
一、前言
本文介绍了Intel CPU Processor Trace这个特性,介绍Windows平台如何使用Intel PT这一特性,这里主要参考了这个开源项目:(https://github.com/intelpt/WindowsIntelPT)。在最后,结合Intel PT这一技术探讨其使用场景。
二、什么是CPU跟踪技术?
Intel Process Trace(以下称为Intel PT)是Intel处理器中的一项拓展功能,这个功能可以使用处理器中专用的硬件设施捕获软件的执行信息。在开启了Intel PT功能时,CPU处于软件执行流信息捕获的状态下,捕获执行流的操作只会对被捕获的软件性能干扰很小。相比于通过动态插桩的方式进行执行流信息收集,Intel PT对性能的影响很小,这一个优势在复现或者挖掘某些需要竞争的漏洞时会凸显出来,往往一些竞争类漏洞的复现会和代码执行的时机相关,那么代码插桩或者开启一些调试参数或者调试器时,对于漏洞的复现都会有影响,Intel PT技术就可以在这个时候背后"默默"观察执行流。
Intel PT生成的跟踪数据流中包含了多种的数据包,这些数据包直接由CPU硬件生成,并且"实时"写入到物理内存中,并且这些数据经过压缩,无法直接通过读取数据得到执行流的跟踪信息。如果我们要读取Intel PT生成的实时跟踪数据的话,不光要对CPU生成的数据包进行解码,还要获取到被跟踪的二进制文件中的信息才能恢复出当前生成的实时执行流的虚拟地址。关于数据包的格式会在下文中介绍。
那么,Intel PT具体有哪些能力呢?
Intel PT功能中可以针对特定CR3寄存器的值进行代码执行流跟踪,这个功能是CPU中的硬件实现的,不需要我们在使用时进行人为过滤。我们可以在Intel PT功能中设置不同的CR3寄存器数值,实现跟踪指定进程的能力。并且我们可以设置Intel PT功能的控制寄存器来选择让Intel PT是否跟踪特定权限下的代码流,这样便可以实现只跟踪用户态的代码流,或者只跟踪内核态的代码流,或者不限CPL全部跟踪,同样地,这个能力也是CPU硬件实现的,我们只需配置好控制寄存器就可以了。
Intel PT还可以设置虚拟地址过滤,可以通过配置Intel PT控制寄存器来让CPU在执行特定的IP范围内的代码时生成跟踪数据流。这个功能在使用Intel PT功能跟踪驱动时非常有用,我们可以设置要跟踪的驱动的地址范围来让Intel PT生成要跟踪的驱动的代码流数据。
我们还可以配置Intel PT控制寄存器生成TSC(Time Stamp Counter)数据包,这个TSC数据包可以用来分析各个事件或者组件之间的在某一个时刻的运行的代码流,分析出在某一个时刻不同事件的关联,有助于发现程序中的并发问题或者竞争问题。这个TSC数据包还可以用于分析软件性能,用于找出编码中的性能瓶颈。
Intel PT算不上是新技术,但是这个功能在Intel 7代以后的CPU才被完整的支持。所以本文用作示例的CPU型号为:Intel Pentium 4405U。下面我们来具体看看Intel PT的技术细节&配置。
三、Intel PT 数据包
下面简单介绍下Intel PT生成的常用的数据包。
a) 执行流基本信息的数据包:
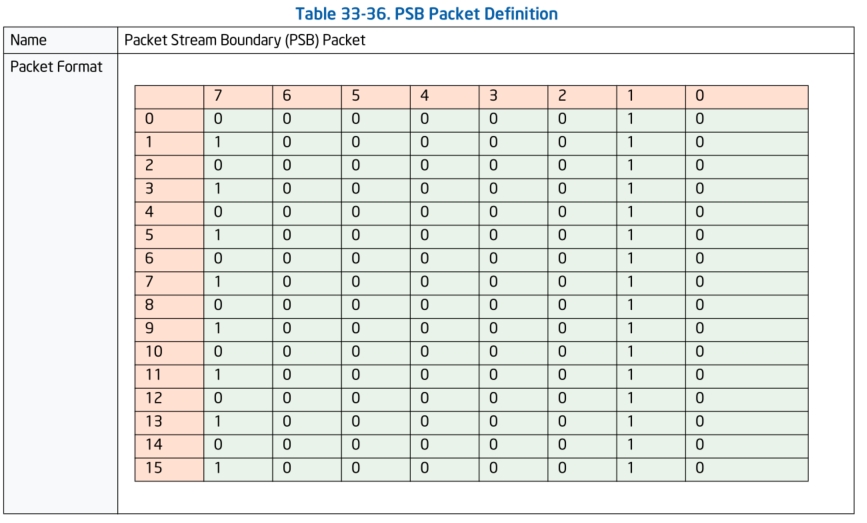
PSB(Packet Stream Boundary)数据包:
PSBEND数据包:
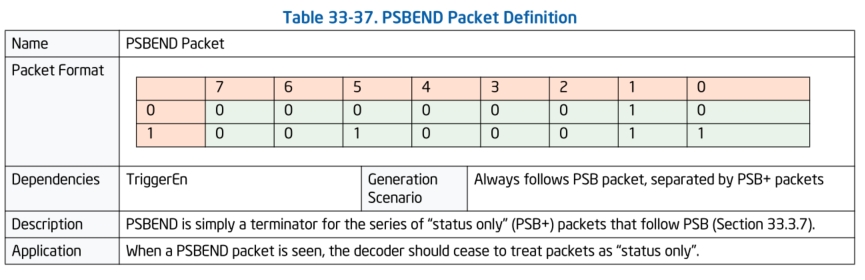
PSB和PSBEND数据包全部都是固定编码,PSB数据包被pt解码器用作寻找数据流中的数据包的边界,当解码跟踪数据时,解码器要先找到PSB数据包,它的作用更像是边界。 在PSB和PSBEND数据包之间的数据被解码器理解成"status only"数据包,例如:TSC(时间戳),TMA(时间戳MTC对齐),PIP(分页信息),CBR(核心总线速率),MODE.TSX,MODE.Exec(运行在多少bit模式下),FUP这些数据包。
PIP数据包:
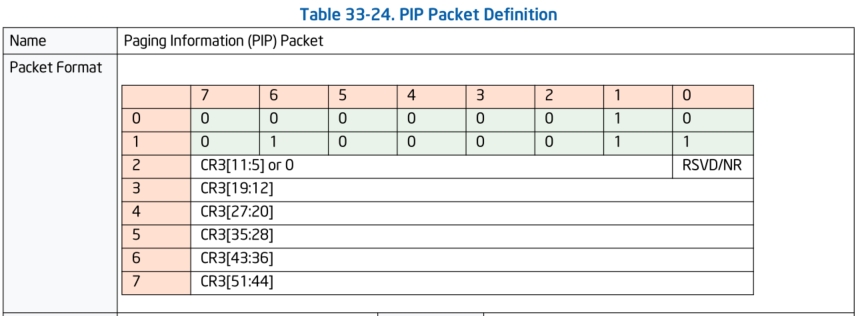
PIP数据包是用来记录对CR3寄存器修改的数据包。
TSC数据包:
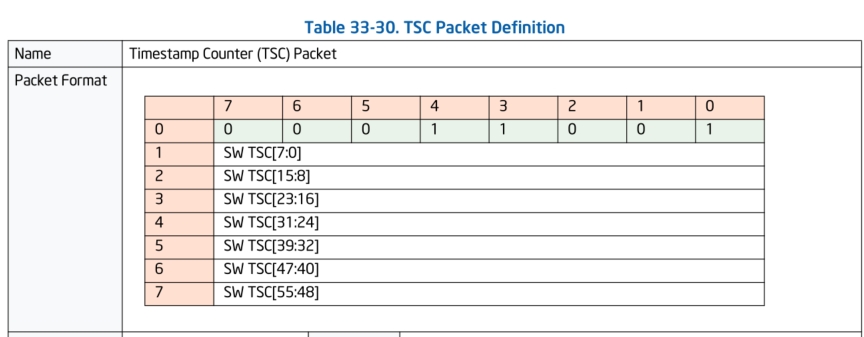
TSC是生成时间戳数据包,这个数据包对多线程多组件之间同步有大用处。
OVF数据包:
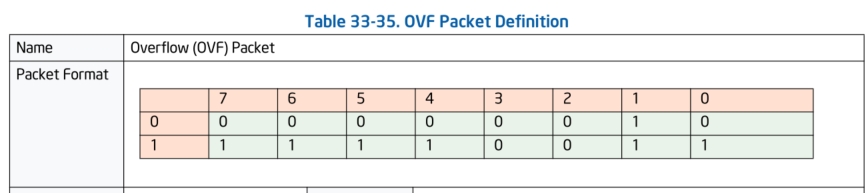
OVF会在处理器内部发生缓冲区溢出时生成,标志着当前有数据包丢失的情况。
b) 控制流信息数据包:
TNT数据包:
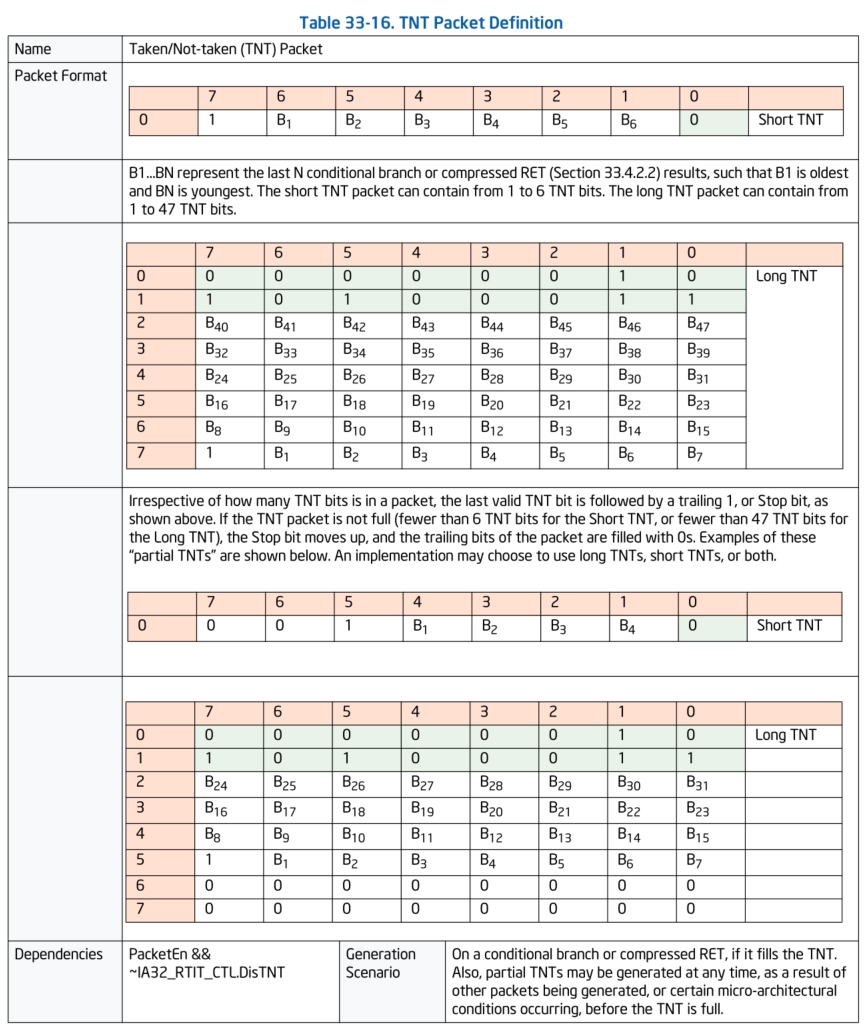
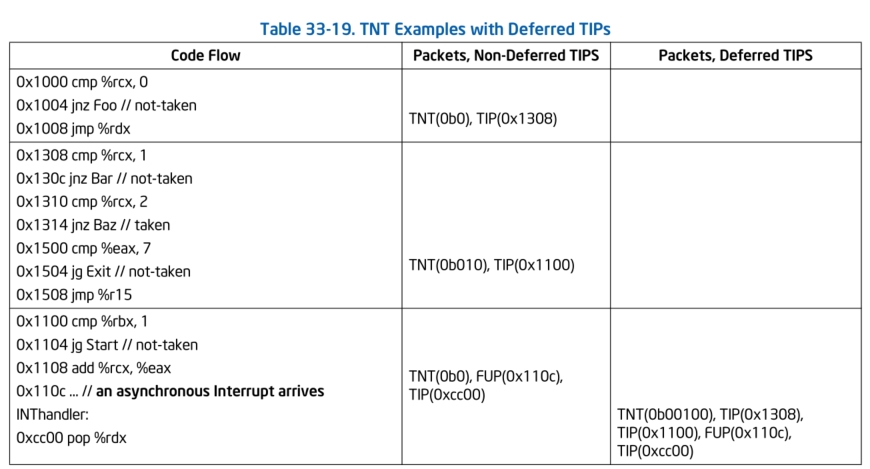
TNT数据包可不是什么炸药,它的全称是:Taken/Not-taken Packet。这个数据包指示着最近的1到6个或者1到47个条件分支是否执行,执行就是taken(用1表示),没执行就是not-taken(用0表示),其中的B1到Bn代表着最后N个条件分支的结果,B1代表最旧的分支结果,Bn代表最新的,不过这里有一个特殊的地方是,如果开启了ret压缩,也会增加一个已经置1的taken位到TNT数据包中。
TNT数据包分两种长度的,一种是1字节版本的,可以代表最多6个的分支跳转结果。一种是8字节版本的,最多可以代表47个分支跳转的结果。
TIP数据包:
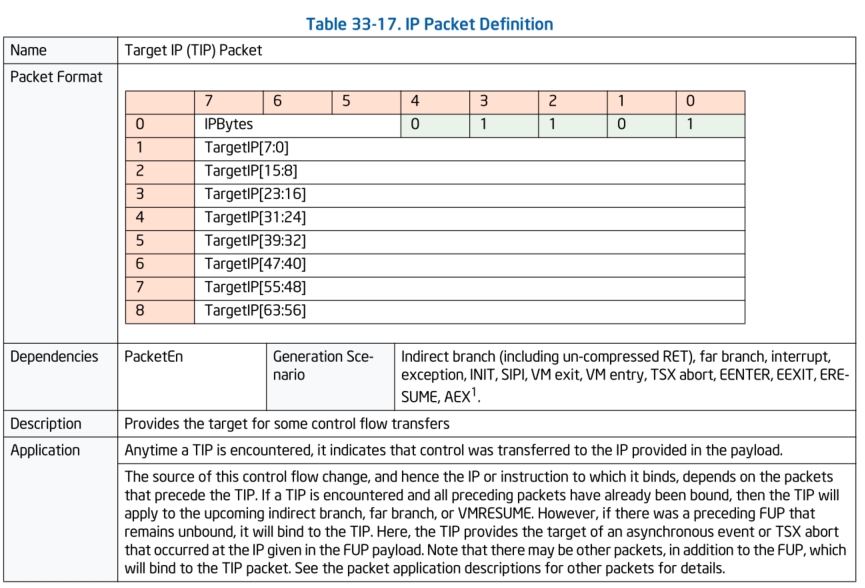
TIP数据包就是Target IP数据包,顾名思义,在Intel PT开启跟踪时遇到例如:没有开启ret压缩的ret指令,间接跳转指令(例如JMP rax),中断,异常,VMEntry/VMExit等等指令时会产生一个TIP数据包记录当前的执行流IP跑到了哪里。
TIP.PGE & TIP.PGD数据包:
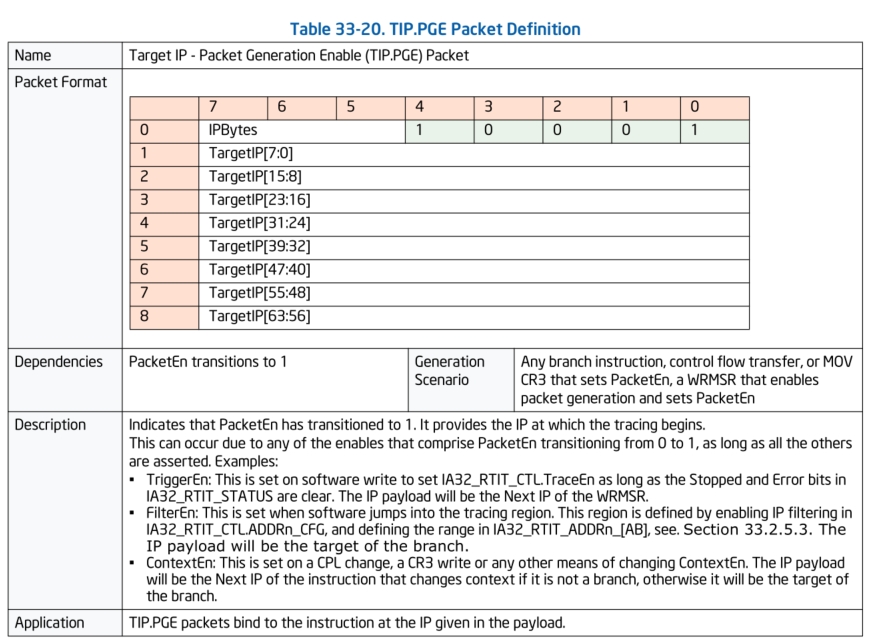
TIP.PGE数据包是Target IP - Packet Generation Enable (TIP.PGE) Packet。当例如变更了CR3寄存器的值,或者代码流跳转到跟踪区域时,便会生成该数据包。例如我们在跟踪驱动时,设置好了跟踪的代码地址范围,当代码流跳转到了需要跟踪的区域中,便会生成该数据包。
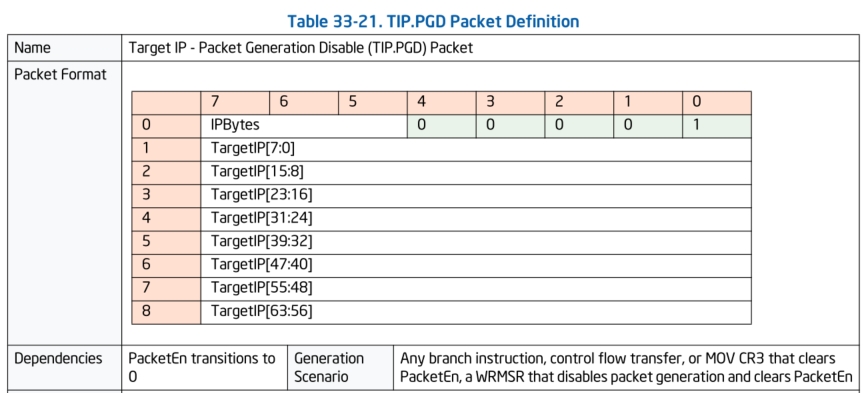
TIP.PGD数据包是Target IP - Packet Generation Disable (TIP.PGD) Packet。当例如变更了CR3寄存器的值,或者CPU代码流离开了跟踪地址范围时,这个数据包便会生成。
FUP数据包:
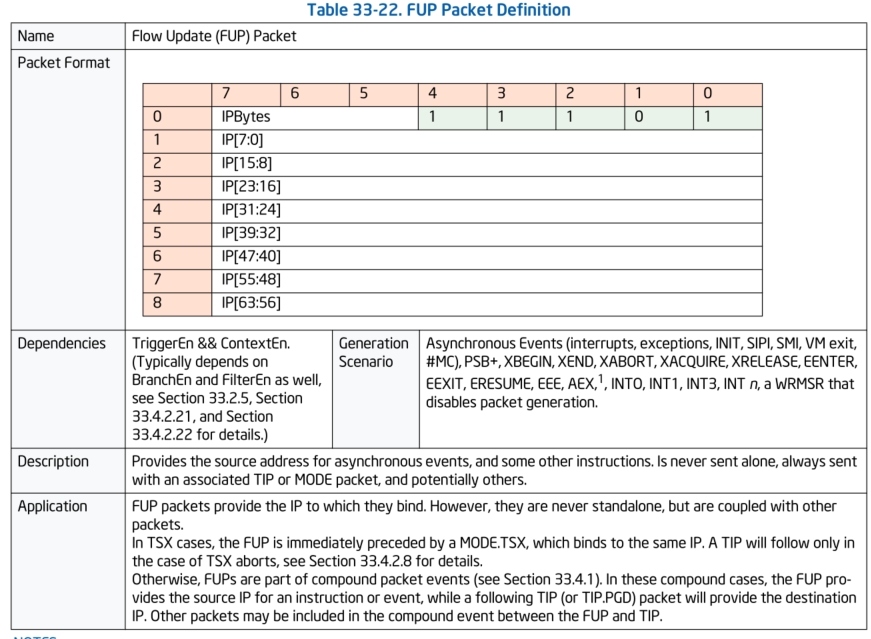
FUP数据包是FLow Update Packet,在开启PT跟踪时遇到例如系统中断(INT0, INT1, INT2 ,INT3,INT n)等,会产生FUP数据包,FUP数据包记录的是当前发生异步事件时的源IP,而往往在FUP之后会生成一个TIP数据包会记录目标IP。
MODE.Exec数据包:
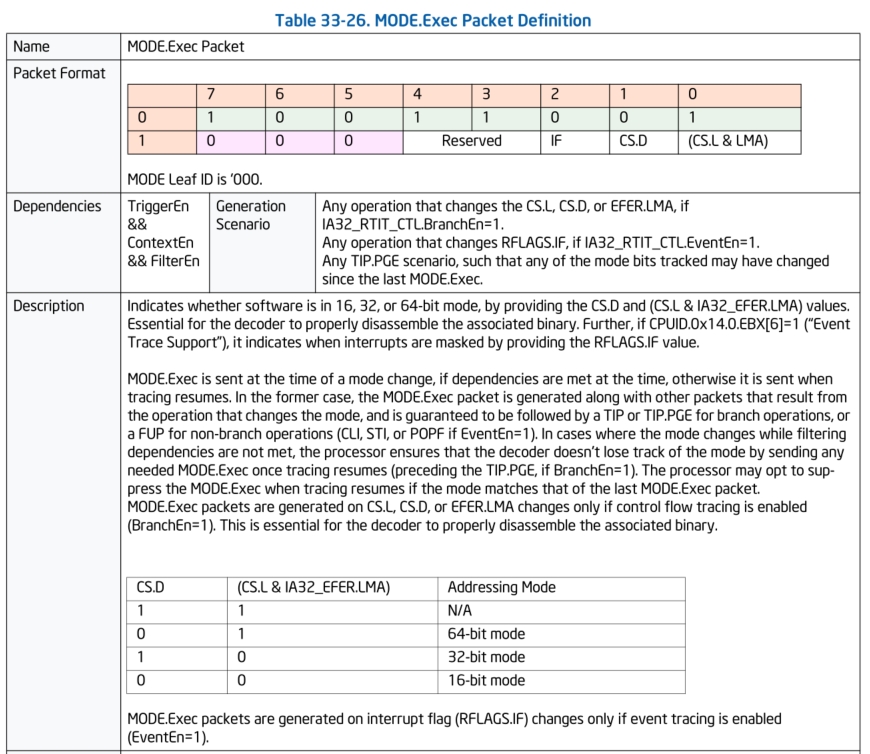
Mode Exec数据包用来指示当前处理器运行在16,32,还是64位模式下。
这里还要讲一下FUP TIP数据包的IP压缩问题
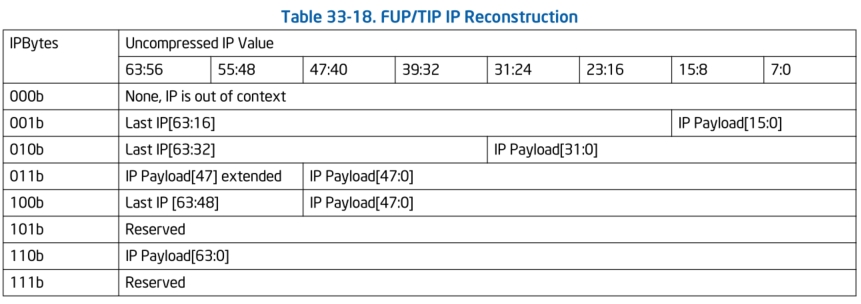
Intel在设计PT时考虑到了在CPU内部硬件记录IP信息时可能面临着数据量大造成的带宽消耗问题,所以在设计上使用了IP负载压缩功能。在我们上面介绍的TIP数据包、FUP数据包的格式中,都会发现有一个叫做IPBytes的字段,这个字段是用来表示TIP、FUP数据包中的IP负载使用了多少bytes的内存空间,但是比较反直觉的是:IPBytes这个字段并不是通过直接读取数值代表当前TIP、FUP数据包中IP字段的大小。而是通过上图中IPBytes代表的魔数确定当前的IP负载处于什么样的压缩状态下。
举个例子:假如我们有个一个TIP.PGE数据包,它的二进制raw data是:
71 10 93 38 85 06 f8 00 00
根据之前我们介绍的TIP.PGE数据包格式,0x71(0b0111 0001),其中低5bits是TIP.PGE的头部,那么代表IPBytes的数据为:0b011。
根据查阅上面IP重构的表中可知,此时IP负载的压缩情况为:IP Payload的0到47位为正常数据,47位到63位为第47位的值,那么我们重新构建此时RIP的值便是0xFFFF F806 8538 9310。
以及返回地址压缩问题: 除了对IP进行压缩以外,Intel PT还可以对返回地址进行压缩,但是ret指令的压缩不同于IP压缩。ret指令IP负载压缩会面临两种情况,如果开启了ret压缩的话,ret指令的行为有时候会被看作是一个一定taken的分支跳转指令,也就是说,在开启了ret压缩的情况下,有时候ret指令的执行并不会生成TIP数据包,而是在TNT数据包增加一个taken的位,标志着当前的ret指令按照预期的地址进行了返回,看起来更像是一个一直会执行的条件分支跳转指令。那么既然说到了"按照预期",那么必须由解码器维护一个call/ret堆栈,那么如果ret地址到了一个非预期的地址上时,那么便会生成一个TIP数据包记录这个非预期的地址。
由于ret压缩是一个可选功能,并且在分析二进制跟踪数据时不够直观,还需要在解码器中维护一个call/ret堆栈,所以这里建议在控制寄存器中关闭这个ret压缩功能。
好了,一些比较常用且重要的数据包已经介绍完了,对其他数据包格式感兴趣的可以去阅读Intel用户手册卷3第33章节。下面我们来通过例子学习一个这些数据包的作用。
例子:
四、如何配置与使用Intel PT
想要配置和启用Intel PT首先需要确定当前我们使用的CPU是否支持该功能,首先,得有一块Intel的CPU,其次,最好选择6代以后的CPU,像是本文使用的CPU就是Skylake架构的奔腾处理器。
然后,通过CPUID指令查询当前CPU的属性可以查询是否支持Intel PT。通过查询Intel用户手册我们得知,在使用CPUID指令时eax=0x07,ecx=0x00会查询到拓展特性子叶。如下图:

在内核调试中:
WindowsPtDriver!CheckIntelPtSupport+0x44:
fffff806`a90c5af4 0fa2 cpuid
1: kd> r rax
rax=0000000000000007
1: kd> r rcx
rcx=0000000000000000
1: kd> r rbx
rbx=ffffd4087d7aa000
1: kd> p
WindowsPtDriver!CheckIntelPtSupport+0x46:
fffff806`a90c5af6 488d7c2440 lea rdi,[rsp+40h]
1: kd> r rbx
rbx=0000000002942607
1: kd> ?@rbx&0x2000000
Evaluate expression: 33554432 = 00000000`02000000
通过调试可以看出,当前的CPU是支持Intel PT特性的。
现在我们便可以通过IA32_RTIT_*寄存器来配置和开启Intel PT功能了,IA32_RTIT_*寄存器家族主要有如下几个:
IA32_RTIT_OUTPUT_BASE: 0x560
IA32_RTIT_OUTPUT_MASK_PTRS: 0x561
IA32_RTIT_CTL: 0x570
IA32_RTIT_STATUS: 0x571
IA32_RTIT_CR3_MATCH: 0x572
IA32_RTIT_ADDR0_A: 0x580
IA32_RTIT_ADDR0_B: 0x581
IA32_RTIT_ADDR1_A: 0x582
IA32_RTIT_ADDR1_B: 0x583
IA32_RTIT_ADDR2_A: 0x584
IA32_RTIT_ADDR2_B: 0x585
IA32_RTIT_ADDR3_A: 0x586
IA32_RTIT_ADDR3_B: 0x587
IA32_RTIT_CTL寄存器,顾名思义就是控制Intel PT功能的寄存器,在Intel文档中被如下定义:
bits | Bit Name | 描述
0 | TraceEn | 1代表开启Intel PT跟踪;0代表关闭
1 | CYCEn | 1代表启用CYC数据包;0代表关闭
2 | OS | 1代表Ring0权限下开启跟踪;0代表关闭
3 | User | 1代表Ring大于0权限开启跟踪;0代表关闭
4 | PwrEvtEn | 1代表电源事件跟踪开启;0代表关闭
5 | FUPonPTW | 1代表PTW数据包后面跟着生成FUP数据包;0代表关闭
6 | FabricEn | 1代表跟踪输出结果输出到跟踪传输子系统中;0代表跟踪输出结果直接输出到内存中
7 | CR3Filter | 1代表开启CR3过滤;0代表关闭CR3过滤
8 | ToPA | 1代表使用ToPA;0代表使用single-range
9 | MTCEn | 1代表生成MTC数据包;0代表禁用生成MTC数据包
10 | TSCEn | 1代表生成TSC数据包;0代表禁用生成TSC数据包
11 | DisRETC | 1代表关闭ret指令压缩;0代表开启ret指令压缩
12 | PTWEn | 1代表PTWRITE指令生成开启;0代表PTWRITE指令生成关闭
13 | BranchEn | 1代表开启生成例如FUP, TIP, TIP.PGE, TIP.PGD, TNT, MODE.Exec, MODE.TSX数据包;0代表关闭
17:14 | MTCFreq | 定义MTC数据包的生成频率
18 | Reserved | 必须为0
22:19 | CycThresh | CYC数据包节流阀
23 | Reserved | 必须为0
27:24 | PSBFreq | PSB数据包生成频率
30:28 | Reserved | 必须为0
31 | EventEn | 1代表开启Event Trace数据包;0代表关闭
35:32 | ADDR0_CFG | 设置IA32_RTIT_ADDR0_A/B寄存器:
| 0代表ADDR0范围未使用
| 1代表IA32_RTIT_ADDR0_A-IA32_RTIT_ADDR0_B地址范围内开启跟踪
| 2代表IA32_RTIT_ADDR0_A-IA32_RTIT_ADDR0_B地址范围内关闭跟踪
39:36 | ADDR1_CFG |
43:40 | ADDR2_CFG |
47:44 | ADDR3_CFG |
54:48 | Reserved | 必须为0
55 | DisTNT | 1代表关闭TNT数据包生成;0代表开启TNT数据包生成
56 | InjectPsbPmiOnEnable
63:57 | Reserved | 必须为0
虽然通过文档知道了IA32_RTIT_CTL寄存器的定义,但是在没有设置好要把跟踪的数据输出的地址前我们是无法正常开启Intel PT的跟踪功能的。所以我们还需要设置好输出跟踪数据流的地址,这里我们要使用 IA32_RTIT_OUTPUT_BASE和IA32_RTIT_OUTPUT_MASK_PTRS MSR寄存器。
IA32_RTIT_OUTPUT_BASE
bits | Bit Name | 描述
6:0 | Reserved | 必须为0
MAXPA-1:7 | BasePhysAddr | 这里就是输出跟踪流数据的物理地址
63:MAXPA | Reserved | 必须为0
关于BasePhysAddr这个字段可以直接填入一段物理地址,此时如果开启了Intel PT便会直接将跟踪数据循环写入这个物理地址。如果我们在IA32_RTIT_CTL.ToPA设置为1,那么这里填入的应该是ToPA表的物理地址。
IA32_RTIT_OUTPUT_MASK_PTRS
bits | Bit Name | 描述
6:0 | LowerMask | 默认都设置为1,其他值忽略
31:7 | MaskOrTableOffset | 这个字段和IA32_RTIT_CTL.ToPA的字段有关:
| 如果为0:为single-range模式,此时跟踪流数据输出
| 到连续的物理内存中。此时这个字段充当mask。
| 假设此时的字段值为0,此时的mask值为0b01111111
| 那么这时的输出最大地址不会超过base+0x7f
| 0x80 = 2^7, 输出buffer大小为128bytes
| 假设此时字段bits全部为1,这时候的mask值为
| 0b01111 1111 1111 1111 1111 1111 1111 1111
| 此时输出数据的最大地址不会超过base+0xffffffff
| 2^32 = 0x100000000,输出buffer大小为4GB
|
| 如果为1:为ToPA模式,这个字段充当TableOffset
| 这个字段的值*0x1000就是ToPA TableOffset
|
63:32 | OutputOffset | 这个字段和IA32_RTIT_CTL.ToPA的字段有关:
| 如果为0:输出buffer的offset,不会超过上面的mask
|
| 如果为1:当前写入的ToPA条目的offset
简单介绍了下IA32_RTIT_OUTPUT_BASE和IA32_RTIT_OUTPUT_MASK_PTRS MSR寄存器,我们下面介绍下如何配置跟踪数据流buffer的两种模式:Single Range Output、ToPA Output。
Single Range Output模式: Single Range模式顾名思义是将跟踪数据流信息直接输出到一个连续的物理内存空间中,这里也可以输出到MMIO中,Single Range的配置非常简单,除了需要配置IA32_RTIT_CTL.ToPA为0,剩下只需要确定好三个东西便可以完成配置。
OutputBase[63:0] := IA32_RTIT_OUTPUT_BASE[63:0] //连续物理内存地址或者MMIO地址
OutputMask[63:0] := ZeroExtend64(IA32_RTIT_OUTPUT_MASK_PTRS[31:0]) //设置好掩码,当所写入的数据大小超过了掩码表达的范围,那么数据将循环从头写入上面设置的OutputBase指向的buffer中
OutputOffset[63:0] := ZeroExtend64(IA32_RTIT_OUTPUT_MASK_PTRS[63:32]) //设置写入buffer时候的偏移
trace_store_phys_addr := (OutputBase & ~OutputMask) + (OutputOffset & OutputMask) //最终计算出当前写入的buffer的地址
在Windows驱动中初始化Single Range Output:
// Use the single range output implementation
rtitCtlDesc.Fields.ToPA = 0; // We use the single-range output scheme
rtitOutBaseDesc.All = (ULONGLONG)pPtBuffDesc->u.Simple.lpTraceBuffPhysAddr;
__writemsr(MSR_IA32_RTIT_OUTPUT_BASE, rtitOutBaseDesc.All);
rtitOutMasksDesc.All = (1 << PAGE_SHIFT) - 1; // 这里设置了mask为0xfff,一个4KB页(0x1000)
__writemsr(MSR_IA32_RTIT_OUTPUT_MASK_PTRS, rtitOutMasksDesc.All);
ToPA Output模式: ToPA全称是Table of Physical Address,顾名思义ToPA就是使用一串表来表示跟踪数据流要写入的物理地址。ToPA的设置相比于Single Range Output来说要复杂一些,但是ToPA方式进行输出可以增大输出的大小,并且可以在buffer全满时设置一个性能LVT(Local Vector Table)中断用作通知驱动将跟踪数据读取处理,这个步骤实现了异步处理跟踪数据。在使用ToPA输出模式时,需要将IA32_RTIT_CTL.ToPA配置为1,并且需要设置如下变量:
proc_trace_table_base:当前ToPA表的基址,由IA32_RTIT_OUTPUT_BASE寄存器设置
proc_trace_table_offset:指向当前正在使用的表的入口,它的值为IA32_RTIT_OUTPUT_MASK_PRS.MaskOrTableOffset<<3。也就是说proc_trace_table_offset是4K对齐的。
proc_trace_output_offset:代表当前输出区域的偏移,它的值为IA32_RTIT_OUTPUT_MASK_PTRS.OutputOffset
虽然介绍了ToPA模式的细节,但是对这个ToPA概念还是很抽象,下面我们借助一张图片来理解这个ToPA模式。
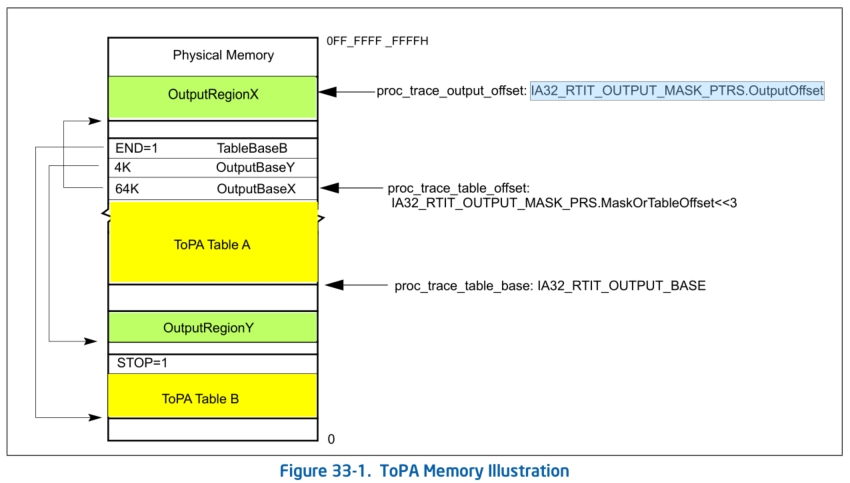
首先,使用ToPA模式时,CPU会从IA32_RTIT_OUTPUT_BASE寄存器中获取到ToPA表的基址,即proc_trace_table_base,然后计算IA32_RTIT_OUTPUT_MASK_PRS.MaskOrTableOffset«3得出proc_trace_table_offset作为当前的ToPA表entry的offset。这里要注意的是,ToPA表中存储的都是ToPA表Entry条目,大小为0x08。现在已知proc_trace_table_base和proc_trace_table_offset,便可以读取当前ToPA表其中一个Entry条目,例如这个条目是OutputBaseX,OutputBaseX中的信息包含了OutputRegionX的物理地址和大小以及一些属性,那么此时CPU跟踪的数据流便会写入这个OutputRegionX为基址的buffer中。这时候还需要获取proc_trace_output_offset,它的值为IA32_RTIT_OUTPUT_MASK_PTRS.OutputOffset,用作在这个OutputRegionX buffer的偏移proc_trace_output_offset处写入数据。
这里还要补充的是ToPA表Entry条目的格式:


那么,假设OutputRegionX这个buffer已经被写满,CPU便会获取下一个ToPA表Entry条目,这个条目指向OutputRegionY。当OutputRegionY也被写满时,这时候CPU获取下一个ToPA表Entry条目时发现遇到了一个END标志,这个标志着当前的ToPA表A已经没有条目,此时原本应该是代表Output Region Base PA的位置现在代表着下一个ToPA表的物理地址。如果按照图中的例子来讲就是最终会指向ToPA Table B,此时proc_trace_table_offset和proc_trace_output_offset都会被重置为0,指向ToPA Table B第0个Entry条目。直到CPU在取下一个Entry条目时候遇到STOP标志,这个标志意味着我们设置的全部数据填充都被写满,这时候CPU会将IA32_RTIT_STATUS.TriggerEn开关清0,关闭Intel PT跟踪。
在Windows驱动中初始化ToPA模式输出:
寄存器配置
// Use Table of Physical Addresses
rtitCtlDesc.Fields.ToPA = 1;
// Set the proc_trace_table_base
rtitOutBaseDesc.All = (ULONGLONG)pPtBuffDesc->u.ToPA.lpTopaPhysAddr;
__writemsr(MSR_IA32_RTIT_OUTPUT_BASE, rtitOutBaseDesc.All);
//这里只使用一个ToPA Table
rtitOutMasksDesc.Fields.LowerMask = 0x7F;
rtitOutMasksDesc.Fields.MaskOrTableOffset = 0; //初始化,table entry从0开始
rtitOutMasksDesc.Fields.OutputOffset = 0; //初始化,offset从0开始
__writemsr(MSR_IA32_RTIT_OUTPUT_MASK_PTRS, rtitOutMasksDesc.All);
ToPA表的初始化
// Allocate and set a ToPA (with the Windows API)
NTSTATUS AllocAndSetTopa(PT_BUFFER_DESCRIPTOR ** lppBuffDesc, QWORD qwReqBuffSize, BOOLEAN bSetPmiAndStop)
{
NTSTATUS ntStatus = STATUS_SUCCESS; // Returned NTSTATUS
DWORD dwNumEntriesInMdl = 0; // Number of entries in the MDL
DWORD dwTopaSize = 0; // Size of the ToPa
TOPA_TABLE_ENTRY * pTopa = NULL; // Pointer to the ToPa
PHYSICAL_ADDRESS highPhysAddr = { (ULONG)-1, -1 }; // Highest physical memory address
PHYSICAL_ADDRESS lowPhysAddr = { 0i64 }; // Lowest physical memory address
PHYSICAL_ADDRESS topaPhysAddr = { 0i64 }; // The ToPA physical address
PMDL pTraceBuffMdl = NULL;
PT_BUFFER_DESCRIPTOR * pBuffDesc = NULL;
ASSERT(KeGetCurrentIrql() <= DISPATCH_LEVEL);
if (qwReqBuffSize % PAGE_SIZE) return STATUS_INVALID_PARAMETER_2;
// Allocate the needed physical memory
pTraceBuffMdl = MmAllocatePagesForMdlEx(lowPhysAddr, highPhysAddr, lowPhysAddr, (SIZE_T)qwReqBuffSize + PAGE_SIZE, MmCached, MM_ALLOCATE_FULLY_REQUIRED);
if (!pTraceBuffMdl) return STATUS_INSUFFICIENT_RESOURCES;
// Get the PFN array
dwNumEntriesInMdl = ADDRESS_AND_SIZE_TO_SPAN_PAGES(MmGetMdlVirtualAddress(pTraceBuffMdl), MmGetMdlByteCount(pTraceBuffMdl));
PPFN_NUMBER pfnArray = MmGetMdlPfnArray(pTraceBuffMdl);
// Allocate the ToPA
dwTopaSize = (dwNumEntriesInMdl + 1) * 8;
dwTopaSize = ROUND_TO_PAGES(dwTopaSize);
pTopa = (TOPA_TABLE_ENTRY *)MmAllocateContiguousMemory(dwTopaSize, highPhysAddr);
topaPhysAddr = MmGetPhysicalAddress(pTopa);
if (!pTopa) {
MmFreePagesFromMdl(pTraceBuffMdl);
ExFreePool(pTraceBuffMdl);
return STATUS_INSUFFICIENT_RESOURCES;
}
RtlZeroMemory(pTopa, dwTopaSize);
// Create the ToPA
for (DWORD i = 0; i < dwNumEntriesInMdl; i++) {
pTopa[i].Fields.BaseAddr = pfnArray[i]; // Pfn array contains the PFN offset, not the actual Physical address
pTopa[i].Fields.Size = 0; // Encoding: 0 - 4K pages
}
// LVT interrupt entry (if any)
if (bSetPmiAndStop) {
pTopa[dwNumEntriesInMdl - 1].Fields.Int = 1;
pTopa[dwNumEntriesInMdl - 1].Fields.Stop = 1;
}
// END entries
RtlZeroMemory(&pTopa[dwNumEntriesInMdl], sizeof(TOPA_TABLE_ENTRY));
pTopa[dwNumEntriesInMdl].Fields.BaseAddr = (ULONG_PTR)(topaPhysAddr.QuadPart >> 0xC);
pTopa[dwNumEntriesInMdl].Fields.End = 1;
// Now create the descriptor and set the ToPA data
if (lppBuffDesc) {
pBuffDesc = (PT_BUFFER_DESCRIPTOR*)ExAllocatePoolWithTag(NonPagedPool, sizeof(PT_BUFFER_DESCRIPTOR), MEMTAG);
RtlZeroMemory(pBuffDesc, sizeof(PT_BUFFER_DESCRIPTOR));
pBuffDesc->bUseTopa = TRUE;
pBuffDesc->u.ToPA.lpTopaPhysAddr = (ULONG_PTR)topaPhysAddr.QuadPart;
pBuffDesc->u.ToPA.lpTopaVa = pTopa;
pBuffDesc->qwBuffSize = qwReqBuffSize;
pBuffDesc->pTraceMdl = pTraceBuffMdl;
pBuffDesc->bDefaultPmiSet = bSetPmiAndStop;
*lppBuffDesc = pBuffDesc;
}
return ntStatus;
}
讲到这里,已经配置好了CPU跟踪数据的输出buffer了,那么下面就要介绍一下Intel PT的过滤机制了。Intel PT的过滤机制主要有3种,一种是基于CPL的过滤,一种是基于CR3寄存器的过滤,另外一种是基于虚拟地址的过滤。
CPL过滤主要依靠IA32_RTIT_CTL.OS和IA32_RTIT_CTL.User这两个字段控制,OS使能为1代表进行Ring0的跟踪,User使能为1代表进行Ring>0的跟踪,如果OS和User同时设置代表不管CPL级别都进行跟踪。
rtitCtlDesc.Fields.Os = (desc.bTraceKernel ? 1 : 0); // Trace Kernel address space
rtitCtlDesc.Fields.User = (desc.bTraceUser ? 1 : 0); // Trace the user mode process
CR3寄存器过滤主要由IA32_RTIT_CR3_MATCH MSR寄存器控制,直接写入一个CR3寄存器的值并且在IA32_RTIT_CTL.CR3Filter设置1便可以启用。
__writemsr(MSR_IA32_RTIT_CR3_MATCH, (ULONGLONG)targetCr3);
rtitCtlDesc.Fields.CR3Filter = 1;
虚拟地址的过滤通过IA32_RTIT_ADDRn_A/IA32_RTIT_ADDRn_B MSR寄存器控制。通过向IA32_RTIT_ADDRn_A/IA32_RTIT_ADDRn_B MSR寄存器写入一个地址范围,并使用IA32_RTIT_CTL.ADDRn_CFG位控制,如果IA32_RTIT_CTL.ADDRn_CFG位为0,那么代表该地址范围不启用,如果为1代表当CPU运行到该地址范围时启用跟踪,如果为2代表当CPU运行到该地址范围内禁用跟踪。
rtitCtlDesc.Fields.Addr0Cfg = 1;
__writemsr(MSR_IA32_RTIT_ADDR0_START, (QWORD)lpProcPtData->IpRanges[0].lpStartVa);
__writemsr(MSR_IA32_RTIT_ADDR0_END, (QWORD)lpProcPtData->IpRanges[0].lpEndVa);
每个CPU支持的最大的虚拟地址过滤组数是不一样的,像我这颗CPU最大支持2组地址过滤。支持最多多少组地址过滤可以通过CPUID.(EAX=0x14, ECX=1)查询
WindowsPtDriver!CheckIntelPtSupport+0x2d6:
fffff806`a9465d86 0fa2 cpuid
2: kd> r rax
rax=0000000000000014
2: kd> r rcx
rcx=0000000000000001
2: kd> p
WindowsPtDriver!CheckIntelPtSupport+0x2d8:
fffff806`a9465d88 488d7c2440 lea rdi,[rsp+40h]
2: kd> r rax
rax=0000000002490002
完成了以上的准备工作,便可以开启Intel PT开始跟踪代码数据流了,在这之前我们先介绍下IA32_RTIT_STATUS寄存器,这个寄存器反映了Intel PT的工作状态。
bits | Bit Name | 描述
0 | FilterEn | 代表当前IP正在被跟踪
1 | ContextEn | 指示当前上下文是否启用跟踪
2 | TriggerEn | 指示正在启用跟踪
3 | Reserved | 0
4 | Error | 错误
5 | Stopped | ToPA遇到STOP位
6 | PendPSB |
7 | PendTopaPMI |
31:8 | Reserved | 0
48:32 | PacketByteCnt | 指示了一共发送了多少bytes的跟踪数据包
63:49 | Reserved | 0
下面通过代码示例来开启Intel PT
// Step 1. Disable all the previous PT flags
rtitCtlDesc.All = __readmsr(MSR_IA32_RTIT_CTL);
rtitCtlDesc.Fields.TraceEn = 0;
__writemsr(MSR_IA32_RTIT_CTL, rtitCtlDesc.All);
// Clear IA32_RTIT_STATUS MSR
rtitStatusDesc.All = __readmsr(MSR_IA32_RTIT_STATUS);
rtitStatusDesc.Fields.Error = 0; // See Intel's manuals, section 36.3.2.1
rtitStatusDesc.Fields.Stopped = 0;
rtitStatusDesc.Fields.ContextEn = 0;
rtitStatusDesc.Fields.PacketByteCnt = 0; // Restore the Byte counter to 0
lpProcPtData->PacketByteCount = 0; // In both values
__writemsr(MSR_IA32_RTIT_STATUS, rtitStatusDesc.All);
// Set the IA32_RTIT_OUTPUT and IA32_RTIT_OUTPUT_MASK_PTRS MSRs
if (pPtBuffDesc->bUseTopa)
{
// Use Table of Physical Addresses
rtitCtlDesc.Fields.ToPA = 1;
// Set the proc_trace_table_base
rtitOutBaseDesc.All = (ULONGLONG)pPtBuffDesc->u.ToPA.lpTopaPhysAddr;
__writemsr(MSR_IA32_RTIT_OUTPUT_BASE, rtitOutBaseDesc.All);
// Set the proc_trace_table_offset: indicates the entry of the current table that is currently in use
rtitOutMasksDesc.Fields.LowerMask = 0x7F;
rtitOutMasksDesc.Fields.MaskOrTableOffset = 0; // Start from the first entry in the table
rtitOutMasksDesc.Fields.OutputOffset = 0; // Start at offset 0
__writemsr(MSR_IA32_RTIT_OUTPUT_MASK_PTRS, rtitOutMasksDesc.All);
}
else
{
// Use the single range output implementation
rtitCtlDesc.Fields.ToPA = 0; // We use the single-range output scheme
rtitOutBaseDesc.All = (ULONGLONG)pPtBuffDesc->u.Simple.lpTraceBuffPhysAddr;
__writemsr(MSR_IA32_RTIT_OUTPUT_BASE, rtitOutBaseDesc.All);
rtitOutMasksDesc.All = (1 << PAGE_SHIFT) - 1; // The physical page always has low 12 bits NULL
__writemsr(MSR_IA32_RTIT_OUTPUT_MASK_PTRS, rtitOutMasksDesc.All);
}
// Set the TRACE options:
TRACE_OPTIONS & options = lpProcPtData->TraceOptions;
rtitCtlDesc.Fields.FabricEn = 0;
rtitCtlDesc.Fields.Os = (desc.bTraceKernel ? 1 : 0); // Trace Kernel address space
rtitCtlDesc.Fields.User = (desc.bTraceUser ? 1 : 0); // Trace the user mode process
rtitCtlDesc.Fields.BranchEn = options.Fields.bTraceBranchPcks;
if (lpProcPtData->lpTargetProcCr3) {
// Set the page table filter for the target process
__writemsr(MSR_IA32_RTIT_CR3_MATCH, (ULONGLONG)targetCr3);
rtitCtlDesc.Fields.CR3Filter = 1;
}
else {
// Set the register to 0
__writemsr(MSR_IA32_RTIT_CR3_MATCH, 0);
rtitCtlDesc.Fields.CR3Filter = 0;
}
// Set the IP range flags and registers to 0
rtitCtlDesc.Fields.Addr0Cfg = 0;
rtitCtlDesc.Fields.Addr1Cfg = 0;
rtitCtlDesc.Fields.Addr2Cfg = 0;
rtitCtlDesc.Fields.Addr3Cfg = 0;
// Now set them to the proper values (see Intel Manuals, chapter 36.2.5.2 - IA32_RTIT_CTL MSR)
if (lpProcPtData->dwNumOfActiveRanges > 0) {
if (lpProcPtData->IpRanges[0].bStopTrace) rtitCtlDesc.Fields.Addr0Cfg = 2;
else rtitCtlDesc.Fields.Addr0Cfg = 1;
__writemsr(MSR_IA32_RTIT_ADDR0_START, (QWORD)lpProcPtData->IpRanges[0].lpStartVa);
__writemsr(MSR_IA32_RTIT_ADDR0_END, (QWORD)lpProcPtData->IpRanges[0].lpEndVa);
}
if (lpProcPtData->dwNumOfActiveRanges > 1) {
if (lpProcPtData->IpRanges[1].bStopTrace) rtitCtlDesc.Fields.Addr1Cfg = 2;
else rtitCtlDesc.Fields.Addr1Cfg = 1;
__writemsr(MSR_IA32_RTIT_ADDR1_START, (QWORD)lpProcPtData->IpRanges[1].lpStartVa);
__writemsr(MSR_IA32_RTIT_ADDR1_END, (QWORD)lpProcPtData->IpRanges[1].lpEndVa);
}
if (lpProcPtData->dwNumOfActiveRanges > 2) {
if (lpProcPtData->IpRanges[2].bStopTrace) rtitCtlDesc.Fields.Addr2Cfg = 2;
else rtitCtlDesc.Fields.Addr2Cfg = 1;
__writemsr(MSR_IA32_RTIT_ADDR2_START, (QWORD)lpProcPtData->IpRanges[2].lpStartVa);
__writemsr(MSR_IA32_RTIT_ADDR2_END, (QWORD)lpProcPtData->IpRanges[2].lpEndVa);
}
if (lpProcPtData->dwNumOfActiveRanges > 3) {
if (lpProcPtData->IpRanges[3].bStopTrace) rtitCtlDesc.Fields.Addr3Cfg = 2;
else rtitCtlDesc.Fields.Addr3Cfg = 1;
__writemsr(MSR_IA32_RTIT_ADDR3_START, (QWORD)lpProcPtData->IpRanges[3].lpStartVa);
__writemsr(MSR_IA32_RTIT_ADDR3_END, (QWORD)lpProcPtData->IpRanges[3].lpEndVa);
}
if (ptCap.bMtcSupport)
{
rtitCtlDesc.Fields.MTCEn = options.Fields.bTraceMtcPcks;
if ((1 << options.Fields.MTCFreq) & ptCap.mtcPeriodBmp)
rtitCtlDesc.Fields.MTCFreq = options.Fields.MTCFreq;
}
if (ptCap.bConfPsbAndCycSupported)
{
rtitCtlDesc.Fields.CycEn = options.Fields.bTraceCycPcks;
if ((1 << options.Fields.CycThresh) & ptCap.cycThresholdBmp)
rtitCtlDesc.Fields.CycThresh = options.Fields.CycThresh;
if ((1 << options.Fields.PSBFreq) & ptCap.psbFreqBmp)
rtitCtlDesc.Fields.PSBFreq = options.Fields.PSBFreq;
}
rtitCtlDesc.Fields.DisRETC = 1; //可以关掉ret压缩
rtitCtlDesc.Fields.TSCEn = options.Fields.bTraceTscPcks;
// Switch the tracing to ON dude :-)
rtitCtlDesc.Fields.TraceEn = 1;
__writemsr(MSR_IA32_RTIT_CTL, rtitCtlDesc.All);
在开启了Intel PT之后,我们可以通过读取MSR_IA32_RTIT_STATUS.TriggerEn来查看是否正常开启了Intel PT。
五、案例分析
下面我们通过一个跟踪后获得的数据来看看Intel PT的实战效果。 下面是跟踪到的log数据:
0x0003e4e7 tip.pge 3: fffff80685389310 SYM > image+0x0000000000009310
0x0003e4f0 tnt.8 . J_NEXT > image+0x000000000000935b
. J_NEXT > image+0x0000000000009368
. J_NEXT > image+0x0000000000009384
. J_NEXT > image+0x0000000000009399
. J_NEXT > image+0x00000000000093a3
. J_NEXT > image+0x00000000000093ae
0x0003e4f1 tnt.8 ! J_NEXT > image+0x00000000000093e8
0x0003e4f2 tip.pgd 0: fffff80685389310
0x0003e4f3 tip.pge 1: fffff806853893fa SYM > image+0x00000000000093fa
0x0003e4f6 tnt.8 . J_NEXT > image+0x0000000000009406
. J_NEXT > image+0x0000000000009465
. J_NEXT > image+0x0000000000011b09
! J_NEXT > image+0x0000000000011b70
. J_NEXT > image+0x0000000000011b92
. J_NEXT > image+0x0000000000011bbd
0x0003e4f7 tnt.8 . J_NEXT > image+0x0000000000011bca
. J_NEXT > image+0x0000000000011bdc
. J_NEXT > image+0x0000000000011be2
0x0003e4f8 tip 1: fffff80685389494 SYM > image+0x0000000000009494
0x0003e4fb tnt.8 . J_NEXT > image+0x00000000000094e0
0x0003e4fc tip.pgd 0: fffff80685389494
0x0003e4fd tip.pge 1: fffff806853894fb SYM > image+0x00000000000094fb
0x0003e500 tnt.8 . J_NEXT > image+0x000000000000950c
首先看的数据包是tip.pge 3: fffff80685389310, 表示我们设置的地址跟踪被触发到了,地址经过解码器是fffff80685389310,转换成符号就是image+0x0000000000009310。这里我们跟踪的是srv2.sys驱动,查看IDA就是:
.text:00000001C0009310 ; __int64 __fastcall Srv2ReceiveHandler(__int64, __int64, __int64, unsigned int, _DWORD *, char *Src, struct _SLIST_ENTRY *, _QWORD *)
.text:00000001C0009310 Srv2ReceiveHandler proc near
然后的数据包就是TNT数据包,解码器解析出了每一次TNT表示位代表的具体地址。如图:
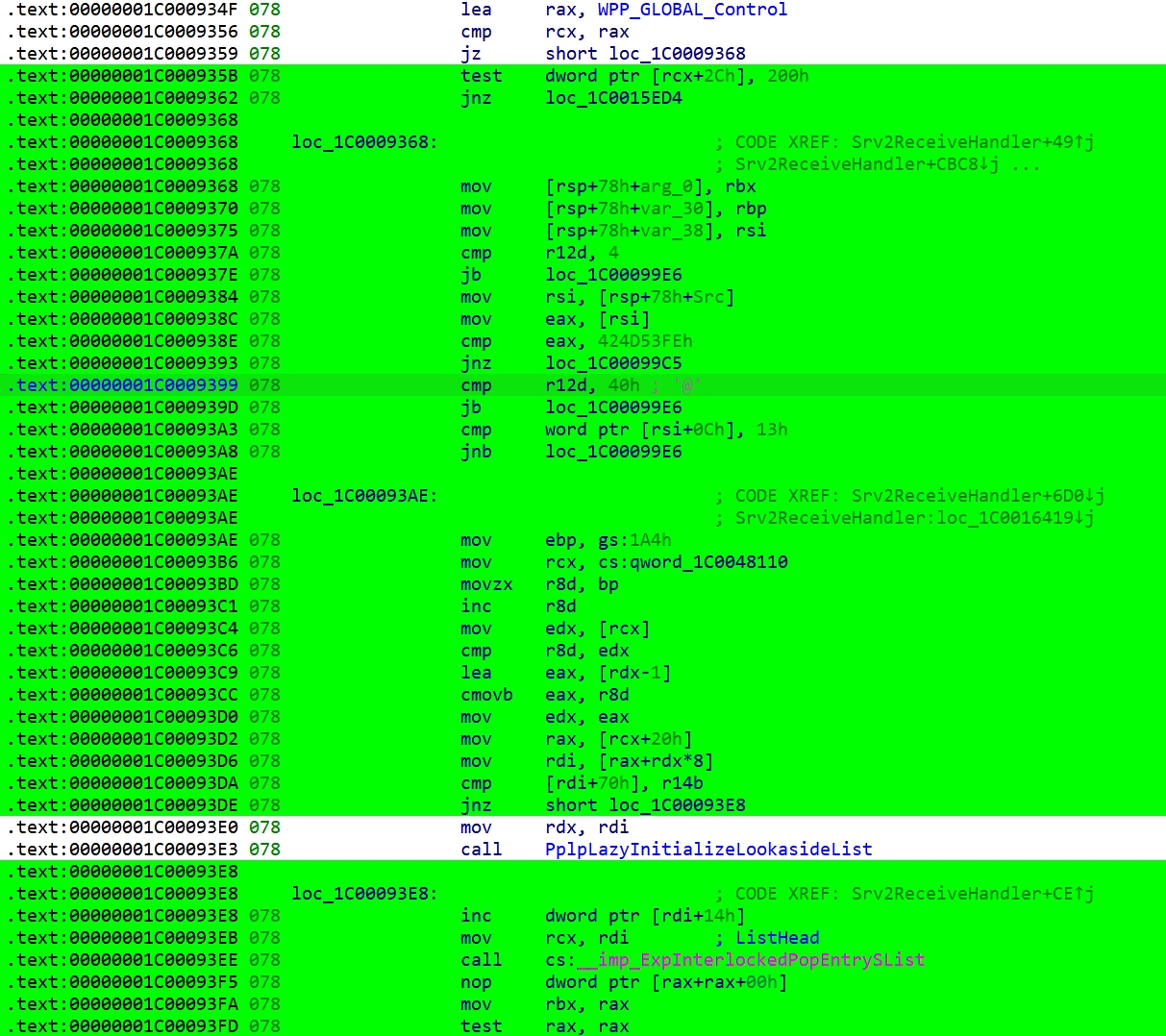
在跟踪数据0x3e4f2处,有一个TIP.PGD,并且IP payload为0,这里通过查看IDA发现是srv2!Srv2ReceiveHandler调用了__imp_ExpInterlockedPopEntrySList这个函数,因为我们设置了CR3过滤,所以这个函数中的数据便不会跟踪,所以生成了一个TIP.PGD数据包。
在这之后紧接着就是TIP.PGE,代表外部函数执行完毕,此时数据包是有payload的,值为image+0x93fa。
在跟踪数据0x0003e4f6处是一个TNT数据包,但是发现到达的分支里的地址突然就超出当前看的函数中。
0x0003e4f6 tnt.8 . J_NEXT > image+0x0000000000009406
. J_NEXT > image+0x0000000000009465
. J_NEXT > image+0x0000000000011b09 //这里
! J_NEXT > image+0x0000000000011b70
. J_NEXT > image+0x0000000000011b92
. J_NEXT > image+0x0000000000011bbd
0x0003e4f7 tnt.8 . J_NEXT > image+0x0000000000011bca
. J_NEXT > image+0x0000000000011bdc
. J_NEXT > image+0x0000000000011be2
0x0003e4f8 tip 1: fffff80685389494 SYM > image+0x0000000000009494
通过查看IDA:
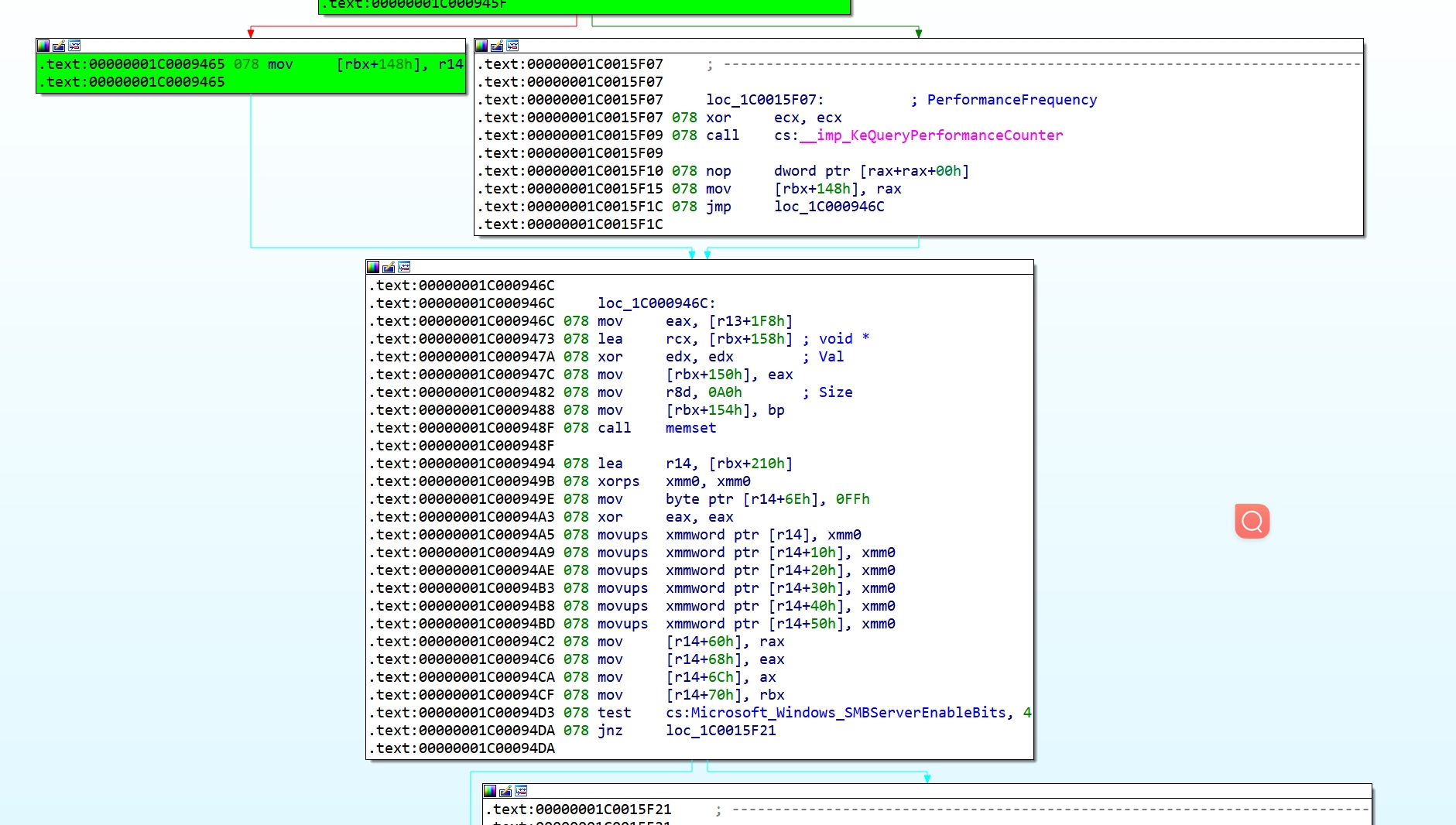
发现srv2!Srv2ReceiveHandler调用了自身的memset函数,TNT分支中的image+0x0000000000011b09就是因为进入了memset函数造成的。当memset函数返回后,因为ret指令会产生一个TIP数据包:tip 1: fffff80685389494 SYM > image+0x0000000000009494,可以看到,就是memset函数之后的地址。
再举个例子:
0x0003e52f tnt.8 . J_NEXT > image+0x0000000000009870
0x0003e530 tip.pgd 2: fffff8065c53556c
在IDA中:
.text:00000001C0009870 078 mov rax, [rsp+78h+arg_20]
.text:00000001C0009878 078 mov [rax], r12d
.text:00000001C000987B 078 xor eax, eax
.text:00000001C000987D
.text:00000001C000987D loc_1C000987D: ; CODE XREF: Srv2ReceiveHandler+5F4↓j
.text:00000001C000987D ; Srv2ReceiveHandler+CD65↓j
.text:00000001C000987D 078 mov rsi, [rsp+78h+var_38]
.text:00000001C0009882 078 mov rbp, [rsp+78h+var_30]
.text:00000001C0009887 078 mov rbx, [rsp+78h+arg_0]
.text:00000001C000988F 078 add rsp, 50h
.text:00000001C0009893 028 pop r15
.text:00000001C0009895 020 pop r14
.text:00000001C0009897 018 pop r13
.text:00000001C0009899 010 pop r12
.text:00000001C000989B 008 pop rdi
.text:00000001C000989C 000 retn
通过IDA可以知道,在执行了00000001C0009870后,函数srv2!Srv2ReceiveHandler要返回,PT发送了一个tip.pgd 2: fffff8065c53556c数据包,可以看到这个TIP.PGD的IP是有Payload的,这个值就是srv2!Srv2ReceiveHandler的返回地址:
srvnet!SrvNetCommonReceiveHandler+0xdc:
fffff806`5c53556c
六、总结与应用
优点:Intel PT运行时的overhead很低,据说只有2%;可以无痛不开刀做到类似于代码插桩的功能;能处理内核态程序
缺点:要使用Intel CPU;所谓的实时跟踪并不是很实时;处理用户态程序方便程度不如直接插桩
应用:Intel PT无法在跟踪时保存寄存器或者内存状态,只是对代码执行流进行了收集,所以对于逆向工作,Intel PT还是有一定的辅助作用。