
一、前言
在软件安全领域,二进制混淆与逆向工程始终处于动态对抗的两端。恶意软件利用混淆技术逃避检测,而安全研究人员则必须突破这些屏障,分析恶意行为或验证程序安全性。本文将从实战角度简述主流混淆技术的实现并给出可能的对抗方案。
二、对抗可执行文件变异
静态分析软件 IDA pro/Ghidra 等,直接以可执行文件 (PE, ELF, …) 作为输入。软件开发者为阻止逆向分析工程师使用相关软件进行分析,可以对编译生成的可执行文件进行变异以干扰静态分析软件加载目标程序, 常见的编译方式有:
- 加壳
- 压缩/加密原始可执行文件,并在运行时解压/解密
- 导入表隐藏
- 如 PE 的 IAT 表用户导入程序需要使用的外部函数,逆向工程师常常借助外部函数符号推断程序功能
- 头文件修改
- 修改如 PE 文件头等加载时必要的数据结构,以阻止静态分析工具加载程序内存DUMP
典型的加壳软件有 UPX,此类软件一般会设法将原始程序A 保存在新构造的程序 B 中,随后 B 在运行时会解压并释放执行原始程序 A,由于原始程序被压缩,静态分析软件无法直接从 B 中开始分析。

对抗此类加壳保护时, 我们有所谓的 “ESP 定律脱壳”:
- 其假设大部分此类壳采用栈的方式保存程序入口点时的CPU上下文,如 x86 下使用 pushad 之类的指令
- 在加壳后的程序完成解压或者解密动作后,其可能会为了模拟原始程序刚进入口点时的上下文效果从栈中恢复先前保存的上下文
- 逆向工程师可以利用硬件访问断点,在开始保存有上下文的栈中地址处设置硬件读断点,如果按预想触发,随后不久就可能看到代码跳转至原始程序的入口点处执行
脱壳的方式主要还是取决于加壳器的做法,有些壳可能只会加密部分代码段,此时他可能利用一些系统API提供的函数来提前在用户代码被执行前完成解密,比如 Windows 下的 TLSCallback,或 C Runtime 提供的init数组等。
二进制加壳使用的主要技术实际上源于静态二进制修改,一般来说你很难对代码段进行修补,会出现很多指令大小,占用空间的问题,所以一般的做法很多都是拷贝代码到另外一处,修补相关偏移等,所以他仍然需要在原始代码区域布置 jmp 等跳转,另外有些加密壳任然会保留原始代码的内存区域,只是将数据加密,所以可以简单通过布置执行断点完成脱壳。

总结来说逆向此类目标应该是利用各种方式接近代码解密完成后,真实程序刚好开始执行的位置,但实际上也不一定需要这么严谨,从分析的角度来看,如果不是需要成功脱壳并将其转化成无壳并可以执行的状态,则无需刻意分析其 OEP 等位置,只要将内存镜像 DUMP 下来后修正其 Header,保证 IDA 能加载分析即可。
DUMP 镜像的修复主要需要考虑的是 Header 的映射字段部分,需要将其Raw Addr调整至符合内存镜像的 Virtual Addr 处。
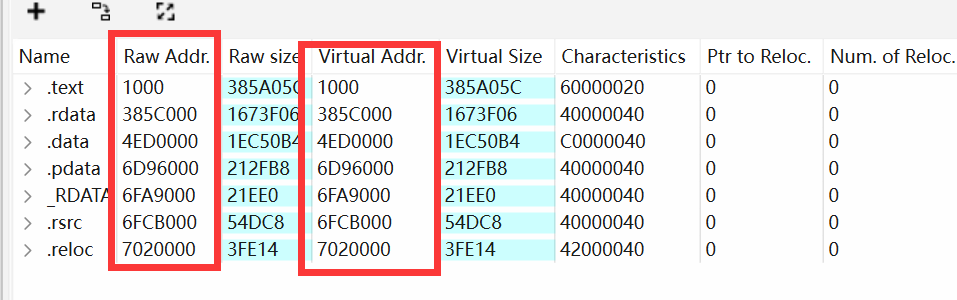
除此之外,目标进程可能在运行时修改 Header 内容,以干扰静态分析软件加载,需要针对情况单独分析。
经过变异的 PE Header 是无法正常被 IDA 正常加载的。
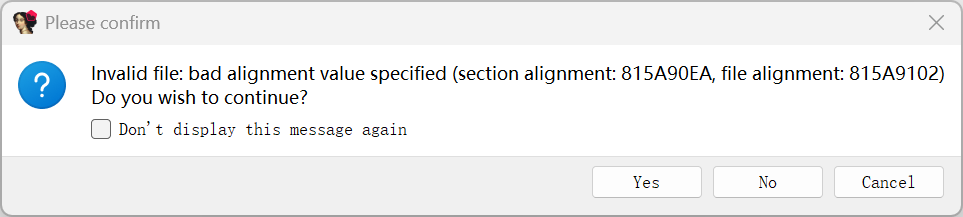
在 PE 结构完成修复后一般就已经可以进行静态分析,但是 Packer 都会手动重定位 IAT 或者包含 IAT 隐藏的功能的壳都会加密导入函数,使静态分析程序无法自动关联这些外部函数到符号。
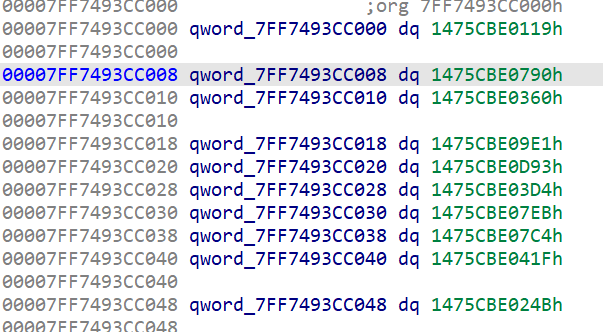
针对此类问题,简单的可以直接利用一些自动扫描 IAT 工具完成修复,但是有些 IAT 保护则会采用一些随机代码片段间接调用系统函数,此时可以通过在导入函数中布置断点,追踪相关的片段代码,利用模拟执行等方式计算实际函数,再用IDA脚本批量恢复固件,总之只要能做到方便我们静态分析的程度即可。
三、对抗 Useless Code
Useless Code 是一种常见的指令级二进制混淆形式,一般有如下形式:
- 花指令,此类指令意图干扰静态分析器的分析行为,比如在 JMP 指令后插入无效的字节,能力较弱的反汇编器使用线性扫描算法很可能在 JMP 后继续识别指令形成混乱的结果
- Deadstore,不影响语义,但占据大量篇幅无意义的代码
现代静态分析软件基本使用的都是递归下降式的扫描分析方法,此种分析方法一般不会受到这种形式简单的花指令影响,只有调试器的动态窗口或者一些编译器套件使用的简单反汇编工具 (如 objdump),可能继续使用这种简单的扫描方法,针对花指令的情况可以人工分析,总结花指令的形式,扫描代码并去除。
Deadstore 则需要数据流分析领域的 Livenesss Analysis,检查赋值后没有被使用的语句都可以被移除掉。

可以借助 Triton 之类的二进制分析框架来实现此类优化算法,Triton 会将指令提升至 SSA 形式的 AST 树,每条指令都会产生数个新的临时变量,如add eax, ebx会形成类似如下形式:

因此借助SSA的形式分析,只需分析新产生的变量在后续指令中是否会被使用,于是首先构建每条指令定义的变量以及使用的变量。
def create_liveness_information(self,inst_flow:list[triton.Instruction]):
optimizer_ctx = self.new_optimizer_triton_ctx()
liveness_infos = []
useful_variables = set()
for inst in inst_flow:
liveness_info = {
"use":set(),
"def":set(),
"inst":None,
}
optimizer_ctx.processing(inst)
for expr in inst.getSymbolicExpressions():
liveness_info["def"].add(expr.getId())
for ref in self.get_ast_refs(expr.getAst()):
liveness_info["use"].add(ref)
liveness_info["inst"] = inst
liveness_infos.append(liveness_info)
for reg in optimizer_ctx.getAllRegisters():
expr = optimizer_ctx.getSymbolicRegister(reg)
if expr != None:
useful_variables.add(expr.getId())
for addr,mem_expr in optimizer_ctx.getSymbolicMemory().items():
useful_variables.add(mem_expr.getId())
return liveness_infos,useful_variables
随后进行反向分析,分析找出无用的指令即可。
def scan_for_deadcode(self,inst_flow:list[triton.Instruction]):
liveness_infos,useful_variables = self.create_liveness_information(inst_flow)
deadcodes = []
for liveness_info in reversed(liveness_infos):
is_deadcode = True
for defed_id in liveness_info["def"]:
if defed_id in useful_variables:
is_deadcode = False
break
if is_deadcode:
if not liveness_info["inst"].isControlFlow():
deadcodes.insert(0,liveness_info["inst"].getAddress())
else:
for used_id in liveness_info["use"]:
useful_variables.add(used_id)
return deadcodes

四、对抗语法语义混淆
此类混淆技术既改变了指令原始的形式,又在一定程度上改变了语义,但是仍能保持预期的行为,常见的有以下三种:
- Opaque Predicate - 不透明谓词
- Control Flow Flattening - 控制流平坦化
- Virtualization - 代码虚拟化
Opaque Predicate (Bogus Control Flow) 指的是在二进制block中插入了一些不可能被执行的跳转,或一定会执行的跳转以用于干扰静态分析软件对CFG的生成。

利用模拟执行,或者符号执行进行判断,如果跳转的目标地址总是相同,则可判定为固定地址跳转。
def test_trace(trace):
Triton.setArchitecture(ARCH.X86)
symbolization_init()
astCtxt = Triton.getAstContext()
for opcode in trace:
instruction = Instruction()
instruction.setOpcode(opcode)
Triton.processing(instruction)
print(instruction.getDisassembly())
if instruction.isBranch():
op_ast = Triton.getPathPredicate()
model = Triton.getModel(astCtxt.lnot(op_ast))
if model:
print("not an opaque predicate")
else:
if instruction.isConditionTaken():
print("opaque predicate: always taken")
else:
print("opaque predicate: never taken")
print('----------------------------------')
return
但是符号执行的也存在弱点,不透明谓词尽量减少性能牺牲以产生干扰效果,但如果对 Useless Code 进行扩展,生成不改变源程序语义的代码,如利用 rdtsc 指令做随机数,对随机数判断跳转,但分支内不产生实际意义,这类CFG则难以精简。
if (random() == XX) {
doUseLessA();
}else {
doUseLessB();
}
Control Flow Flattening - 控制流平坦化,将原始程序正常的控制流展开成类似 switch case 的形式,由某个基本块开始同意分发控制流。

此类混淆同样依赖于分析其块之间的转移关系,随后利用模拟或符号执行批量修改跳转指令, 其主流实现来自于OLLVM,目前互联网上已有较多详细的分析案例和脚本工具不做过多赘述。
Virtualization 代码虚拟化相对与前几种拥有最复杂的表现形式,以 VMP 3.5 的样本为例,局部虚拟化的函数往往以 push xxxxx; call xxxxx; 的形式开始,push 的常量为 virtual engine 的参数,其指向加密后的virtual code 位置:

Virtual Context 则一般保存在栈上:

栈式虚拟机,操作数/操作中间结果保存在Virtual Stack中,同时栈帧层级和原始代码保持一致
- LOW -> HIGH : VCTX -> VSTACK -> REAL\_STACK


指令膨胀程度很高,从初始化到call,原始三条指令,膨胀出上千个间接跳转, 同时包含大量冗余的 Virtual Code 指令,类似在 Virtual Code 上又做了许多常规混淆手法,常量折叠,死代码等等。


对 Virtualization 的代码分析需要涉及以下方面:
- 分析 Virtual Context 创建,原始 CPU Context 保存过程
- 分析当前哪些寄存器用于维护Virtual Context, Virtual SP, Virtual IP
- 分析 VIP 的更新流程
- 分析 Virtual Opcode Handler
目前现有公开的工具 VMHunt,通过插桩的方式,追踪虚拟函数执行流,并通过一些启发式方法以及,符号执行来削减代码的数量级降低分析难度。
对虚拟化代码的分析和前文其他混淆相比其涉及的工作量是最大的,实战中可能最好还是更据需求利用动态调试等方法侧面观察目标程序的行为,如追踪系统调用等。
五、总结
二进制混淆与反混淆的对抗,本质上是安全攻防领域的缩影 —— 一方不断加固防御,另一方持续寻找突破口,随着软件保护需求的增长和恶意软件技术的演进,混淆技术从简单的加壳、导入表隐藏,发展到复杂的控制流平坦化、虚拟化执行,生成更难以分析的代码结构。与此同时,逆向工程领域也在不断创新,从传统的动态调试、内存DUMP,到符号执行、模拟执行和自动化脚本分析,工具链的进步使得部分混淆手段逐渐失效。这场攻防对抗中,没有永恒的胜利者,只有持续的进化。唯有深入理解混淆技术的实现原理,掌握高效的对抗手段,才能在这场无声的战争中占据主动。