
在本文的上篇关于协程相关理论的介绍后,相信读者已经对协程有了大致的认识,所以接下来将会介绍在过去发生过的与协程相关的安全问题。因为协程在不同语言的实现差异,会导致其呈现的形式也会有所差异。本篇将选取几个比较有特征的案例介绍。
一、anyio - Race Condition
这个问题并没有获得CVE编号,是用户进行测试的时候发现的。anyio是一个 Python 异步网络并发库,可以在trio或者asyncio上运行。其完美的兼容了asyncio和trio,可以很方便的让代码进行重构。
然而这个库存在一个奇怪的问题,当尝试使用多线程访问这个库的时候,有概率触发一个库未初始化的问题。经过开发者定位,错误的代码位置如下:
def get_async_backend(asynclib_name: str | None = None) -> AsyncBackend:
if asynclib_name is None:
asynclib_name = sniffio.current_async_library()
modulename = "anyio._backends._" + asynclib_name
try:
module = sys.modules[modulename]
except KeyError:
module = import_module(modulename)
return getattr(module, "backend_class")
这段代码的逻辑本质上为取出anyio中视线的另一个module对象并返回。实际上,在普通程序中他也被这样使用:
async def sleep(delay: float) -> None:
"""
Pause the current task for the specified duration.
:param delay: the duration, in seconds
"""
return await get_async_backend().sleep(delay)
可以看到,其取出来的库是提供支持协程异步函数的库。然而,这种写法其实存在一定的迷惑性。例如:
async def func(d):
await asy().bfunc()
在这种写法中,这里的asy函数会是异步的吗?虽然这个函数前面存在一个await,但是实际上这个await是针对bfunc,而并非asy。所以上述的get_async_backend这个函数这个本身在设计之初实际上也并非完全考虑了异步的状态。
在上述代码中,下列的代码可能会存在竞争的问题:
try:
module = sys.modules[modulename]
except KeyError:
module = import_module(modulename)
这里的sys.modules是一个Python内置的全局对象,当我们第一次访问的时候,模块会尝试加载模块,然而此时存在一个竞争窗口,我们用数字描述线程的话,假定现在有两个线程,其分别运行到如下的位置:
try:
module = sys.modules[modulename] ## <= 线程2,刚开始访问这就modules
except KeyError:
module = import_module(modulename) ## <= 线程1,在这个函数内部
实际上,这里的sys.modules就是一个普通的字典,不存在线程保护。当这个模块还未彻底加载的时候,sys.modules[modulename]就已经会被初始化:
spec._initializing = True
try:
sys.modules[spec.name] = module ## <= 线程1,假设刚经过这里
try:
if spec.loader is None:
if spec.submodule_search_locations is None:
raise ImportError('missing loader', name=spec.name)
## A namespace package so do nothing.
else:
spec.loader.exec_module(module) ## 线程1还未来得及执行module的初始化函数
except:
此时,如果第二个线程来到上面指定的位置就加入的场合,就可能获取一个还未加载完成的模块。在这个场景下的线程2如果使用这个模块,就会造成一个条件竞争。
1.1 修复策略
对于这个漏洞的修复策略,官方的解决方案也很简单,就是自己本地维护一个加载的字典,这样就能保证在当前线程中,这个模块是安全的:
- def get_async_backend(asynclib_name: str | None = None) -> AsyncBackend:
+ def get_async_backend(asynclib_name: str | None = None) -> type[AsyncBackend]:
if asynclib_name is None:
asynclib_name = sniffio.current_async_library()
- modulename = "anyio._backends._" + asynclib_name
+ ## We use our own dict instead of sys.modules to get the already imported back-end
+ ## class because the appropriate modules in sys.modules could potentially be only
+ ## partially initialized
try:
- module = sys.modules[modulename]
+ return loaded_backends[asynclib_name]
except KeyError:
- module = import_module(modulename)
-
- return getattr(module, "backend_class")
+ module = import_module(f"anyio._backends._{asynclib_name}")
+ loaded_backends[asynclib_name] = module.backend_class
+ return module.backend_class
通过使用了一个自身维护的字典loaded_backends,保证其一定存放的是加载后的模块而非加载前的,从而避免问题的出现。
1.2 问题总结
这个问题本质上和协程关联不大,但是却和协程的存在形式有一定的关系。实际上API使用的时候,因为取出的模块实现的API支持协程,大多数情况下使用的模式都类似于:
await get_async_backend().sleep(delay)
这种写法会让开发者产生一定的疑惑,认为get_async_backend为支持异步的函数。而实际上,在最初的设计中,API是无法支持异步的。在使用API的时候,需要检查其内部是否为线程安全,否则的话可能需要优先考虑加锁,抑或是实现其他的workaround函数来回避这个问题。
二、Dashmap - Coroutine Dead Lock
dashmap在Rust中是一种对于hashmap的封装,可以简单的将其理解为对于RwLock<HashMap<K, V>>的抽象。这样在用户使用HashMap的时候,能够最大程度的保证对hashmap操作的原子性,从而保证其在多线程中的安全。
dashmap中,如果我们尝试访问一个对象,那么他会给我们加上一个读锁,如果我们尝试修改一个对象,它会给我们加上一个写锁。
Dashmap在使用的过程中,存在一个容易出现的问题。这个问题笔者在实际的开发中也遇到过 。问题说明详见Dashmap的官方文档,其例子大致如下:
use dashmap::DashMap;
use futures::future::join_all;
use std::time::Duration;
use tokio;
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let tasks: DashMap<i32, i32> = DashMap::new();
let t = &tasks;
let mut async_events = vec![];
for i in 0..30 {
tasks.insert(i, i);
async_events.push(async move {
let j = i;
if let Some(_) = t.get(&j) {
tokio::time::delay_for(Duration::from_secs(1)).await;
}
if let Some(_) = t.get_mut(&j) {
tokio::time::delay_for(Duration::from_secs(1)).await;
}
});
}
join_all(async_events).await;
println!("Hello, world!");
Ok(())
}
与上一个问题不同的是,这个问题只会发生在协程中。为了更加简化程序,假设在这个模型中,只存在一个线程以及两个协程AB,那么此时问题的现象如下:
- 协程A 来到了
get的逻辑中,获取了读锁,并且获取了分片a,然后因为delay.await的原因切换出去 - 协程B 来到了
get_mut逻辑中,获取写锁,然而由于协程A已经获取了读锁,协程B陷入了死锁阶段
换句话说,在上述代码中,极易出现死锁现象,其会表现成所有的协程都卡死的这种状态。
2.1 为什么会死锁?程序不会继续运行吗?
这个是一个很有意思的问题,因为在传统的线程模型中,这个场景理论上不会发生死锁,他的执行逻辑大概是这样的:
- 线程A 来到了
get的逻辑中,获取了读锁,并且获取了分片a,接下来遇到thread::sleep函数之后,程序切换上下文来到另一个线程 - 线程B 经过了前面的
get逻辑,并且穿过了sleep,来到了get_mut逻辑中,获取写锁,然而由于线程A已经获取了读锁,线程B陷入锁状态,此时被调度出来 - 线程A 完成睡眠操作,来到后续的
get_mut操作,由于此时没有锁,于是顺利执行完成 - 线程B 等线程A执行完成后,成功获得锁,也顺利执行完成
但是,在协程中,这个问题却无法得到解决,这是为什么呢?这就要回到最初聊到的协程的原理上。协程并非线程,他的切换上下文是由程序本身控制的,这就意味着,程序无法从自身的运行状态中脱离。回到这个代码中,前面说过,协程本质上是编译器提供的辅助代码实现的,所以这里可以尝试检查这一段rust代码展开辅助代码后的形式。可以看到它展开后的代码如下:
if let Some(_) = t.get_mut(&j)
{
match #[lang = "into_future"](tokio::time::sleep(Duration::from_secs(1)))
{
mut __awaitee =>
loop {
match unsafe {
#[lang = "poll"](#[lang = "new_unchecked"](&mut __awaitee),
#[lang = "get_context"](_task_context))
} {
#[lang = "Ready"] { 0: result } => break result,
#[lang = "Pending"] {} => { }
}
_task_context = (yield ());
},
};
}
可以看到,这里的实现和上篇中提到的厨师模型中的协程模式很像,也是使用了生成器编程模式视线的临时性退出函数。 然而仔细看这里的逻辑会发现,程序只有在尝试完成了get_mut函数的调用,才会去调用后面的poll函数和yield函数。所以此处无法发生上下文的切换,自然也不能像之前的多线程模式,强行的切换到另一个线程从而解开锁。
2.2 解决办法
要解决这个问题也很简单,在Rust开发中,声明周期其实非常重要,所以这里只要保证dashmap取出的对象生命周期不要越过await即可回避这个问题。一种比较丑陋的解决办法是:
let mut t_value = 0;
// 先将数据拿出来
if let Some(value) = t.remove(&j) {
t_value = value.1;
}
// 在外部处理完成
tokio::time::sleep(Duration::from_secs(1)).await;
// 最后在塞回去
t.insert(j, t_value);
实际上,这里的处理逻辑完全可以通过一些别的方法进行回避,这就只能case-by-case的解决了。
三、containerd - CVE-2022-23471 memory exhaustion
每一个用docker的人应该都听过这个库,实际上,它就是近些年来容器生态中最关键也最流行的底层组件。containerd为云原生环境提供了稳定的基础设施支持。
然而在这个库中,也存在着一个因为协程而导致的内存耗尽的问题,利用这个问题会导致宿主机的运行环境内存耗尽,最终实现对整个宿主的DoS攻击。
在官方公告中提到,漏洞出现在containerd的CRI(Container Runtime Interface)中,当用户尝试利用某些指令执行容器指令,并且这个指令会要求容器提供的TTY的时候,容器会发起一个resizeEvent,然而如果此时的指令由于某种原因未能成功执行,例如用户命令错误或故障,就会导致处理resizeEvent的协程卡住,从而造成一个内存耗尽的问题。
不过在谈到Go的协程的时候,由于go的协程和其他语言的协程有所差异,这里首先展示一个go语言中比较特殊的一个点。
3.1 goroutine 与 channel
在go语言中,协程的实现有点差异,其运行的协程被称之为goroutine,并且使用了一种叫做channel的概念来实现其他语言中类似同步的功能。当需要获得某个数据的运行结果的时候,go语言会使用channel将这个数据送出去,此时goroutine会处于hang的状态,直到存在一个receiver将这个值接受后,goroutine才会继续运行。
下面的例子展示了go语言中常见的死锁场景例:
package main
import (
"fmt"
"sync"
)
func main() {
ch := make(chan int) // 无缓冲通道
var wg sync.WaitGroup
// 启动多个 goroutine
for i := 0; i < 3; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
fmt.Printf("Goroutine %d: Sending data to channel...\n", id)
ch <- id // 阻塞在这里
fmt.Printf("Goroutine %d: Finished sending data.\n", id)
}(i)
}
fmt.Println("Main: Waiting for goroutines to finish...")
wg.Wait()
}
由于在主线程中加入了WaitGroup,只有goroutine执行结束之后,主程序才会结束。然而,在下列代码运行的结果会提示所有的goroutine都卡死了,因为这里的channel找不到接收对象,所以go语言会直接报错,结束这个程序。然而在现实中,这种死锁的goroutine只会不断的增加个,从而造成资源的消耗。
3.2 containerd 中的死锁位置
在知道了漏洞点后,这里首先列出有问题的关键函数:
func createStreams(req *http.Request, w http.ResponseWriter, opts *Options, supportedStreamProtocols []string, idleTimeout, streamCreationTimeout time.Duration) (*context, bool) {
var ctx *context
var ok bool
if wsstream.IsWebSocketRequest(req) {
ctx, ok = createWebSocketStreams(req, w, opts, idleTimeout)
} else {
ctx, ok = createHTTPStreamStreams(req, w, opts, supportedStreamProtocols, idleTimeout, streamCreationTimeout)
}
if !ok {
return nil, false
}
if ctx.resizeStream != nil {
ctx.resizeChan = make(chan remotecommand.TerminalSize)
go handleResizeEvents(ctx.resizeStream, ctx.resizeChan)
}
return ctx, true
}
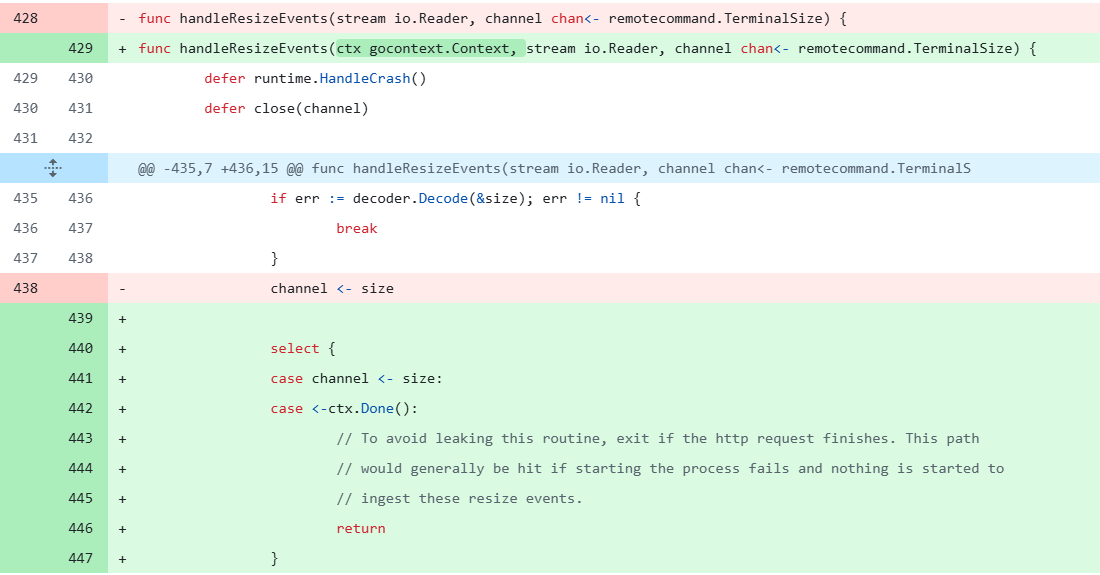
func handleResizeEvents(stream io.Reader, channel chan<- remotecommand.TerminalSize) {
defer runtime.HandleCrash()
defer close(channel)
decoder := json.NewDecoder(stream)
for {
size := remotecommand.TerminalSize{}
if err := decoder.Decode(&size); err != nil {
break
}
channel <- size // 注意这里!
}
}
在函数handleResizeEvents中,能看到这个channel <- size,这个channel的定义为channel chan<- remotecommand.TerminalSize。显然这个channel就是前文提到过的用于数据传输的channel。从函数名可以推断,这个函数的作用是用来检查一个resize事件,于是可以检查对应的事件函数的位置,可以找到如下的函数:
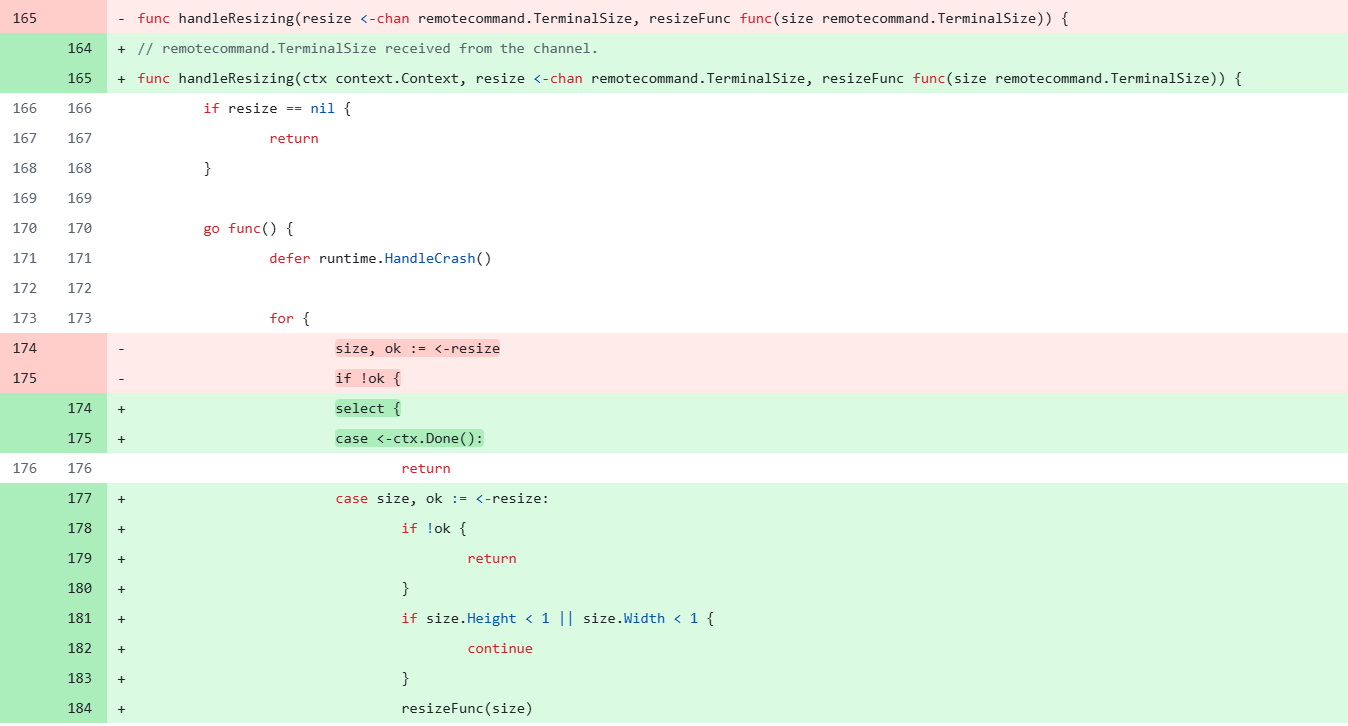
// handleResizing spawns a goroutine that processes the resize channel, calling resizeFunc for each
// remotecommand.TerminalSize received from the channel.
func handleResizing(resize <-chan remotecommand.TerminalSize, resizeFunc func(size remotecommand.TerminalSize)) {
if resize == nil {
return
}
go func() {
defer runtime.HandleCrash()
for {
size, ok := <-resize
if !ok {
return
}
if size.Height < 1 || size.Width < 1 {
continue
}
resizeFunc(size)
}
}()
}
根据参数可知,在处理command的时候才会调用这个函数,于是可以检查调用处的函数,这里以exec为例:
// execInContainer executes a command inside the container synchronously, and
// redirects stdio stream properly.
// This function only returns when the exec process exits, this means that:
// ---------------------- 留意这里 ------------------------------------
// 1) As long as the exec process is running, the goroutine in the cri plugin
// will be running and wait for the exit code;
// --------------------------------------------------------------------
func (c *criService) execInContainer(ctx context.Context, id string, opts execOptions) (*uint32, error) {
span := tracing.SpanFromContext(ctx)
// Get container from our container store.
cntr, err := c.containerStore.Get(id)
if err != nil {
return nil, fmt.Errorf("failed to find container %q in store: %w", id, err)
}
id = cntr.ID
span.SetAttributes(tracing.Attribute("container.id", id))
state := cntr.Status.Get().State()
if state != runtime.ContainerState_CONTAINER_RUNNING {
return nil, fmt.Errorf("container is in %s state", criContainerStateToString(state))
}
return c.execInternal(ctx, cntr.Container, id, opts)
}
func (c *criService) execInternal(ctx context.Context, container containerd.Container, id string, opts execOptions) (*uint32, error) {
// 省略一些别的代码
spec, err := container.Spec(ctx)
if err != nil {
return nil, fmt.Errorf("failed to get container spec: %w", err)
}
task, err := container.Task(ctx, nil)
if err != nil {
return nil, fmt.Errorf("failed to load task: %w", err)
}
pspec := spec.Process
pspec.Terminal = opts.tty
if opts.tty {
if err := oci.WithEnv([]string{"TERM=xterm"})(ctx, nil, nil, spec); err != nil {
return nil, fmt.Errorf("add TERM env var to spec: %w", err)
}
}
pspec.Args = opts.cmd
// CommandLine may already be set on the container's spec, but we want to only use Args here.
pspec.CommandLine = ""
if opts.stdout == nil {
opts.stdout = cio.NewDiscardLogger()
}
if opts.stderr == nil {
opts.stderr = cio.NewDiscardLogger()
}
execID := util.GenerateID()
log.G(ctx).Debugf("Generated exec id %q for container %q", execID, id)
volatileRootDir := c.getVolatileContainerRootDir(id)
var execIO *cio.ExecIO
// 这里执行指令
process, err := task.Exec(ctx, execID, pspec,
func(id string) (containerdio.IO, error) {
cntr, err := c.containerStore.Get(container.ID())
if err != nil {
return nil, fmt.Errorf("an error occurred when try to find container %q: %w", container.ID(), err)
}
sb, err := c.sandboxStore.Get(cntr.SandboxID)
if err != nil {
return nil, fmt.Errorf("an error occurred when try to find sandbox %q: %w", cntr.SandboxID, err)
}
ociRuntime, err := c.config.GetSandboxRuntime(sb.Config, sb.Metadata.RuntimeHandler)
if err != nil {
return nil, fmt.Errorf("failed to get sandbox runtime: %w", err)
}
switch ociRuntime.IOType {
case config.IOTypeStreaming:
execIO, err = cio.NewStreamExecIO(id, sb.Endpoint.Address, opts.tty, opts.stdin != nil)
default:
execIO, err = cio.NewFifoExecIO(id, volatileRootDir, opts.tty, opts.stdin != nil)
}
return execIO, err
},
)
// 调用resize函数
handleResizing(ctx, opts.resize, func(size remotecommand.TerminalSize) {
if err := process.Resize(ctx, uint32(size.Width), uint32(size.Height)); err != nil {
log.G(ctx).WithError(err).Errorf("Failed to resize process %q console for container %q", execID, id)
}
})
}
以exec指令为例,我们能看到,这里的execInternal中显示的调用了handleResizing,然而其的调用存在一个前提,那就是Task.exec执行成功。这个tast.exec其实就是对指令的执行。显然,当没能正确的调用exec的时候,这个协程就会因为错误提前退出,此时的handleResizing将不会得到合适的机会执行。
从问题链接描述中可以知道,当出现下列情况的时候,就会造成内存泄露的问题:
- 容器支持
unix socket - 用户使用
kubectl或者crictl指令(未测试,但是猜测docker指令也可)执行一个容器指令,并且容器指令执行错误
如果满足上述条件,goroutine就会慢慢增长,最终导致内存耗尽。
在实际场景中,虽然绝大多数的场合中,用户都只能对容器内部进行访问,然而在运维场景场景下,攻击者就有可能会控制这些传递的指令,从而对控制集群的机器本身进行内存耗尽攻击。
3.3 修复策略
实际上,containrd在指令执行错误等场景下,会修改ctx的执行状态。所以修复的时候,只需要增加对这个状态的判断,即可回避这个问题:
四、envoy - coroutine with UAF CVE-2023-27492
在之前描述的漏洞中,似乎只提到了可能造成拒绝服务的问题,这边要展示一个协程可能会造成的比较严重的UAF问题。
Envoy是一个云原生高性能边缘/中间层/服务代理,广泛用于微服务架构和现代应用程序的网络流量管理。其主要也是对容器化,动态调度和微服务提供支持。
Envoy支持多种插件,其中它的HTTP过滤器支持使用lua语言在请求和相应流中编写脚本:
name: envoy.filters.http.lua
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.lua.v3.Lua
default_source_code:
inline_string: |
-- Called on the request path.
function envoy_on_request(request_handle)
-- Do something.
end
-- Called on the response path.
function envoy_on_response(response_handle)
-- Do something.
end
在Lua中,也是支持coroutine这个特性的,在这个库中存在的Lua引擎自然也是实现了这一点。然而,由于这个Lua脚本本质上为对HTTP过滤器的支持,导致Lua引擎部分与库本身的运行逻辑绑定,从而诱发了一个问题。
4.1 程序运行与UAF
在Envoy HTTP filters的处理逻辑中,为了防止输入数据太大,其允许手动设置单次可以处理的数据。如果需要处理的数据太大了,其会调用一个叫做SendLocalReply的函数,直接构造一个返回数据包,并且标记当前Filter为可销毁对象。
// envoy/source/common/http/filter_manager.cc
// 这里负责主动设置接受数据的上下限,并且给出当数据超出上线/下线的时候,会调用的对应处理函数
// 在这里会限制发送数据和返回数据的大小限制
void FilterManager::setBufferLimit(uint32_t new_limit) {
ENVOY_STREAM_LOG(debug, "setting buffer limit to {}", *this, new_limit);
buffer_limit_ = new_limit;
if (buffered_request_data_) {
buffered_request_data_->setWatermarks(buffer_limit_);
}
if (buffered_response_data_) {
buffered_response_data_->setWatermarks(buffer_limit_);
}
}
// 这里是创建对应给Filter使用的buffer对象数据的时候,设置传输数据的边界
Buffer::InstancePtr ActiveStreamDecoderFilter::createBuffer() {
auto buffer = dispatcher().getWatermarkFactory().createBuffer(
[this]() -> void { this->requestDataDrained(); },
[this]() -> void { this->requestDataTooLarge(); }, // above_high_watermark_
[]() -> void { /* TODO(adisuissa): Handle overflow watermark */ });
buffer->setWatermarks(parent_.buffer_limit_);
return buffer;
}
// 当接收到的数据太大的时候,会直接发送返回数据
void ActiveStreamDecoderFilter::requestDataTooLarge() {
ENVOY_STREAM_LOG(debug, "request data too large watermark exceeded", parent_);
if (parent_.state_.decoder_filters_streaming_) {
onDecoderFilterAboveWriteBufferHighWatermark();
} else {
parent_.filter_manager_callbacks_.onRequestDataTooLarge();
sendLocalReply(Code::PayloadTooLarge, CodeUtility::toString(Code::PayloadTooLarge), nullptr,
absl::nullopt, StreamInfo::ResponseCodeDetails::get().RequestPayloadTooLarge);
}
}
//发送返回数据
void ActiveStreamFilterBase::sendLocalReply(
Code code, absl::string_view body,
std::function<void(ResponseHeaderMap& headers)> modify_headers,
const absl::optional<Grpc::Status::GrpcStatus> grpc_status, absl::string_view details) {
if (!streamInfo().filterState()->hasData<LocalReplyOwnerObject>(LocalReplyFilterStateKey)) {
streamInfo().filterState()->setData(
LocalReplyFilterStateKey,
std::make_shared<LocalReplyOwnerObject>(filter_context_.config_name),
StreamInfo::FilterState::StateType::ReadOnly,
StreamInfo::FilterState::LifeSpan::FilterChain);
}
parent_.sendLocalReply(code, body, modify_headers, grpc_status, details);
}
// envoy/source/common/buffer/watermark_buffer.cc
// 这边会设置接受数据的上限和下限,然后调用对应的处理函数
// 这里负责记录数据的上限
// 默认定义函数,这里的setWatermarks第二个参数可以是0
void setWatermarks(uint32_t high_watermark, uint32_t overflow_watermark = 0) override;
void WatermarkBuffer::setWatermarks(uint32_t high_watermark,
uint32_t overflow_watermark_multiplier) {
if (overflow_watermark_multiplier > 0 &&
(static_cast<uint64_t>(overflow_watermark_multiplier) * high_watermark) >
std::numeric_limits<uint32_t>::max()) {
ENVOY_LOG_MISC(debug, "Error setting overflow threshold: overflow_watermark_multiplier * "
"high_watermark is overflowing. Disabling overflow watermark.");
overflow_watermark_multiplier = 0;
}
low_watermark_ = high_watermark / 2;
high_watermark_ = high_watermark;
overflow_watermark_ = overflow_watermark_multiplier * high_watermark;
checkHighAndOverflowWatermarks();
checkLowWatermark();
}
// 这里会检查接受的数据是否过多/过少
void WatermarkBuffer::checkHighAndOverflowWatermarks() {
if (high_watermark_ == 0 || OwnedImpl::length() <= high_watermark_) {
return;
}
if (!above_high_watermark_called_) {
above_high_watermark_called_ = true;
above_high_watermark_();
}
// Check if overflow watermark is enabled, wasn't previously triggered,
// and the buffer size is above the threshold
if (overflow_watermark_ != 0 && !above_overflow_watermark_called_ &&
OwnedImpl::length() > overflow_watermark_) {
above_overflow_watermark_called_ = true;
above_overflow_watermark_();
}
}
可以看到,程序主要是对一个缓存区buffer的大小进行了限制。当过滤器对请求数据进行存储的时候,这个缓存区就会被创建。
程序提供的各类过滤器中,Lua filter 可以对接收到的数据进行存储,修改,甚至自己构造新的数据。在请求数据到达的时候,Filter可以进行数据处理,其的处理逻辑如下:
Http::FilterDataStatus StreamHandleWrapper::onData(Buffer::Instance& data, bool end_stream) {
ASSERT(!end_stream_);
end_stream_ = end_stream;
saw_body_ = true;
if (state_ == State::WaitForBodyChunk) {
ENVOY_LOG(trace, "resuming for next body chunk");
Filters::Common::Lua::LuaDeathRef<Filters::Common::Lua::BufferWrapper> wrapper(
Filters::Common::Lua::BufferWrapper::create(coroutine_.luaState(), headers_, data), true);
state_ = State::Running;
coroutine_.resume(1, yield_callback_);
} else if (state_ == State::WaitForBody && end_stream_) {
ENVOY_LOG(debug, "resuming body due to end stream");
callbacks_.addData(data); // 注意这里
state_ = State::Running;
coroutine_.resume(luaBody(coroutine_.luaState()), yield_callback_);
} else if (state_ == State::WaitForTrailers && end_stream_) {
ENVOY_LOG(debug, "resuming nil trailers due to end stream");
state_ = State::Running;
coroutine_.resume(0, yield_callback_);
}
if (state_ == State::HttpCall || state_ == State::WaitForBody) {
ENVOY_LOG(trace, "buffering body");
return Http::FilterDataStatus::StopIterationAndBuffer;
} else if (state_ == State::Responded) {
return Http::FilterDataStatus::StopIterationNoBuffer;
} else {
headers_continued_ = true;
return Http::FilterDataStatus::Continue;
}
}
代码中可以看到不同的状态,这些状态用于描述当前Lua 脚本运行状态。根据不同的运行状态,它会来到不同的书记处理流程。如果此时Lua Filter中,程序尝试保留当前请求,例如调用local initial_req_body = request_handle:body()获取数据的时候,其会调用的addData中,将数据保存在本地。此时其中的addData包含如下的逻辑:
void PlatformBridgeFilter::RequestFilterBase::addData(envoy_data data) {
Buffer::OwnedImpl inject_data;
inject_data.addBufferFragment(*Buffer::BridgeFragment::createBridgeFragment(data));
parent_.decoder_callbacks_->addDecodedData(inject_data, /* watermark */ false);
}
void FilterManager::addDecodedData(ActiveStreamDecoderFilter& filter, Buffer::Instance& data,
bool streaming) {
if (state_.filter_call_state_ == 0 ||
(state_.filter_call_state_ & FilterCallState::DecodeHeaders) ||
(state_.filter_call_state_ & FilterCallState::DecodeData) ||
((state_.filter_call_state_ & FilterCallState::DecodeTrailers) && !filter.canIterate())) {
// Make sure if this triggers watermarks, the correct action is taken.
state_.decoder_filters_streaming_ = streaming;
// If no call is happening or we are in the decode headers/data callback, buffer the data.
// Inline processing happens in the decodeHeaders() callback if necessary.
filter.commonHandleBufferData(data);
// 省略部分代码
}
}
void ActiveStreamFilterBase::commonHandleBufferData(Buffer::Instance& provided_data) {
// The way we do buffering is a little complicated which is why we have this common function
// which is used for both encoding and decoding. When data first comes into our filter pipeline,
// we send it through. Any filter can choose to stop iteration and buffer or not. If we then
// continue iteration in the future, we use the buffered data. A future filter can stop and
// buffer again. In this case, since we are already operating on buffered data, we don't
// rebuffer, because we assume the filter has modified the buffer as it wishes in place.
if (bufferedData().get() != &provided_data) {
if (!bufferedData()) {
bufferedData() = createBuffer(); //可以看到这里创建了对应的buffer对象
}
bufferedData()->move(provided_data);
}
}
可以看到,当filter保留数据的时候,此时程序会将数据缓存在前文提到的buffer缓存区中。在这个缓存区中,会检查当前数据的大小是否超出了预期。如果超出预期的情况下,数据会调用SendLocalReply,尝试异步的发送返回数据包。当程序发现当前Filter已经处理过回显数据包后,会销毁当前关联的上下文,包含对应的filter:
void Filter::onDestroy() {
destroyed_ = true;
if (request_stream_wrapper_.get()) {
request_stream_wrapper_.get()->onReset();
}
if (response_stream_wrapper_.get()) {
response_stream_wrapper_.get()->onReset();
}
}
然而,当程序发送返回数据包的时候,其产生的response会再次触发Lua Filter,然而由于该对象已经被销毁,所以在运行的时候会造成segmentation fault。
可以从官方的poc来学习这个漏洞的成因:
R"EOF(
name: lua
typed_config:
"@type": type.googleapis.com/envoy.extensions.filters.http.lua.v3.Lua
default_source_code:
inline_string: |
function envoy_on_request(request_handle)
local initial_req_body = request_handle:body()
local headers, body = request_handle:httpCall(
"lua_cluster",
{
[":method"] = "POST",
[":path"] = "/",
[":authority"] = "lua_cluster"
},
"hello world",
1000)
request_handle:headers():replace("x-code", headers["code"] or "")
end
)EOF";
最初的时候,lua脚本截获了一个请求(假定这个请求的数据特别大)
此时,lua脚本获取这个请求body:
local initial_req_body = request_handle:body()
此时请求的数据大小被设置为能够接受的buffer限制的最大值+1,超过了最大值(参考官方poc这里写的)
const int buffer_limit = 65535;
config_helper_.setBufferLimits(buffer_limit, buffer_limit);
initializeFilter(FILTER_AND_CODE);
codec_client_ = makeHttpConnection(lookupPort("http"));
auto encoder_decoder =
codec_client_->startRequest(Http::TestRequestHeaderMapImpl{{":method", "POST"},
{":scheme", "http"},
{":path", "/test/long/url"},
{":authority", "host"}});
auto request_encoder = &encoder_decoder.first;
auto response = std::move(encoder_decoder.second);
codec_client_->sendData(*request_encoder, buffer_limit + 1, true);
回到Lua 这边,此时的Filter解析会来到这个逻辑,然而由于数据过大,当这条逻辑执行完成的时候,会提示Envoy的处理逻辑会发出错误提醒:
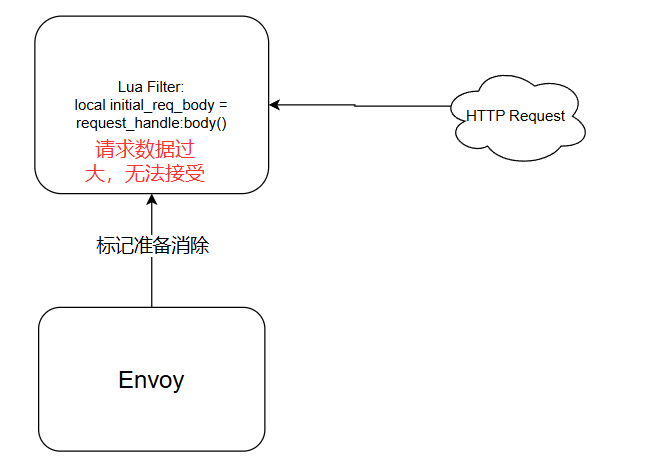
但是由于函数本身是异步的原因,此时的程序并不会当即发送response,而是进行了标记。同时由于发送了reply,当前filter被标记可被消除的状态,此时会调用一个叫做OnReset的函数,标记当前HTTP请求已经被重置了:
void onReset() {
if (http_request_) {
http_request_->cancel();
http_request_ = nullptr;
}
}
Http::FilterDataStatus StreamHandleWrapper::onData(Buffer::Instance& data, bool end_stream) {
callbacks_.addData(data); // 来到前面提到的添加数据的部分逻辑,因为数据过大,此时数据发生错误,但是只是被标记为可消除
state_ = State::Running;
coroutine_.resume(luaBody(coroutine_.luaState()), yield_callback_); // 此时调用协程,回到正常Lua脚本处理逻辑中
}
然而对于lua层面,其无法感知到这个过程,所以其还是顺利的来到了coroutine协程的逻辑,协程直接退出至正常逻辑,并且来到后续的处理逻辑上:
local headers, body = request_handle:httpCall(
"lua_cluster",
{
[":method"] = "POST",
[":path"] = "/",
[":authority"] = "lua_cluster"
},
"hello world",
1000)
此时对应的filter会产生一个新的HTTP请求,然而在这个请求过程中,由于其为异步请求,所以此时程序发送完数据后,会将之前挂起的异步对象的生命周期进行处理,其中就包括被标记为清除的filter,于是此时的lua filter被清除。
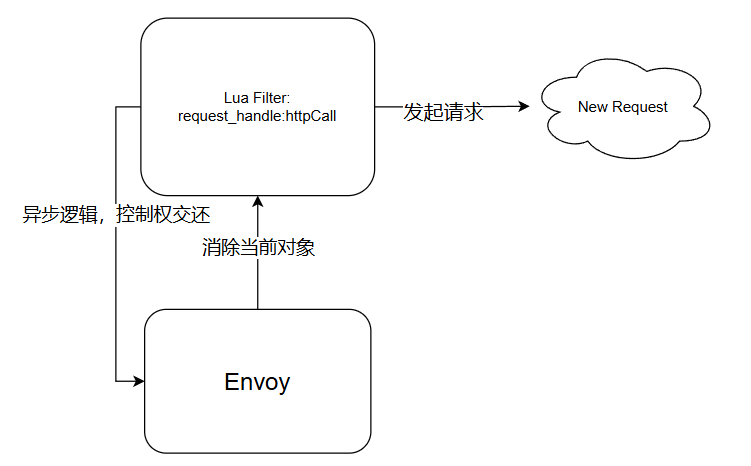
然而,Filter发起的请求最终还是会产生一个相应的响应数据,此时之前被挂起的协程被调度,包括之前addData后的那个协程,然而对应的filter 早在之前因为OnReset被清除,所以此时访问了一个不可访问的对象,最终导致了漏洞的发生。
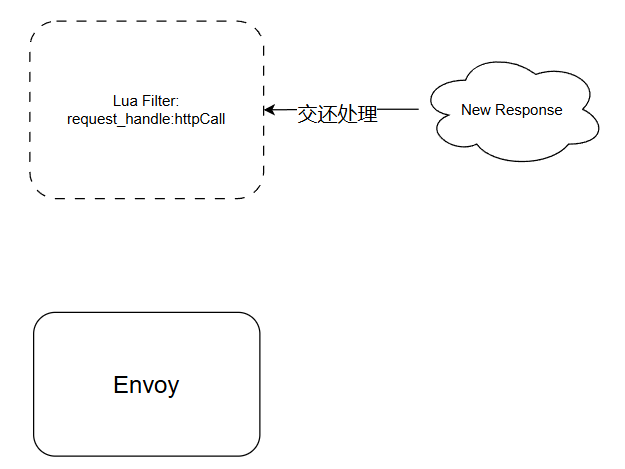
4.2 修复策略
为了避免协程的问题, 其修复逻辑如下:
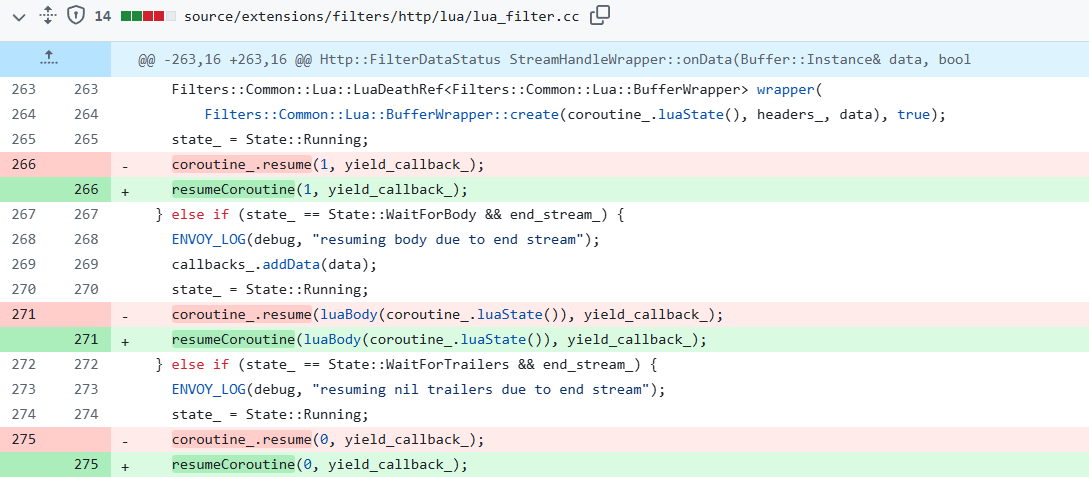
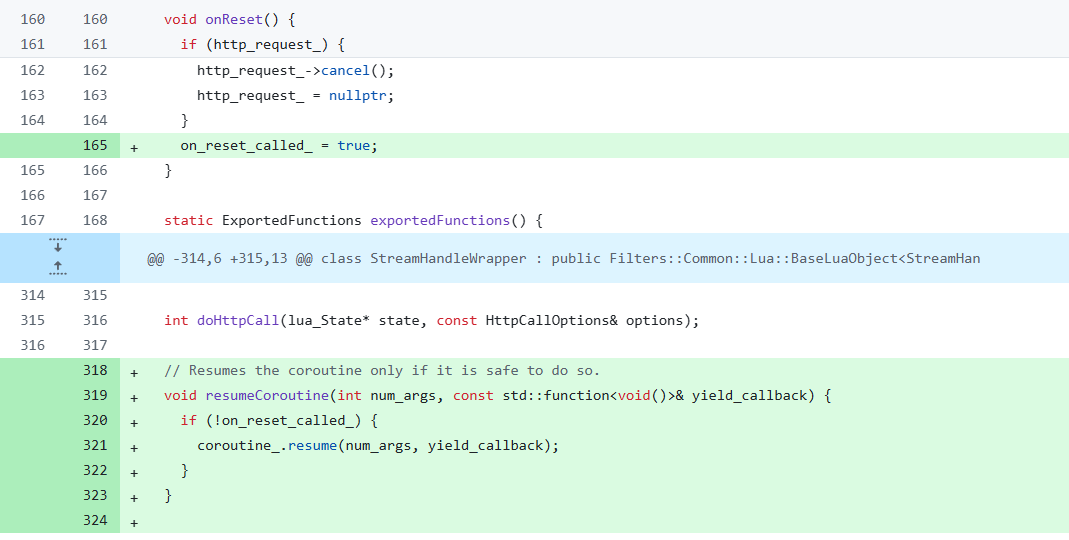
此时,当再次尝试调用resume恢复对应的Lua 协程对象的时候,由于看到这个on_reset_called_被设置,主要逻辑不在会再尝试拉起对应的Lua coroutine,从而避免了问题的出现。
五、总结
与传统的多线程安全问题相比,协程安全模型引入了几个不同的要点:
- 开发者编写的代码,与实际生成的代码存在一定的差异
- 协程并非操作系统特性,这意味着改特性并不受到操作系统的安全防护
- 与线程相比,协程本质上是一种手工切换上下文的过程
上述特点就导致了这个特性存在一些与传统安全模型的差异,既无法看到其完整的调用逻辑,在开发过程中需要时刻对齐资料。例如,协程会导致程序从执行过程中切换出去,这就意味着传统线程安全中的局部变量的范围需要重新考量。在使用这类特性的时候,开发者需要时刻保持对语言特性的知识对齐,才能保证其使用的安全性。