* resume control straight
after the return */
}
}
state = 0;
return 0;
}
// Driver code
int main()
{
int i; // For really large numbers
for (; i = range(1, 5);)
cout << "control at main :" << i << endl;
return 0;
}
通过达夫设备的思想,让程序根据状态,从不同的地方返回,以及从不同的位置开始循环,从而实现了让程序仅执行部分逻辑的效果。可以将上述代码封装成这个样子:
#define crBegin static int state=0; switch(state) { case 0:
#define crReturn(i,x) do { state=i; return x; case i:; } while (0)
#define crFinish }
int function(void) {
static int i;
crBegin;
for (i = 0; i < 10; i++)
crReturn(1, i);
crFinish;
}
这样几乎就让C语言实现了一个类似协程的概念(CoRoutine)—— 程序的调用者和被调用者在逻辑层面上,都能以正向思路完成代码编写。
这种写法在python中其实已经非常常见,也就是:
In [1]: def func():
...: for i in range(10):
...: yield i
...:
In [3]: for each in func():
...: print(each,end=',')
...:
0,1,2,3,4,5,6,7,8,9,
在现代语言中,这种写法之为生成器(generator)。在不同的语言中,这个生成器或是直接作为特征提供(例如Python、Lua、C#等),或者是可以通过语言提供的其他特性,构造类似的设计结构完成对应的实现。
3.3 协程的诞生 - 做菜模型
有了之前的生成器模型,现在得到一种类似于保留状态的编程模式:保留当前运行的状态,并且根据运行状态决定接下来的运行逻辑,而并非从程序刚开始的位置运行。而协程本质上就是利用了这个特征实现的一种运行。接下来,尝试从伪的方式来描述协程到底是什么。
将一个程序的上下文称之为Ctx,也就是当前运行寄存器。
假定有一段做饭的代码中cook表示烹饪,而烹饪中包含炖菜stew和炒菜fry,但是炒菜之前需要先切菜cut,当终于烹饪结束之后,会eat饱餐一顿,那拟这个过程的代码如下:
func stew()
{
stew_until_finish(); // 炖菜,与下面的函数互不干涉
}
func cut()
{
food = cut_food(); // 切菜,切完了菜才能开始炒菜
return food;
}
func fry()
{
food = cut_food();
fry_food(food); // 炒菜必须要炒准备好的菜
}
func cook()
{
// 炖菜
stew();
// 炒菜
fry();
}
func main_func()
{
// 先做饭
cook();
// 再吃饭
eat();
}
在传统模式下,程序的执行逻辑是这样的:
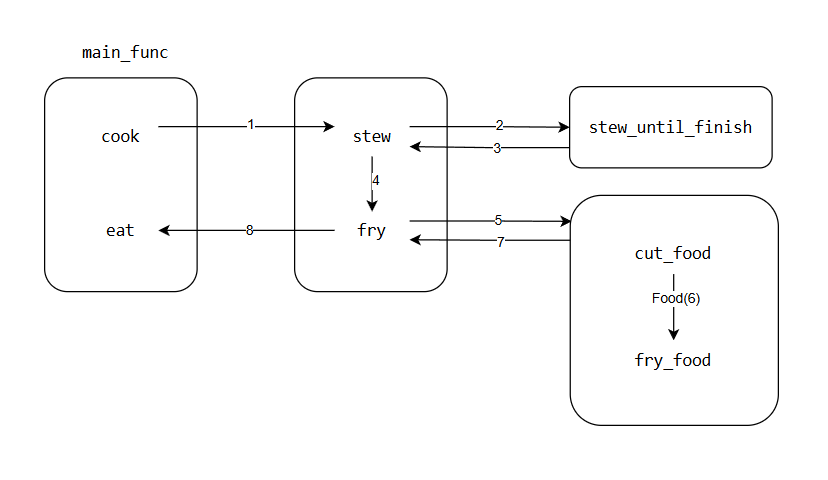
然而,在认知中,炖菜stew完全是一以单独运行的逻辑——毕竟只要把菜炖熟了就行,完全是可以和切菜炒菜并行执行的,也就是如下图所示的场景:
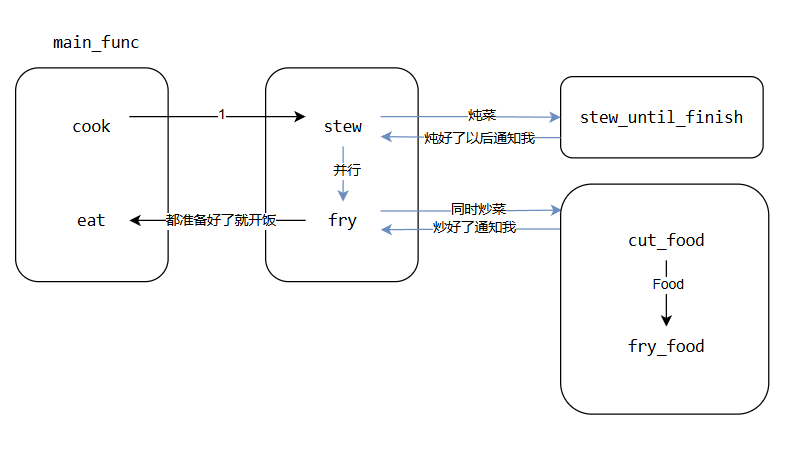
炖菜stew和炒菜fry是两个可以并行的函数,这两个函数中可以同时做。换句话说,无需等待其中一个操作完成再做另一个要怎么做呢?回想一下现实场景中,如何同时做菜?很简单人也参与在其中就好了就是说,厨师作为管理者度这些过程,防止炖汤煮糊了的同时,又来操作切菜炒菜,也就是如下的运行模式:
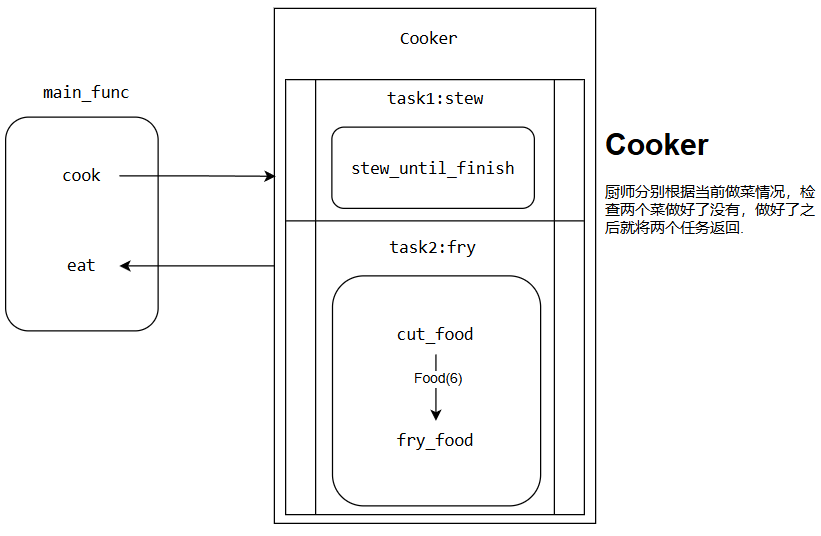
可以写出如下的代码模型:
class People{
event_queue; // 处理事务的列表
func checking_finish()
{
while event_queue.is_not_empty(){
for each_event in event_queue {
// 执行任务
each_event.do_task();
}
for each_event in event_queue {
// 确认是否完成任务
if each_event.check_finish() {
each_event.finish = True;
}
}
// 将队列中完成的对象全部拿出来
event_queue.remove_if_finish();
}
}
}
People chef;
func cook()
{
task1_stew = Task(&stew);
task2_fry = Task(&fry);
chef.event_queue.push(task1_stew);
chef.event_queue.push(task2_fry);
chef.checking_finish()
}
func main_func()
{
// 先做饭
cook();
// 再吃饭
eat();
}
如上,人为的制造了一个事件队列在chef对象中,并且通过调用do_task来完成任务,并且通过check_finish检查任务是否完成。然而,如果这个do_task就是原先给出来的函数(例如stew/fry)那么这个过程显然依然是一个等待执行的过程,这就意味着其并没有实现异步。这该怎么办呢?
此时,可以将之前提到的生成器模型和这段函数结合,并非每次都直接执行程序本身直到其执行完成,而是如同生成器一般,检查函数是否做完,如果没有做完,则返回一个没做完的状态,否则给出一个做完的状态。以炖菜stew为例,其实并不用持续的站在炖菜旁边,而是等他冒热气了再去检查:
func stew::do_task()
{
state = stew_until_finish_async_mode();
do{
state = check_if_steam();
switch(state)
{
case Ready: break;
case Pending: continue
}
// 此时表示仍未煮熟
yield
}while(True);
// 运行到这里则表示煮熟了
return ;
}
假定这里的stew_until_finish存在一种异步模式的函数,称之为stew_until_finish_async_mode。
在这里首先调用了这个stew_until_finish_async_mode,这个函数并不会真正开始执行炖菜的全流程,而只是将炖菜放入锅中,并且开火,此时函数会当即返回。然后调用一个check_if_steam的函数,这个函数相当于检查炖菜是否冒气了。如果冒气了就意味着煮熟了,那么就不必在继续煮,终止顿炖,并且返回完成的状态,否则调用前面生成器中提到的yield关键字,表示距离煮熟还有一段时间,此时暂时性的离开了这个程序,也就是告知程序可以暂时放弃检查这个函数,转而检查其他烹饪情况。相当于如下的形式:
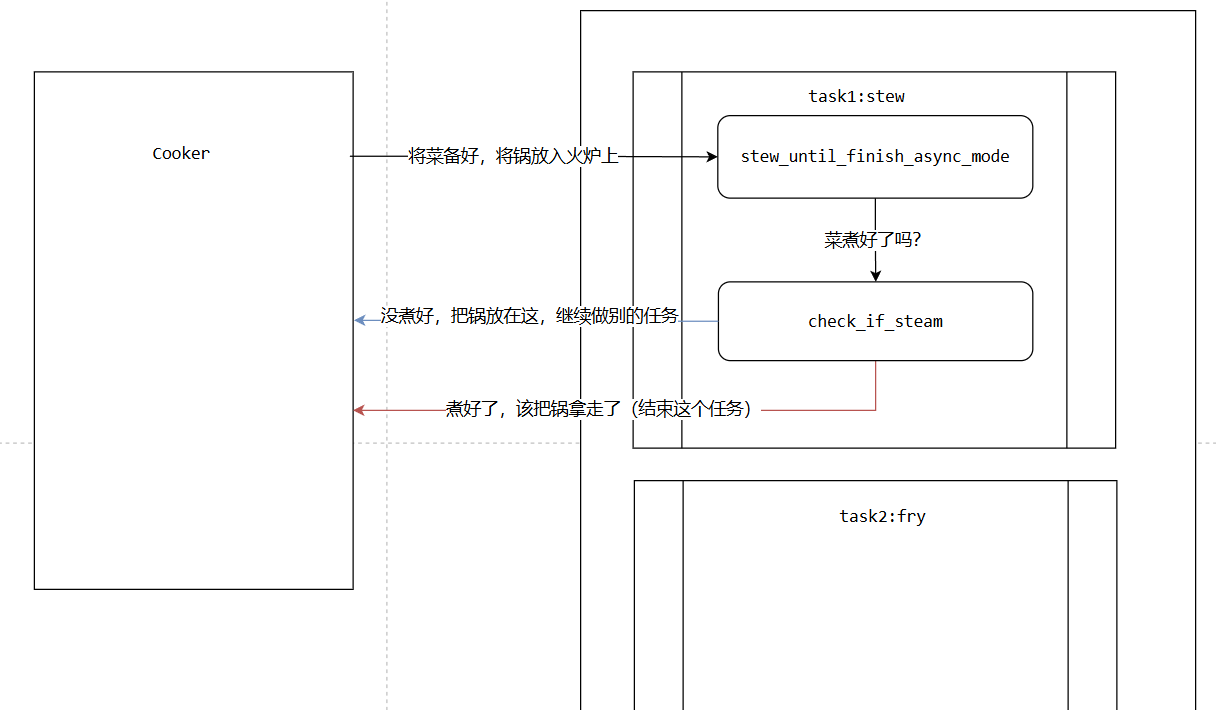
在实际场景中,这类异步函数也是存在的,常见于IO数据获取等场合,例如读取文件或者网络数据,均存在这种调用后就立刻返回的函数。
如果按照上述模式,可以进一步优化我们厨师chef的checking_finish函数:
func checking_finish()
{
while event_queue.is_not_empty(){
do{
event = event_queue.get();
state = event.do_task();
if state == Ready:
{
event_queue.remove(event);
}
}while(event_queue.is_not_empty())
}
}
同理,也可以按照这个方式处理我们的fry函数,这样就能够实现在未开启多线程的情,依次调用stew和fry函数的效果。
然而,在上述的处理方式上,还是有了太多无用的循环。在某些场合中,这种轮询也比较消耗时间,例如这个厨房其实很大,在炖锅和炒锅之间走来走去其实非常花时间,还容易两边都煮糊了。那么此时可以弄一种类似闹钟的提醒装置,对于炖锅而言,一旦冒气,它就会发出声音,提醒检查是否真的煮熟好;在没提醒的时候,完全可以不检查炖锅,转而专心处理切菜和炒菜的活儿。也就是说,利用提醒装置,可以忽略正在等待中的逻辑,转而将这个逻辑将时间留给其他的逻辑。
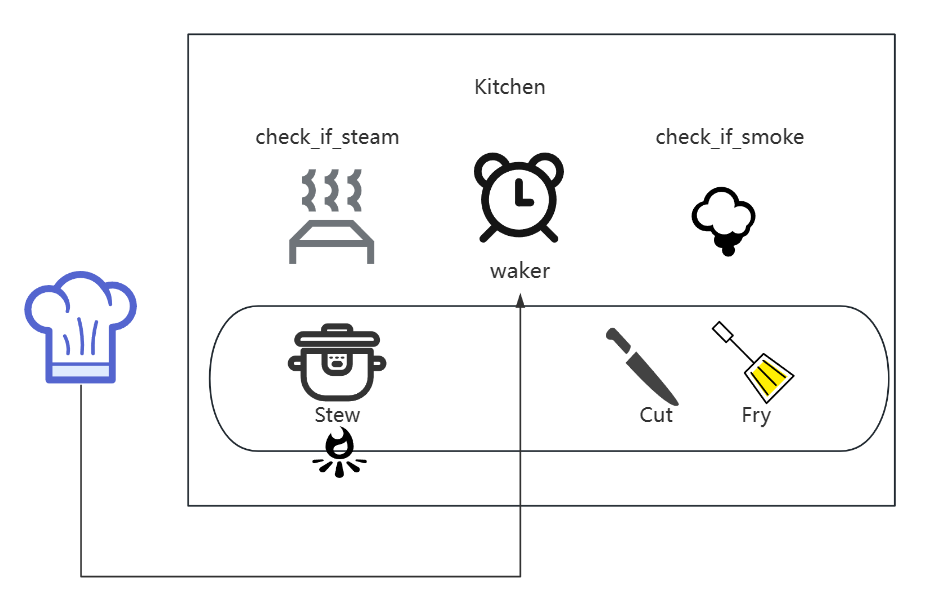
例如,在生成stew::do_task的时候,根据这里的check_if_steam函数,设定一个闹钟函数alarm,并且将这个闹钟安装在我们的厨房(也就是程序运行上下文)roomctx中么此时代码可以写作如下:
func stew::do_task(ctx roomctx)
{
state = stew_until_finish_async_mode();
// 在这里设置一个闹钟,当有水蒸气之后,再考虑过来检查是否煮好了
roomctx.register_waker(check_if_steam)
do{
// 有时候,即使有水蒸气,也只是假沸腾,还是得看是否煮熟了
state = check_if_stew_finish();
switch(state)
{
case Ready: break;
case Pending: continue
}
// 此时表示仍未煮熟
// 那么厨师可以回到原来的厨房继续做菜,直到看到通知
roomctx = yield
}while(True);
// 运行到这里则表示煮熟了
return ;
}
然后此时,对于厨师Chef的检查逻辑,可以分离出另一个叫做唤醒器waker的概念,这就好像是听闹钟的耳朵,抑或是一个手机上的闹钟。简单来说就是一个用来观测当前事务是否完成的观测者。这个观测对象仅对目标进行观测,只有其完成了任务之后,才尝试调用目标函数:
func ctx::register_waker(func* func_ptr)
{
self.waker.push(func_ptr);
}
func checking_finish()
{
ctx = self.room_ctx;
while event_queue.is_not_empty(){
iter_waker = self.waker.iter();
waker_state = NotTrigger;
do
{
// 遍历我们的waker函数,例如调用前文提到的checkf_steam
waker_state = *iter_waker.trigger();
// 激活事件队列中的事件
if waker_state != NotTrigger:
{
event_queue.get_by_waker(iter_waker).trigger = True;
waker_state = Trigger;
}
}while(iter_waker != end && waker_state == NotTrigger);
// 此时,再调用其中的事件函数
do{
event = event_queue.get();
// 只有激活的事件我们才去激活
if eve.trigger == True:
{
state = event.do_task();
event.trigger = False;
}
if state == Ready:
{
event_queue.remove(event);
}
}while(event_queue.is_not_empty())
}
}
如上,此时就可以通过waker先预先调用,确定哪些事件是真的准备好了的,从而决定之后的调用需要调用哪些函数。
按照这种写法,也能写出炒菜fry中的函数调用:
func fry::do_task(ctx roomctx)
{
// 因为我们必须要先切菜,所以这里只能线性执行
fd = cut_food();
// 将炒锅放到炉子上,准备炒菜
state = fry_food_until_finish_async_mode();
// 在这里设置一个闹钟,当冒烟以后,说明此时炒菜有点焦了,我们需要检查是不是炒好了
roomctx.gister_waker(check_if_smoke)
do{
// 有时候,即使有烟,也只是单面炒焦了,还是得看另一面是否煮熟了
state = check_if_fry_finish();
switch(state)
{
case Ready: break;
case Pending: continue
}
// 此时表示仍未煮熟
// 那么厨师可以回到原来的厨房继续做菜,直到看到通知
roomctx = yield
}while(True);
// 运行到这里则表示煮熟了
return ;
}
在获取这两个程序的运行模式之后,就需要一个函数,告诉厨师chef需要等待两个任务都完成之后才能进行下一步。这个时候可以使用类似于join的函数,等待两个任务均完成,此时就可以完善烹饪逻辑cook和主函数main_func写出来:
// 和之前一样,将新建的函数放入
func cook()
{
task1_stew = Task(&stew);
task2_fry = Task(&fry);
chef.event_queue.push(task1_stew);
chef.event_queue.push(task2_fry);
// 等待所有任务完成
chef.join_tasks();
}
// main函数中,我们通知厨师,存在一个需要管理的场合,所以希望他过忙
func main_func()
{
// 厨师准备一个厨房,用来放这两个锅来实现异步,以及事件队列
chef.prepare_runtime_room();
// 调用cook,此时厨师会异步的处理这些事情
cook()
// 处理完事情之后,最后吃饭
eat();
}
这样一来,就实现了一个厨房场景中的异步场景:
首先,厨师需要准备一个厨房,也就是异步运行上下文,包括事件队列,唤醒器
waker等;
之后做饭的时候,炖菜
stew和炒菜fry作为厨师的两个任务,加入到厨师的事件队列中,之后厨师只需要管理这两件做饭的事宜;
\
当执行
stew的时候,程序会调用stew_until_finish_async_mode,先将锅放上火炉,但是此时不开始正式烹饪;
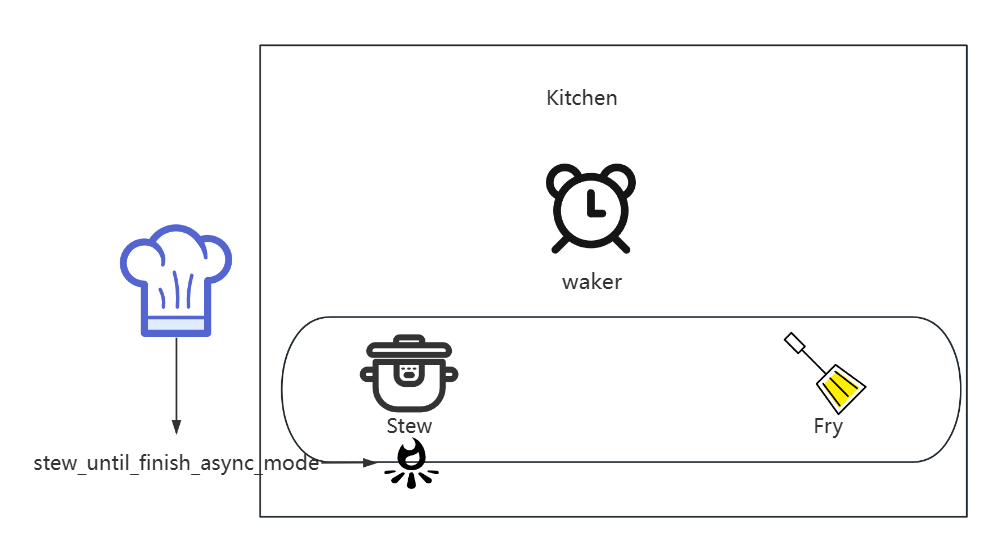
- 将判断依据是否出现水蒸气
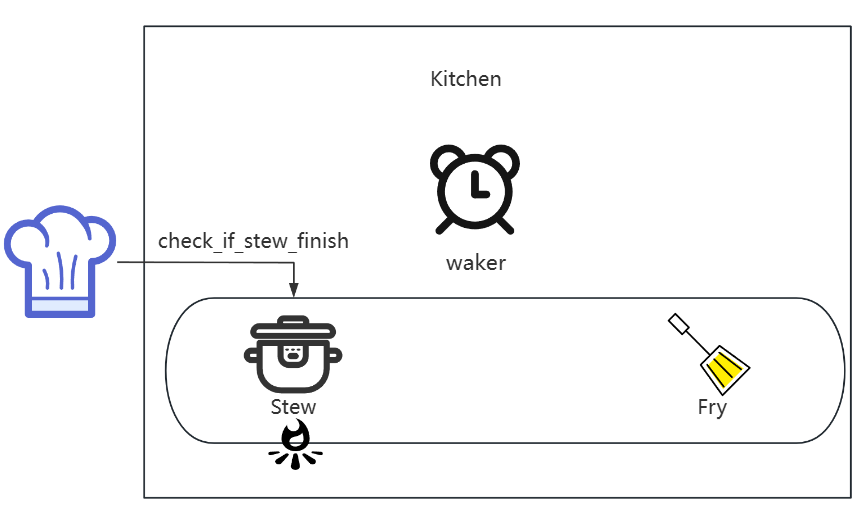
check_if_steam作为提醒标准并记录,此时只有锅冒出水蒸气才去检查;

- 之后,尝试检查锅是否煮熟
check_if_stew_finish,如果没有煮熟,则离开炖煮stew状态,前往炒菜状态fry;
- 进行炒菜环节fry,因为切菜是必须的逻辑,所以会同步地执行切菜
cut_food直到开始执行炒菜fry_food_until_finish_async_mode这个异步函数;
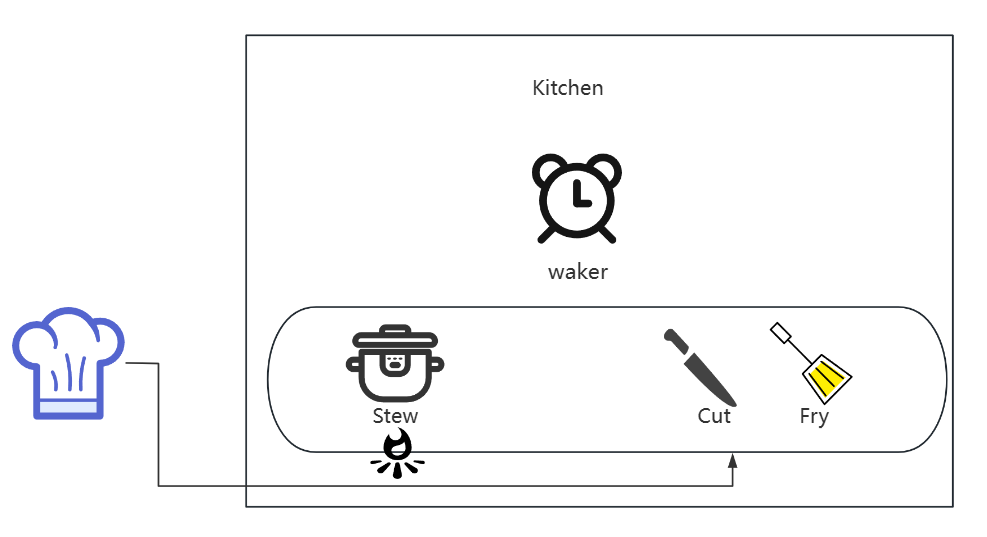
- 如果炒菜的时候没有冒烟
check_if_smoke,说明单面还没炒好,此时离开当前状态,等待冒烟,抑或是锅煮沸腾check_if_steam;
- chef 通过调用
join_tasks函数,等待两个任务直到均返回Ready,也就是相当于菜炖好了/炒好了,此时结束两个任务队列; - 此时
chef执行完成,我们回到主函数,开始吃饭。
在这个小小的做菜中,我们能够发现,即便是在没有多线程的运行模式下,也能造出一种几乎异步的环境,这种异步我们就可以叫做协程。在这个小小的模型中,有集中必要素:
- 调度的最小单位为一种可以被异步执行的任务,例如炖菜
stew或者炒菜fry,而对于炒菜的前置对象切菜cut,由于在逻辑上并未将其视为异步的一环,因此它并非异步对象; - 这种异步任务,在不同语言中称谓不同,有些叫做
Task、有些叫做Cocurrency,这边可以统一用中文称之为协程; - 程序中调用异步函数,在调用之后会对调用结果进行轮询,当返回结果为
Ready的时候; - 轮询过程中,可以使用一种通知函数,告知程序应当去执行任务;
- 利用状态,让程序从合适的位置重新开始运行;
- 通过类似
join的函数,等待数个异步任务,直到双方都完成;
只要按照上述的模式维护对象进行异步编程,就可以构造出协程的编程模型。
3.4 更加高效的编程 - async/await
实际上,上述中的很多函数都使用了一些比较具体的说法来描述我们的场景,然而在实际情况下,很多异步对象(例如计,文件网络IO等)都有着属于自己的waker标志和对应的异步操作,绝大多数的耗时操作也来自于这些行为。所以各类提供协程的语言,完全可以将这类操作提前封装好,这样就无需每次编程的时候都由开发人员手动编写这些流程。
为了更好的描述协程,可以给出一些对于协程过程中常见的概念:
- 每一个将要进行异步的操作(例如上文中的炖菜stew和炒菜fry_food)可以将其称之为Future,之所以用未来这个词,就是表达这个动作无需即可完成,而是可以等待至将来要执行的;
- 整个炖菜stew和炒菜fry(并非fry_food)是一个完整的任务,在完整的任务中,可能会有多个可以异步的动作(例如炖菜和炒菜)也可能有多个同步的动作(例如切菜cut),将这些需要完整完成的动作称之为Task;
- 对于存放数个任务的队列,类似于厨师chef的任务队列,将这些统称为运行时Runtime。
那么此时,就能罗列三者的关系:
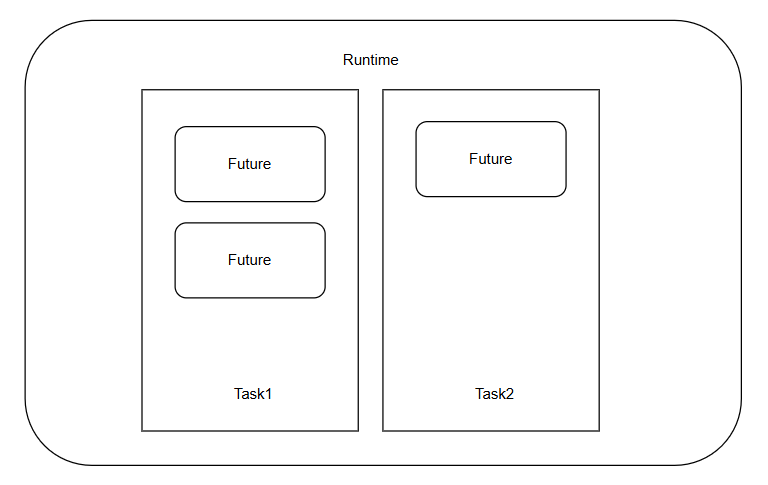
其中,Future是最小的描述可发生异步的对象,而Task是最小的可被调度的对象。
实际上,每次编写协程,都需要封装Future,再封装Task,再将Task注册到函数中,这个写法过于冗余,所以可以使用一种比较常见的语法糖来帮助实现这个流程,这个常见的语法糖就是async/await。
以之前的代码为例,当需要标志当前函数为一个Future,也就是它允许被异步执行的时候,可以这样写:
async func stew()
{
stew_until_finish_async();
}
通过这样声明,就能告知编译器,请将这个函数生成一个Future对象,并且将其包裹。这样一来,当调用这个函数的时候,就可以像前文提到的那种异步模型一样,直接膨胀出对应的处理代码,从而让其编程可异步的形式。
同样的,也需要另一个语法糖,用来告诉编译器需要等对应的函数完成后再执行接下来的函数,可以增加一个标记,这里暂定为await,那么写法就可以如下所示:
async func stew()
{
stew_until_finish_async();
}
func main_func()
{
// 等菜煮好我们再吃饭
await stew();
eat();
}
可以发现,语法糖的存在极大的简化了之前的逻辑,让整个程序变得更加轻便和容易编写。通过GPT将上述的例子转换成Rust代码,可以得到如下的形式:
use tokio::time::{sleep, Duration};
// 模拟炖菜:炖菜需要一定时间完成
async fn stew_until_finish() {
println!("Start stewing...");
sleep(Duration::from_secs(5)).await; // 模拟炖菜的时间
println!("Stewing finished!");
}
// 模拟切菜:切菜返回切好的食材
async fn cut_food() -> String {
println!("Start cutting food...");
sleep(Duration::from_secs(2)).await; // 模拟切菜的时间
let food = "cut food".to_string();
println!("Cutting finished!");
food
}
// 模拟炒菜:需要用切好的食材炒菜
async fn fry_food(food: String) {
println!("Start frying food with {}...", food);
sleep(Duration::from_secs(3)).await; // 模拟炒菜的时间
println!("Frying finished!");
}
// 炖菜协程
async fn stew() {
stew_until_finish().await;
}
// 炒菜协程
async fn fry() {
let food = cut_food().await; // 切菜完成后才能炒菜
fry_food(food).await;
}
// 做饭协程
async fn cook() {
let stew_task = tokio::spawn(stew()); // 启动炖菜的任务
let fry_task = tokio::spawn(fry()); // 启动炒菜的任务
// 等待所有任务完成
let _ = tokio::join!(stew_task, fry_task);
println!("Cooking finished!");
}
// 吃饭函数
fn eat() {
println!("Start eating...");
println!("Eating finished!");
}
// 主函数
#[tokio::main]
async fn main() {
println!("Start cooking...");
cook().await; // 做饭
eat(); // 吃饭
}
可以发现,其设计的协程模型的使用方式和我们这边推断出来的几乎一致。除去async/awa,task这个概念由tokio::spawn创建,等待由tokio::join!实现。
至此,便实现了对整个协程的初步认知。
3.5 不同语言与不同的协程
协程作为一种用户态提供的特性,意味着并没有一个严格的标准去限制它。所以在不同的语言中,这种特性的呈现形式也有所差异。前文中介绍的模型大致是统一的,但是在不同的语言实现中却有一定的差异。例如Future这个定义,在Python和Rust中的定义差异如下所示:
| 特性 | Python 中的 Future | Rust中的Future |
|---|---|---|
| 具体概念 | 用于描述异步操作的结果 | 作为Trait,是异步管理最小单位的抽象 |
| 挂起与唤醒 | 可以使用 await 等待,也是一种可等待对象 | 可以使用await等待,但是需要通过waker唤醒 |
同样的,在前面的例子中,还给出了go语言的例子,会发现在go语言中甚至没有出现async/await之类的关键字,而是使用了go/channel的组合实现。总的来说,在不同的语言中,协程的使用会表现出微妙的差异。
协程和线程并非是对立关系,实际上正如前文介绍的那样,协程和线程通常会构成M:N模型,从而保证程序的正常工作。此时的程序通常会存在所谓的worker_threads_pool工作线程池,这个线程池中的线程都会被协程用于调度。
四、总结
本文上篇主要介绍了协程的基本概念、起源及其在不同编程语言中的实现。通过厨师模型的介绍,逐步引领读者了解了这种协程的代码模型是如何产生的。同时,通过讨论在不同语言中的协程实现,介绍了不同语言的协程中存在的一些差异。
然而,协程虽然提升了并发编程的灵活性和效率,但不当的使用可能引发安全隐患。实际上,现代编程提供的各类特性往往是通过增添新的代码来实现的,对于未了解这些新特性实现细节的开发者,在开发过程中往往容易出现一些未知风险。在本文的下篇中,我们将会深入分析协程模型下常见的漏洞模式,揭露其潜安全风险和规避措施。